インターフェース認証の完全解説:cookie、session、tokenの違いを解析します。
/ 42 分钟阅读
本文最后更新于 1886 天前,文中所述的信息可能已发生改变或更新。
Cookie(クッキー)
皆さんもご存知の通り、HTTPはステートレスなプロトコルであり、ブラウザとサーバーはプロトコル自体ではリクエストのコンテキストを識別することはできません。
そこで、クッキーが登場します。プロトコル自体ではリンクを識別できないので、リクエストヘッダーにコンテキスト情報を手動で持っていくことにしましょう。以下では、クッキーがどのようにして私たちに多巴胺をもたらすのか見ていきましょう 😏
例えば、以前旅行に行ったとき、観光地に到着したら荷物を預ける必要があるかもしれません。荷物を預けた後、スタッフからは荷物を預けた場所が書かれた札を渡されます。帰るときには、この札と書かれている数字を使って荷物を受け取ることができます。
クッキーはまさにこのような役割を果たしています。旅行者はクライアント、荷物預かり所はサーバーで、数字が書かれた札によって荷物預かり所(サーバー)は異なる旅行者(クライアント)を識別することができます。
あなたは、もし札が盗まれたらどうするか考えたことがありますか?クッキーも盗まれる可能性がありますよね?実際にそうです。これは非常によく言及されるネットワークセキュリティの問題であるCSRF(クロスサイトリクエストフォージェリ)です。CSRFの原因と対策については、この記事で詳しく説明されています。
クッキーはもともと、電子商取引でユーザーのショッピングカートなどのデータを保存するために使用されていましたが、現在はフロントエンドには2つのストレージ(ローカル、セッション)と2つのデータベース(WebSQL、IndexedDB)があり、情報の保存には困りません。そのため、ほとんどの場合、クッキーはクライアントの身元を証明するために使用されます。たとえば、ログイン後、サーバーからマークを受け取り、それをクッキーに保存します。その後の接続では、クッキーが自動的に送信されるため、サーバーは誰が誰かを区別することができます。また、クッキーはユーザーを追跡するためにも使用されますが、これにはプライバシーの問題が発生するため、「クッキーの無効化」というオプションもあります(ただし、現代ではクッキーを無効化することはかなり面倒です)。
設定方法
現実世界の例からわかるように、コンピュータ上でクッキーをどのように設定できるのでしょうか?一般的に、セキュリティ上の理由から、クッキーはset-cookieヘッダーを使用して設定されます。リクエストヘッダーで設定されたクッキーは、JavaScriptからの読み書きを許可しないように設定することができます。
ただし、JavaScript自体が自分自身を読み書きすることは可能です。つまり、クッキーはフロントエンドで永続化ストレージとして使用される一つの方法です(ただし、個人的にはあまり必要性を感じません)。例えば、js-cookieライブラリを使用すると、JavaScriptで簡単にクッキーを読み書きすることができます。
さて、HTTPリクエストヘッダーのSet-Cookie属性について、以下にいくつかの使用例を示します:
Set-Cookie: <cookie-name>=<cookie-value>Set-Cookie: <cookie-name>=<cookie-value>; Expires=<date>Set-Cookie: <cookie-name>=<cookie-value>; Max-Age=<non-zero-digit>Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>Set-Cookie: <cookie-name>=<cookie-value>; Path=<path-value>Set-Cookie: <cookie-name>=<cookie-value>; SecureSet-Cookie: <cookie-name>=<cookie-value>; HttpOnly
Set-Cookie: <cookie-name>=<cookie-value>; SameSite=StrictSet-Cookie: <cookie-name>=<cookie-value>; SameSite=LaxSet-Cookie: <cookie-name>=<cookie-value>; SameSite=None; Secure
