Explicación completa de la autenticación de interfaces entre el frontend y el backend: diferencias entre cookies, sesiones y tokens.
/ 25 分钟阅读
本文最后更新于 1886 天前,文中所述的信息可能已发生改变或更新。
Cookie
Como todos sabemos, HTTP es un protocolo sin estado, lo que significa que el navegador y el servidor no pueden distinguir el contexto de una solicitud solo con la implementación del protocolo.
Aquí es donde entra en juego la cookie. Si el protocolo en sí no puede distinguir las conexiones, entonces llevemos manualmente la información de contexto en la cabecera de la solicitud. Veamos cómo las galletas nos brindan dopamina 😏
Por ejemplo, cuando solíamos ir de viaje, a veces necesitábamos dejar nuestro equipaje en un lugar seguro. Después de dejar el equipaje, el personal nos daba un número o una tarjeta que indicaba en qué casillero se encontraba nuestro equipaje. Cuando nos íbamos, podíamos recuperar nuestro equipaje presentando esa tarjeta o número.
Esto es exactamente lo que hace una cookie. Los pasajeros son como los clientes, el lugar de almacenamiento es como el servidor, y con el número o la tarjeta, el lugar de almacenamiento (servidor) puede distinguir entre diferentes pasajeros (clientes).
Seguro que te preguntas, ¿qué pasa si alguien roba la tarjeta? ¿Las cookies también pueden ser robadas? Sí, es posible. Este es un problema de seguridad en línea muy común conocido como CSRF. Puedes obtener más información sobre las causas y las formas de combatir el CSRF en este artículo.
Inicialmente, las cookies se crearon para almacenar datos como el carrito de compras de un usuario en el comercio electrónico. Sin embargo, en la actualidad, los navegadores tienen dos tipos de almacenamiento (local y de sesión) y dos tipos de bases de datos (WebSQL e IndexedDB), por lo que no hay problemas para almacenar información. Por lo tanto, en la mayoría de los casos, las cookies se utilizan para verificar la identidad del cliente en una conexión. Por ejemplo, después de iniciar sesión, el servidor te proporciona un identificador que se almacena en una cookie. Luego, cada vez que te conectas, la cookie se envía automáticamente junto con la solicitud, y el servidor puede identificarte. Además, las cookies también se pueden utilizar para rastrear a un usuario, lo que plantea problemas de privacidad. Por eso existe la opción de “desactivar las cookies” (aunque en la actualidad desactivar las cookies puede ser complicado).
Configuración
Ahora que entendemos cómo funcionan las cookies en el mundo real, ¿cómo podemos configurar una cookie en una computadora? Por lo general, por razones de seguridad, las cookies se configuran utilizando la cabecera Set-Cookie, y las cookies configuradas mediante la cabecera de la solicitud se pueden configurar para que JavaScript no pueda leerlas ni escribirlas.
Sin embargo, JavaScript puede leer y escribir cookies por sí mismo, lo que significa que las cookies se pueden utilizar como una forma de almacenamiento persistente en el lado del cliente (aunque personalmente no creo que sea necesario). Por ejemplo, la biblioteca js-cookie te permite leer y escribir cookies fácilmente utilizando JavaScript.
Volviendo a la propiedad Set-Cookie de la cabecera de la solicitud HTTP, aquí tienes algunos ejemplos de cómo se utiliza:
Set-Cookie: <cookie-name>=<cookie-value>Set-Cookie: <cookie-name>=<cookie-value>; Expires=<date>Set-Cookie: <cookie-name>=<cookie-value>; Max-Age=<non-zero-digit>Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>Set-Cookie: <cookie-name>=<cookie-value>; Path=<path-value>Set-Cookie: <cookie-name>=<cookie-value>; SecureSet-Cookie: <cookie-name>=<cookie-value>; HttpOnly
Set-Cookie: <cookie-name>=<cookie-value>; SameSite=StrictSet-Cookie: <cookie-name>=<cookie-value>; SameSite=LaxSet-Cookie: <cookie-name>=<cookie-value>; SameSite=None; Secure
// También es posible tener múltiples atributos, por ejemplo:Set-Cookie: <nombre-cookie>=<valor-cookie>; Dominio=<valor-dominio>; Seguro; HttpOnlyDonde <nombre-cookie>=<valor-cookie> es un par de clave-valor, el contenido puede ser personalizado, y también se pueden configurar opciones como HttpOnly y SameSite. Cada instrucción Set-Cookie configura una sola cookie.