// 複数の属性も可能です。例えば:Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>; Secure; HttpOnly<cookie-name>=<cookie-value> のようなキーと値のペアは、内容は自由に設定できます。また、HttpOnlyやSameSiteなどの設定もありますが、1つのSet-Cookieには1つのクッキーのみを設定します。
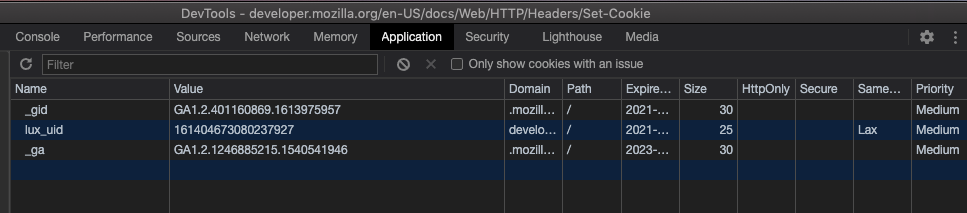
- Expiresはクッキーの有効期限(タイムスタンプ)を設定します。この時間はクライアントの時間です。
- Max-Ageはクッキーの保持期間(秒数)を設定します。ExpiresとMax-Ageの両方が存在する場合、Max-Ageが優先されます。
- Domainは有効なドメインを設定します。デフォルトは現在のドメインで、サブドメインは含まれません。
- Pathは有効なパスを設定します。
/は完全一致です。 - Secureはクッキーをhttpsでのみ送信するように設定します。中間者攻撃を防ぎます。
- HttpOnlyはJavaScriptからのクッキーアクセスを禁止し、XSSを防ぎます。
- SameSiteはクロスサイトリクエスト時にクッキーを送信しないように設定し、CSRFを防ぎます(realMorrisLiuさんの指摘によると、クロスサイトとクロスドメインには微妙な違いがありますが、詳細はこの記事をご覧ください)。
SecureとHttpOnlyは強く推奨されます。SameSiteオプションは、実際の状況に応じて議論する必要があります。なぜなら、SameSiteは、CORSを使用してクロスオリジン問題を解決しても、リクエストにクッキーが含まれていないために一連の問題が発生する可能性があるからです。最初はaxiosの設定の問題だと思っていましたが、それは関係ありませんでした。
実際には、Chromeはある更新後、SameSiteが設定されていないクッキーをデフォルトでLaxとして扱うようになりました。したがって、サーバーでSameSiteをNoneに手動で設定しない限り、クロスオリジンリクエストは自動的にクッキーを送信しません(SameSiteがnoneの場合、Secureは必ずtrueである必要があります)。これらのセキュリティ制御の動作はすべてブラウザの動作であり、モダンブラウザがネットワークセキュリティをサポートするための細かな点です。
送信方法
MDNを参考に、クッキーの送信形式は次のようになります(PHPSESSIDに関連する内容は後述します):
Cookie: <cookie-list>Cookie: name=valueCookie: name=value; name2=value2; name3=value3
Cookie: PHPSESSID=298zf09hf012fh2; csrftoken=u32t4o3tb3gg43; _gat=1クッキーを送信する際には、上記で説明したExpiresなどの設定はサーバーに送信されません。なぜなら、サーバーは設定後にこれらの情報を気にする必要がなく、モダンブラウザが正常に動作していれば、受け取るクッキーには問題がないからです。
セッション
クッキーからセッションに話を移すのは、セッションが本当の「情報」だからです。先述のように、クッキーはコンテナであり、PHPSESSID=298zf09hf012fh2;などが入っています。これがセッションIDです。
セッションとセッションIDを見て、少し頭が混乱しているかもしれませんね。
セッションの存在は、クライアントとサーバーの接続に情報を提供するためです。だから私はセッションを情報と理解し、セッションIDは情報を取得するための鍵であり、通常は一意のハッシュコードです。
次に、2つのNode.js Expressのミドルウェアを分析して、2つのセッションの実装方法を理解しましょう。
セッション情報は、クライアント側に保存することもできます(cookie-sessionなど)、またはサーバー側に保存することもできます(express-sessionなど)。セッションIDを使用することで、セッションをサーバーに保存し、クッキーのIDを使用してサーバーの情報を検索します。
セッション情報をすべてクライアント側に保存し、サーバーが状態を管理しない場合、バックエンドアプリケーションは「ステートレス(状態を持たない)」と言えます。皆さんはおそらく気づいていないかもしれませんが、実際には人気のあるRESTfulアーキテクチャはステートレスを推奨しています。
クライアント側の保存
cookie-sessionライブラリの場合、理解しやすいです。実際には、すべての情報を暗号化してクッキーに詰め込むだけです。これにはcookiesライブラリが関係しています。セッションを設定する際には、実際にはcookies.setを呼び出して、情報をset-cookieに書き込んでからブラウザに返します。つまり、値の取得と設定の本質はすべてクッキーの操作です。
ブラウザはset-cookieヘッダーを受け取ると、情報をクッキーに書き込みます。次回のリクエスト時には、情報はクッキーを通じて元のまま送り返されるため、サーバーは何も保存する必要がありません。サーバーはクッキー内の情報を取得して処理するだけで、この実装方法ではセッションIDは必要ありません。
以下は、cookie-sessionミドルウェアを使用してリクエストにクッキーを追加するコードの例です:
const express = require("express");var cookieSession = require("cookie-session");const app = express();app.use( cookieSession({ name: "session", keys: [ /* secret keys */ "key", ], // Cookie Options maxAge: 24 * 60 * 60 * 1000, // 24 hours }),);app.get("/", function (req, res) { req.session.test = "hey"; res.json({ wow: "crazy", });});
app.listen(3001);app.use(cookieSession())を使用する前に、リクエストはクッキーを設定しません。追加した後にアクセスすると(そしてreq.sessionを設定した後、セッション情報を追加しない場合はクッキーに書き込む必要も内容もありません)、サーバーのレスポンスヘッダーに以下の2行が追加されます。セッションとsession.sigが書き込まれます:
Set-Cookie: session=eyJ0ZXN0IjoiaGV5In0=; path=/; expires=Tue, 23 Feb 2021 01:07:05 GMT; httponlySet-Cookie: session.sig=QBoXofGvnXbVoA8dDmfD-GMMM6E; path=/; expires=Tue, 23 Feb 2021 01:07:05 GMT; httponlyその後、DevToolsのApplicationタブでcookieが正常に書き込まれたことを確認できます。セッションの値eyJ0ZXN0IjoiaGV5In0=は、base64でデコードすることで{"test":"hey"}が得られます(base64についてはこちらを参照してください)。これがいわゆる「クライアントにセッション情報を保存する」ということです。なぜなら、base64エンコードは暗号化ではないため、平文の送信と同じです。そのため、クライアントのセッションにはユーザーのパスワードなどの機密情報を保存しないでください。
現代のブラウザやサーバーは、httpsの使用、クロスドメイン制約、そして前述のcookieのhttponlyとsameSiteの設定など、cookieのセキュリティを保護するためのいくつかの規約を設けています。しかし、考えてみてください。送信のセキュリティは保護されていますが、誰かがあなたのコンピュータのcookieを盗み見ることができ、パスワードがちょうどcookieに存在する場合、パスワードを盗み取られる可能性があります。逆に、他の情報だけを保存するか、単に「ログイン済み」のフラグを証明するだけの場合、一度ログアウトすればそのcookieは無効になり、潜在的な危険性が低くなります。
2番目の値であるsession.sigについて話しましょう。これは27バイトのSHA1署名であり、セッションが改ざんされていないかを検証するためのものであり、cookieのセキュリティをさらに保護します。実際、このアイデアは後で説明するJWTとまったく同じです。
サーバー側の保存
サーバーに保存するためには、express-sessionはストアと呼ばれるコンテナが必要です。これはメモリ、Redis、MongoDBなど、さまざまなものになりますが、メモリはおそらく最も高速ですが、プログラムを再起動するとデータが消えてしまいます。Redisは代替手段として使用できますが、セッションをデータベースに保存するシナリオはあまり一般的ではありません。
express-sessionのソースコードはcookie-sessionほど簡潔ではありませんが、少しややこしい問題があります。req.sessionは実際にはどのように挿入されるのでしょうか?