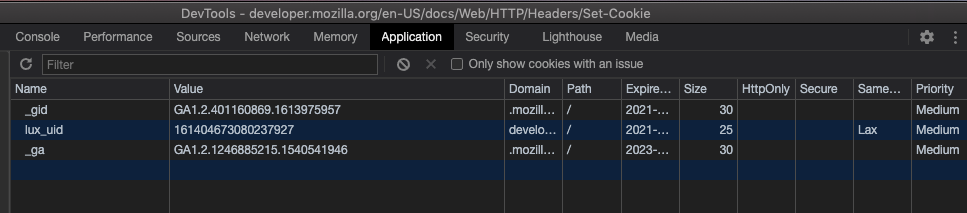
- Expires establece la fecha de expiración de la cookie (marca de tiempo), esta fecha es en hora del cliente.
- Max-Age establece la duración de retención de la cookie (en segundos), si Expires y Max-Age están presentes, Max-Age tiene prioridad.
- Domain establece el dominio en el que la cookie es válida, por defecto es el dominio actual y no incluye subdominios.
- Path establece la ruta en la que la cookie es válida,
/hace que sea válida en todo el sitio. - Secure hace que la cookie solo se envíe a través de HTTPS, para evitar ataques de intermediarios.
- HttpOnly impide que JavaScript acceda a la cookie, para evitar XSS.
- SameSite evita que la cookie se envíe en solicitudes de sitios cruzados, para prevenir CSRF (aunque realMorrisLiu señala que hay una pequeña diferencia entre sitios cruzados y dominios cruzados, puedes obtener más detalles en este artículo).
Se recomienda encarecidamente habilitar Secure y HttpOnly. La opción SameSite debe ser discutida según el caso, ya que puede causar problemas si se usa CORS para solucionar problemas de acceso a recursos de origen cruzado, ya que las solicitudes no llevarán automáticamente la cookie. Al principio pensé que era un problema de configuración de axios, pero en realidad no tenía nada que ver.
En realidad, debido a una actualización de Chrome, las cookies que no tienen SameSite configurado se establecen automáticamente como Lax. Por lo tanto, si no configuras manualmente SameSite como None en el servidor, las solicitudes de origen cruzado no llevarán automáticamente la cookie (también debes tener en cuenta que cuando SameSite es none, Secure debe ser true). Estos comportamientos de seguridad son implementados por los navegadores modernos para proteger tu red.
Método de envío
Según MDN, el formato de envío de las cookies es el siguiente (más adelante se hablará sobre el contenido relacionado con PHPSESSID):
Cookie: <lista-de-cookies>Cookie: nombre=valorCookie: nombre=valor; nombre2=valor2; nombre3=valor3
Cookie: PHPSESSID=298zf09hf012fh2; csrftoken=u32t4o3tb3gg43; _gat=1Al enviar las cookies, no es necesario enviar las configuraciones mencionadas anteriormente, como Expires, ya que una vez configuradas, el servidor no necesita preocuparse por esa información. Si el navegador moderno funciona correctamente, las cookies recibidas no tendrán problemas.
Sesión
Hablando de cookies, llegamos a la sesión, ya que la sesión es la verdadera “información”. Como se mencionó anteriormente, la cookie es un contenedor que contiene PHPSESSID=298zf09hf012fh2;, que es un ID de sesión.
¿Te sientes un poco confundido con la sesión y el ID de sesión?
La sesión existe para proporcionar información a la conexión entre el cliente y el servidor, por lo que yo entiendo la sesión como información, y el ID de sesión es la clave para acceder a esa información, generalmente es un código hash único.
A continuación, analizaremos dos middlewares de Express en Node.js para comprender las dos formas de implementar sesiones.
La información de la sesión puede almacenarse en el cliente, como en cookie-session, o en el servidor, como en express-session. El uso de la ID de sesión implica almacenar la sesión en el servidor y utilizar el ID de la cookie para buscar la información en el servidor.
Cuando decimos que toda la información de la sesión se almacena en el cliente y el servidor no gestiona el estado, podemos decir que la aplicación backend es “stateless” o sin estado. Quizás no lo hayas notado, pero de hecho, la arquitectura RESTful popular aboga por la falta de estado.
Almacenamiento en el cliente
En el caso de la biblioteca cookie-session, es bastante fácil de entender, ya que básicamente se cifra toda la información y se guarda en una cookie. Esto implica el uso de la biblioteca cookies. Al configurar la sesión, simplemente se llama a cookies.set para escribir la información en la cabecera “set-cookie” y luego se devuelve al navegador. En otras palabras, tanto la obtención como la asignación de valores se realizan mediante la manipulación de cookies.