実装に興味がない場合は、以下の数行をスキップしてください。興味がある場合は、express-sessionのソースコードを追ってみてください:
.session =というキーワードから検索を始めることができます。次のようなものが見つかります:
store.generateはこれを否定します。これは初期化に使用されることがわかります。Store.prototype.createSessionは、reqとsessのパラメータに基づいてreqにsessionプロパティを設定するものです。はい、あなたです。
したがって、createSessionをグローバル検索して、index内のinflate(fillの意味)関数を特定します。
最後に、inflateの呼び出しポイントを見つけるために、sessionIDを引数にしてstore.getのコールバック関数を使用します。すべてがうまくいくでしょう。
クライアントから送信されたcookieを検出した後、cookieからsessionIDを取得し、そのIDを使用してストアからセッション情報を取得し、それをreq.sessionに設定します。このミドルウェアを経由することで、reqのsessionを正常に使用できます。
では、代入はどうなるのでしょうか?これはクライアント側に保存する場合とは異なります。クライアントのcookie情報を変更する必要はありませんが、サーバーに保存されている場合、セッションを変更すると、それは「実際に変更された」ということです。他の派手な方法は必要ありません。メモリ内の情報は変更された情報ですし、次回メモリ内の対応する情報を取得すると変更後の情報になります。(メモリの実装方法に限定されます。データベースを使用する場合は引き続き追加の書き込みが必要です)
セッションIDがない状態でリクエストが来た場合、store.generateを使用して新しいセッションを作成します。セッションを書き込む際には、cookieを変更する必要はありません。元のcookieに基づいてメモリ内のセッション情報にアクセスすれば十分です。
var express = require("express");var parseurl = require("parseurl");var session = require("express-session");
var app = express();app.use( session({ secret: "keyboard cat", resave: false, saveUninitialized: true, }),);
app.use(function (req, res, next) { if (!req.session.views) { req.session.views = {}; }
// get the url pathname var pathname = parseurl(req).pathname;
// count the views req.session.views[pathname] = (req.session.views[pathname] || 0) + 1;
next();});
app.get("/foo", function (req, res, next) { res.json({ session: req.session, });});
app.get("/bar", function (req, res, next) { res.send("you viewed this page " + req.session.views["/bar"] + " times");});
app.listen(3001);2つのストレージ方法の比較
まず、コンピュータの世界で最も重要な哲学的な問題である、時間と空間の選択です。
クライアント側に保存する場合、サーバーのセッションのメモリを解放することができますが、大量のベース64で処理されたセッション情報を毎回送信する必要があります。データ量が多い場合、転送が遅くなる可能性があります。
一方、サーバーに保存する場合、サーバーのメモリを使用して帯域幅を節約します。
また、ログアウトの実装と結果にも違いがあります。
サーバーに保存する場合は非常に簡単で、req.session.isLogin = trueがログインであり、req.session.isLogin = falseがログアウトです。
しかし、クライアント側に状態を保存すると、本当の「即時ログアウト」を実現するのは非常に困難です。セッション情報に有効期限を追加することもできますし、クッキーの有効期限に直接依存することもできます。有効期限が切れたら、ログアウトしたとみなします。
しかし、セッションが期限切れになるのを待たずに、今すぐログアウトしたい場合はどうすればいいですか?真剣に考えてみると、クライアント側に保存されたセッション情報だけでは本当に対応できないことに気付くでしょう。
req.session = nullを使用してクライアントのクッキーを削除しても、削除されるだけであり、誰かが以前にクッキーをコピーしていた場合、セッション情報の有効期限が切れるまで、そのクッキーは有効です。
「即時ログアウト」という表現は少し誇張されていますが、実際にはセッションを即座に無効にすることはできないため、いくつかのリスクが生じる可能性があります。
トークン
セッションについて説明しましたが、非常に頻繁に出てくるキーワードであるトークンは何でしょうか?
「トークン」という言葉でGoogleで検索してみると、いくつか(年配の人には)馴染みのある画像が表示されます:パスワードジェネレーターです。以前のオンラインバンキングでは、短信認証だけで送金できるわけではなく、パスワードジェネレーターを使用する必要がありました。その上には変動するパスワードが表示され、送金する際にはそのコードを入力する必要があります。これがトークンの現実世界の例です。一連のコードまたは数字で自分の身元を証明することは、先ほどの荷物の問題と同じですね…
実際のところ、トークンの機能はセッションIDとまったく同じです。セッションIDをセッショントークンと呼んでも問題ありません(Wikipediaでもこの別名が言及されています)。
違いは、セッションIDは通常クッキーに保存され、自動的に送信されることであるのに対し、トークンは通常リクエストに手動で追加する必要があることです。たとえば、リクエストヘッダーのAuthorizationをbearer:<access_token>に設定することがあります。
ただし、上記の説明は一般的な場合について述べたものであり、実際には明確な規定はありません!
次に紹介するJWT(JSON Web Token)について少しネタバレします!それはトークンです!ただし、セッション情報が含まれています!クライアント側に保存され、クッキーに保存するか、手動でAuthorizationに追加するかは選択できますが、それはトークンです!
だから、個人的には、トークンかセッションIDかを保存場所で判断することはできないと思います。また、内容でトークンかセッション情報かを判断することもできません。セッション、セッションID、トークンはすべて非常に意識的なものです。それが何であり、どのように使用するかを理解していれば、呼び方はあまり重要ではありません。
また、情報を検索する際に、セッションとトークンの違いは新旧の技術の違いだという記事も見かけました。少し理にかなっているようです。
セッションのWikipediaのページのHTTPセッショントークンのセクションでは、JSESSIONID(JSP)、PHPSESSID(PHP)、CGISESSID(CGI)、ASPSESSIONID(ASP)などの伝統的な技術が例示されています。これらはSESSIONIDの代名詞のようなものです。一方、現在のさまざまなプラットフォームのAPIインターフェースやOAuth2.0のログインでは、access tokenなどの用語が使用されており、この違いは非常に興味深いです。
セッションとトークンの関係を理解した後、どこで「生きている」トークンを見ることができるのでしょうか?
GitHubを開き、設定に移動し、Settings / Developer settingsを見つけると、Personal access tokensのオプションが表示されます。新しいトークンを生成した後、それを使用してGitHub APIを介して「あなた自身である」ことを証明できます。
OAuthシステムでもAccess tokenというキーワードが使用されています。WeChatのログインを経験したことがある友人なら、トークンが何を意味するかを感じることができるでしょう。
トークンは権限の証明において本当に重要であり、漏洩してはなりません。トークンを手に入れた者が「オーナー」となります。したがって、トークンシステムを作成するには、トークンのリフレッシュや削除が必要です。これにより、トークンの漏洩をできるだけ早く修正できます。
3つのキーワードと2つのストレージ方法を理解した後、次に「ユーザーログイン」に関連する知識と2つのログイン規格、JWTとOAuth2.0について説明します。
その後、AuthenticationとAuthorizationという2つの単語に頻繁に出会うことになるかもしれません。どちらもAuthで始まる言葉ですが、同じ意味ではありません。簡単に言えば、前者は「認証」であり、後者は「承認」です。ログインシステムを作成する際には、まずユーザーの身元を「認証」し、ログイン状態を設定し、ユーザーにトークンを送信することが「承認」です。
JWT
JSON Web Token(RFC 7519)の略です。そうです、JWTはトークンです。理解を容易にするために、あらかじめお伝えしておきますが、JWTは上記で説明したクライアント側のセッション情報の保存方法を使用していますので、この部分の名称は頻繁に使用されることがあります。
構造
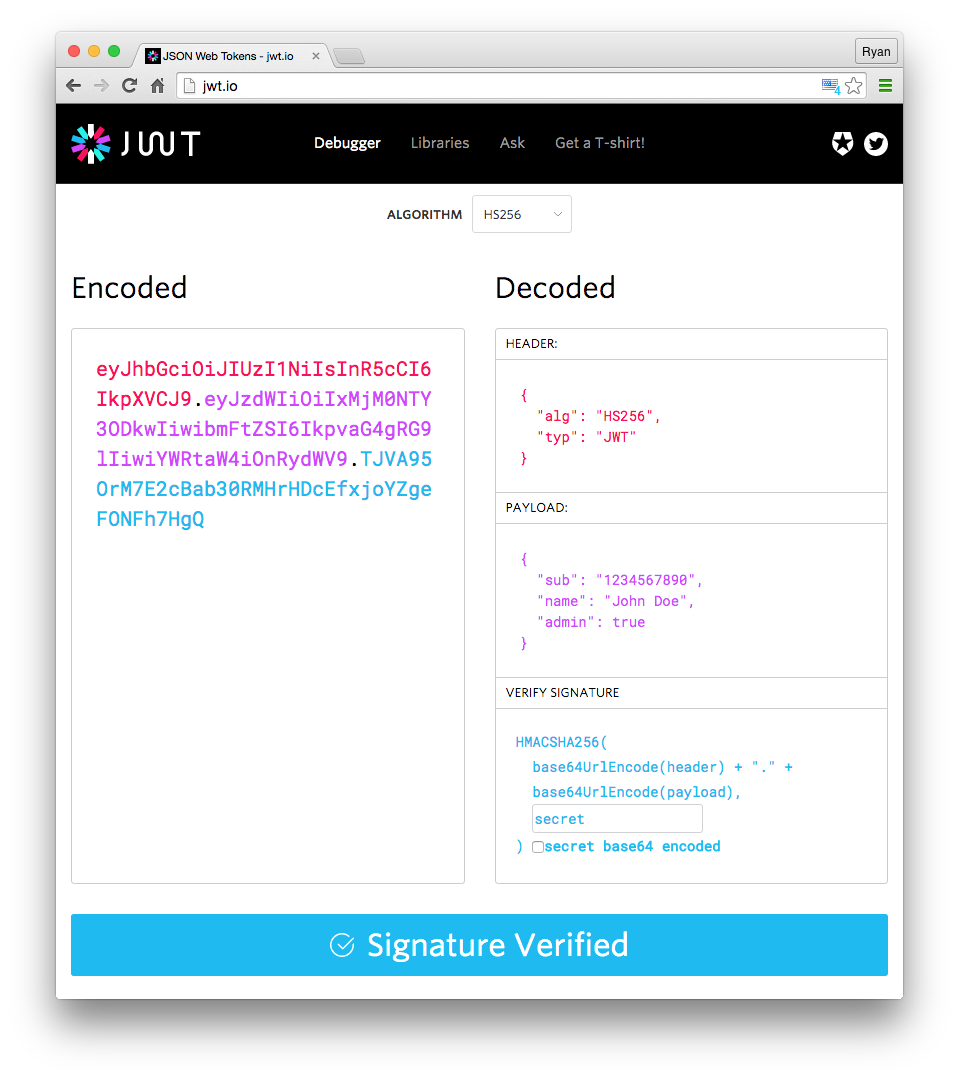
JWTはクライアント側でセッション情報を保存する一種ですが、JWTには独自の構造があります:Header.Payload.Signature(3つの部分に分かれ、.で区切られています)
Header
{ "alg": "HS256", "typ": "JWT"}typはトークンのタイプがJWTであることを示し、algは署名アルゴリズムを表します。HMAC、SHA256、RSAなどです。そして、これらをBase64エンコードします。
Payload
{ "sub": "1234567890", "name": "John Doe", "admin": true}Payloadはセッション情報を配置する場所であり、これらの情報もBase64エンコードする必要があります。結果は、上記のクライアント側のセッション情報とほぼ同じです。
ただし、JWTにはいくつかの規定された属性があり、Registered claimsと呼ばれています。これには、以下が含まれます:
- iss (issuer): 署名者
- exp (expiration time): 有効期限
- sub (subject): 主題