Una vez que el navegador recibe la cabecera “set-cookie”, guarda la información en la cookie. En la siguiente solicitud, la información se envía de vuelta tal como estaba en la cookie, por lo que el servidor no necesita almacenar nada, solo se encarga de obtener y procesar la información de la cookie. Este método de implementación no requiere una ID de sesión.
Aquí tienes un fragmento de código que utiliza el middleware cookie-session para agregar una cookie a la solicitud:
const express = require("express");var cookieSession = require("cookie-session");const app = express();app.use( cookieSession({ name: "session", keys: [ /* secret keys */ "key", ], // Cookie Options maxAge: 24 * 60 * 60 * 1000, // 24 hours }),);app.get("/", function (req, res) { req.session.test = "hey"; res.json({ wow: "crazy", });});
app.listen(3001);Antes de utilizar el middleware app.use(cookieSession()), la solicitud no establecerá ninguna cookie. Después de agregarlo y realizar una solicitud (y si no se agrega información de sesión después de configurar req.session, no hay necesidad ni contenido para escribir en la cookie), se puede ver que la respuesta del servidor incluye las siguientes dos líneas en la cabecera, que escriben la sesión y la sesión.sig:
Set-Cookie: session=eyJ0ZXN0IjoiaGV5In0=; path=/; expires=Tue, 23 Feb 2021 01:07:05 GMT; httponlySet-Cookie: session.sig=QBoXofGvnXbVoA8dDmfD-GMMM6E; path=/; expires=Tue, 23 Feb 2021 01:07:05 GMT; httponlyLuego podrás ver en la pestaña de Application de DevTools que la cookie se ha escrito correctamente. El valor de la sesión eyJ0ZXN0IjoiaGV5In0= se puede obtener decodificando en base64 (si no conoces base64, puedes ver aquí) y obtendrás {"test":"hey"}, esto es lo que se llama “colocar la información de la sesión en el cliente”, ya que la codificación en base64 no es encriptación, es como enviar información en texto plano, así que no coloques información confidencial como contraseñas de usuario en la sesión del cliente.
Aunque los navegadores modernos y los servidores han establecido algunas convenciones, como el uso de HTTPS, restricciones de origen cruzado, y las configuraciones de httponly y sameSite de las cookies mencionadas anteriormente, para garantizar la seguridad de las cookies. Pero piensa en esto, si alguien logra ver las cookies en tu computadora y resulta que la contraseña está almacenada en una cookie, podrían robarla sin que te des cuenta. Por otro lado, si solo colocas otra información o simplemente un indicador de “sesión iniciada”, una vez que cierres la sesión, esa cookie se invalidará, lo que reduce el riesgo potencial.
Volviendo al segundo valor, session.sig, es una firma SHA1 de 27 bytes que se utiliza para verificar si la sesión ha sido modificada, es otra capa de seguridad para las cookies. De hecho, esta idea es exactamente la misma que se menciona más adelante con JWT.
Almacenamiento en el servidor
Dado que se debe almacenar en el servidor, express-session necesita un contenedor llamado store, que puede ser en memoria, redis, mongoDB, etc. La memoria debería ser la más rápida, pero si reinicias el programa, se perderá toda la información. Redis puede ser una opción de respaldo, pero no parece haber muchos casos de uso en los que se almacene la sesión en una base de datos.
El código fuente de express-session no es tan claro y conciso como cookie-session, hay un problema un poco complicado en él, ¿cómo se inserta req.session?
Si no te interesa la implementación, puedes saltarte las siguientes líneas, pero si estás interesado, puedes seguir la lógica en el código fuente de express-session:
Podemos comenzar buscando la palabra clave .session =, encontramos:
store.generatelo descartamos, es fácil ver que esto se usa para la inicialización.Store.prototype.createSessionesto establece la propiedad de sesión enreqsegún los parámetrosreqysess, sí, eres tú.
Entonces, buscamos globalmente createSession y encontramos la función inflate (que significa llenar) en el archivo index.
Finalmente, buscamos los puntos de llamada de inflate, que es la función de devolución de llamada de store.get que utiliza el ID de sesión como parámetro, todo tiene sentido ahora:
Después de detectar la cookie enviada por el cliente, puedes obtener el ID de sesión de la cookie y luego usar ese ID para obtener la información de la sesión en el store y asignarla a req.session. Después de pasar por este middleware, podrás usar la sesión en req sin problemas.