- aud (audience): 受信者
- nbf (Not Before): 有効開始時間
- iat (Issued At): 署名日時
- jti (JWT ID): 識別子
署名
最後の部分は署名であり、先ほどの session.sig と同様に改ざんを防ぐために使用されますが、JWTでは署名とコンテンツが組み合わされています。
JWTの署名生成アルゴリズムは次のようになります:
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)ヘッダーのalgフィールドで指定されたアルゴリズムと、自分で設定した秘密鍵secretを使用して、base64UrlEncode(header) + "." + base64UrlEncode(payload)をエンコードします。
最後に、3つの部分を . で結合します。JWTの構成原理は、jwt.io Debuggerを使用して直感的に確認することができます:
使用方法
ユーザーの認証が成功した後、JWTがユーザーに返されます。JWTの情報は暗号化されていないため、パスワードなどの機密情報は含めないでください。詳細な理由については、クライアント側のcookieに関する説明を参照してください。
ユーザーが認証が必要なリンクにアクセスする場合、トークンをcookieに入れるか、リクエストヘッダーに Authorization: Bearer <token> を含めることができます。(手動でリクエストヘッダーに入れる場合は、CORSの制限を受けず、CSRFの心配もありません)
JWTはクライアント側に情報が保存されるため、自分自身を無効化することはできないという問題があります。これはJWTの欠点と言えます。
P.S. JWTはシングルサインオン(SSO)によく使用されますが、私自身はこれら2つの間に特別な関係があるかはよくわかりません。
HTTP認証
HTTP認証は、クッキーやセッションに関連する技術を使用しない、標準化された認証方法です。リクエストヘッダーに Authorization: Basic <credentials> 形式の認証フィールドを含めます。
ここで、credentialsはBase64エンコードされたユーザー名 + : + パスワード(またはトークン)です。Basic認証を見た場合は、毎回のリクエストでユーザー名とパスワードを含める必要があることを意識してください。
Basic認証は、サーバーレス環境に適していると言えます。なぜなら、実行中のメモリがないためセッションを記録することができず、認証情報を毎回送信するだけで済むからです。
OAuth 2.0
OAuth 2.0(RFC 6749)は、トークンベースの認証プロトコルであり、限定された範囲内で他社のAPIを使用したり、他社のログインシステムを使用して自社アプリケーションにログインしたりすることができます。これはサードパーティアプリケーションのログインを指します。(注意してください、OAuth 2.0の認証フローは面接で問われるかもしれません!)
サードパーティログインの場合、アプリケーション自体以外にもサードパーティログインサーバーが存在する必要があります。OAuth 2.0では、ユーザー、アプリケーションプロバイダー、ログインプラットフォームの3つの役割が関与します。
+--------+ +---------------+ | |--(A)- 認可リクエスト ->| リソース | | | | オーナー | | |<-(B)-- 認可許可 ---| | | | +---------------+ | | | | +---------------+ | |--(C)-- 認可許可 -->| 認可 | | クライアント | | サーバー | | |<-(D)----- アクセストークン -------| | | | +---------------+ | | | | +---------------+ | |--(E)----- アクセストークン ------>| リソース | | | | サーバー | | |<-(F)--- 保護されたリソース ---| | +--------+ +---------------+多くの大企業はOAuth 2.0のサードパーティログインを提供していますが、ここでは小聾哥のWeChatを例にとります。
準備
一般的に、アプリケーションプロバイダーは、ログインプラットフォームでAppIDとAppSecretを事前に申請する必要があります。(WeChatはこの名前を使用していますが、他のプラットフォームでもほぼ同じです。IDとシークレットの2つが必要です)
コードの取得
認可一時チケット(コード)とは何ですか? 答え:サードパーティは、
access_tokenを取得するためにコードを使用する際に必要です。コードの有効期限は10分であり、1つのコードは1回のみaccess_tokenと交換できます。コードの一時性はWeChatの認可ログインのセキュリティを保証しています。サードパーティは、httpsとstateパラメータを使用して、自身の認可ログインのセキュリティをさらに強化することができます。
このステップでは、ユーザーがまずログインプラットフォームで身元の検証を行います。
https://open.weixin.qq.com/connect/qrconnect?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=SCOPE&state=STATE#wechat_redirect| パラメーター | 必須 | 説明 |
|---|---|---|
| appid | はい | アプリの一意の識別子 |
| redirect_uri | はい | リンクを urlEncode して処理してください |
| response_type | はい | code を入力してください |
| scope | はい | アプリの認可スコープです。複数のスコープを持つ場合はカンマ(,)で区切ります。ウェブアプリケーションでは、現在は snsapi_login のみを入力してください |
| state | いいえ | リクエストとコールバックの状態を保持するために使用されます。認可リクエスト後、そのままサードパーティーに返されます。このパラメーターは、CSRF(クロスサイトリクエストフォージェリ)攻撃を防止するために使用できます |
注意:scope は OAuth2.0 の権限制御の特徴であり、このコードを交換するトークンがどのインターフェースで使用できるかを定義します。
パラメーターを正しく設定した後、このページを開くと認可ページが表示されます。ユーザーが認可に成功した後、ログインプラットフォームは code を持ってアプリ提供元が指定した redirect_uri にリダイレクトします:
redirect_uri?code=CODE&state=STATE認可が失敗した場合、次のようにリダイレクトされます:
redirect_uri?state=STATEつまり、失敗した場合は code がありません。
トークンの取得
リダイレクト URI に移動した後、アプリ提供元のバックエンドは、微信から受け取ったcodeを使用してトークンを取得する必要があります。同時に、返された state を使用してソースの検証も行うことができます。
トークンを取得するには、正しいパラメーターを使用して次のエンドポイントにアクセスします:
https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code| パラメーター | 必須 | 説明 |
|---|---|---|
| appid | はい | アプリの一意の識別子。微信オープンプラットフォームでアプリを提出し、承認された後に取得します |
| secret | はい | アプリの秘密鍵 AppSecret。微信オープンプラットフォームでアプリを提出し、承認された後に取得します |
| code | はい | 最初のステップで取得した code パラメーターを入力してください |
| grant_type | はい | authorization_code を入力してください。これは認可モードの一種であり、現在は微信がサポートしている唯一のモードです |
正しいレスポンス:
{ "access_token": "ACCESS_TOKEN", "expires_in": 7200, "refresh_token": "REFRESH_TOKEN", "openid": "OPENID", "scope": "SCOPE", "unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL"}トークンを取得したら、以前に申請したスコープに基づいてAPIを呼び出すことができます。
トークンを使用してWeChat APIを呼び出す
| スコープ(scope) | APIのエンドポイント | APIの説明 |
|---|---|---|
| snsapi_base | /sns/oauth2/access_token | codeを使用してaccess_token、refresh_token、および承認されたスコープを取得する |
| snsapi_base | /sns/oauth2/refresh_token | access_tokenを更新または延長する |
| snsapi_base | /sns/auth | access_tokenの有効性を確認する |
| snsapi_userinfo | /sns/userinfo | ユーザーの個人情報を取得する |
例えば、個人情報を取得するには、GET https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN というようになります。
注意してください、WeChat OAuth 2.0では、access_tokenはクエリパラメータで渡されます。先ほど言ったAuthorizationとは異なります。
Authorizationを使用する例として、GitHubの認証があります。手順は基本的に同じで、トークンを取得した後、次のようにAPIをリクエストします:
curl -H "Authorization: token OAUTH-TOKEN" https://api.github.comWeChatのuserinfoエンドポイントに戻ると、返されるデータの形式は次のようになります:
{ "openid": "OPENID", "nickname": "NICKNAME", "sex": 1, "province":"PROVINCE", "city":"CITY", "country":"COUNTRY", "headimgurl":"https://thirdwx.qlogo.cn/mmopen/g3MonUZtNHkdmzicIlibx6iaFqAc56vxLSUfpb6n5WKSYVY0ChQKkiaJSgQ1dZuTOgvLLrhJbERQQ4eMsv84eavHiaiceqxibJxCfHe/46", "privilege":[ "PRIVILEGE1" "PRIVILEGE2" ], "unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL"}その後の利用
トークンを使用してユーザーの個人情報を取得した後、userinfoエンドポイントから返されたopenidを使用して、セッション技術と組み合わせて自分のサーバーでログインを実現することができます。
// ログインreq.session.id = openid;if (req.session.id) { // ログイン済み} else { // 未ログイン}// ログアウトreq.session.id = null;// セッションのクリアOAuth2.0のプロセスと重要なポイントをまとめると:
- アプリケーションのためにIDとSecretを申請する
- リダイレクトエンドポイントを準備する
- 正しいパラメータを渡してcodeを取得する <- 重要
- 取得したcodeをリダイレクトエンドポイントに渡す
- リダイレクトエンドポイントでcodeを使用してトークンを取得する <- 重要
- 取得したトークンを使用してウェブサービスにアクセスする
OAuth2.0は、サードパーティのログインとアクセス制限に重点を置いています。また、OAuth2.0はWeChatが使用している認証方式だけでなく、他の方式については阮一峰先生のOAuth 2.0の4つの方式を参照してください。
その他の方法
JWTとOAuth2.0は、認証の方法として体系化されていますが、ログインシステムが必ずしも複雑である必要はありません。
単純なログインシステムは、上記の2つのセッションストレージ方法を基にして実装することができます。
-
サーバー側のセッションストレージを使用する場合、
req.session.isLogin = trueのような方法でセッションの状態をログイン済みとしてマークします。 -
クライアント側のセッションストレージを使用する場合、セッションの有効期限とログインユーザーを設定するだけで基本的に使用できます。
{ "exp": 1614088104313, "usr": "admin"}(基本的にはJWTの原理と同じですが、体系はありません)
- また、上記の知識を使用して、自分でExpressのログインシステムを作成することもできます:
- ストアを初期化します。メモリ、Redis、データベースなどが使用できます。
- ユーザーの認証に成功した後、トークンとしてランダムなハッシュコードを生成します。
- set-cookieを使用してクライアントに書き込みます。
- サーバーにログイン状態を書き込むために、ストアにハッシュコードをプロパティとして追加します(メモリの場合)。
- 次回のリクエストでは、cookieを持ってきた場合、cookieに含まれるトークンがすでにストアに書き込まれているかどうかを確認します。
let store = {};
// ログイン成功後store[HASH] = true;cookie.set("token", HASH);
// 認証が必要なリクエストconst hash = cookie.get("token");if (store[hash]) { // ログイン済み} else { // 未ログイン}
// ログアウトconst hash = cookie.get("token");delete store[hash];まとめ
以下に本文の重点を示します:
- cookieはセッション/セッションID/トークンを保存するためのコンテナです。
- cookieの設定は通常、
set-cookieリクエストヘッダーを使用して行われます。 - セッション情報はブラウザに保存することもサーバーに保存することもできます。
- サーバーにセッションを保存する場合、セッションIDを使用して情報を取得します。
- トークン/セッション/セッションIDの境界は曖昧です。
- 一般的に、新しい技術ではトークンを使用し、伝統的な技術ではセッションIDを使用します。
- cookie/トークン/セッション/セッションIDは、認証に使用される実用的な技術です。
- JWTはブラウザにセッションを保存する方法の一つです。
- OAuth2.0のトークンは、アプリケーション側が発行するのではなく、別の認証サーバーに存在します。
- OAuth2.0は、サードパーティアプリケーションのログインによく使用されます。