¿Y qué pasa con la asignación? Es diferente a almacenar en el cliente, arriba teníamos que modificar la información de la cookie en el cliente, pero en el caso de almacenar en el servidor, si modificas la sesión, eso significa que la has “modificado de verdad”, no necesitas otros métodos complicados, la información en la memoria se ha modificado y la próxima vez que obtengas la información correspondiente de la memoria, será la información modificada. (Solo se aplica a la implementación en memoria, aún se requiere escritura adicional al usar una base de datos)
En el caso de una solicitud sin ID de sesión, se crea una nueva sesión utilizando store.generate. Cuando escribas en la sesión, la cookie no necesita cambiar, solo necesitas acceder a la información de la sesión en la memoria según la cookie original.
var express = require("express");var parseurl = require("parseurl");var session = require("express-session");
var app = express();app.use( session({ secret: "keyboard cat", resave: false, saveUninitialized: true, }),);
app.use(function (req, res, next) { if (!req.session.views) { req.session.views = {}; }
// obtener la ruta de la URL var pathname = parseurl(req).pathname;
// contar las vistas req.session.views[pathname] = (req.session.views[pathname] || 0) + 1;
next();});
app.get("/foo", function (req, res, next) { res.json({ session: req.session, });});
app.get("/bar", function (req, res, next) { res.send("has visto esta página " + req.session.views["/bar"] + " veces");});
app.listen(3001);Comparación de dos métodos de almacenamiento
Primero, vamos a abordar la cuestión filosófica más importante en el mundo de la informática: la elección entre tiempo y espacio.
En el caso de almacenamiento en el cliente, se libera la memoria del servidor utilizada para almacenar las sesiones, pero cada vez se envía una gran cantidad de información de sesión procesada en base64, lo que puede ralentizar la transmisión si hay una gran cantidad de datos.
Por otro lado, el almacenamiento en el servidor utiliza la memoria del servidor para ahorrar ancho de banda.
Además, hay diferencias en la implementación y los resultados al cerrar la sesión.
En el caso del almacenamiento en el servidor, es bastante sencillo: si req.session.isLogin = true significa que el usuario ha iniciado sesión, mientras que req.session.isLogin = false significa que ha cerrado sesión.
Sin embargo, es difícil lograr un “cierre de sesión inmediato” cuando el estado se almacena en el cliente. Puedes agregar una fecha de vencimiento a la información de sesión o confiar en la fecha de vencimiento de la cookie. Después de que expire, se considerará que el usuario ha cerrado sesión.
Pero, ¿qué pasa si no quieres esperar a que la sesión expire y quieres cerrar sesión de inmediato? Si lo piensas detenidamente, te darás cuenta de que realmente no es posible hacerlo solo con la información de sesión almacenada en el cliente.
Incluso si eliminas la cookie del cliente con req.session = null, solo la estás eliminando en ese momento. Sin embargo, si alguien ha copiado la cookie, esa cookie seguirá siendo válida hasta que expire el tiempo de vencimiento de la información de sesión.
Decir “cierre de sesión inmediato” puede parecer un poco exagerado, pero lo que quiero decir es que no puedes invalidar una sesión de inmediato, lo que puede plantear algunos riesgos.
Token
Ahora que hemos hablado de las sesiones, ¿qué es ese término tan común llamado token?
Si buscas “token” en Google, verás algunas imágenes (las personas mayores estarán más familiarizadas) de un dispositivo: un generador de contraseñas. Antes, para realizar una transferencia bancaria en línea, no solo necesitabas autenticación por mensaje de texto, sino que también tenías que usar un generador de contraseñas que mostraba una contraseña en constante cambio. Para realizar una transferencia, debías ingresar el código del generador de contraseñas. Este es un ejemplo del mundo real de un token. Es una forma de demostrar tu identidad con un código o un número, ¿no es similar al problema del equipaje que mencionamos anteriormente?
En realidad, la función del token es esencialmente la misma que la del ID de sesión. No hay problema en llamar al ID de sesión “token de sesión” (Wikipedia incluso menciona este alias).
La diferencia radica en que el ID de sesión generalmente se almacena en una cookie y se envía automáticamente, mientras que el token generalmente debe incluirse activamente en la solicitud, por ejemplo, estableciendo el encabezado de la solicitud Authorization como bearer:<access_token>.
Sin embargo, todo lo mencionado anteriormente son casos generales y, en realidad, no hay una regla clara al respecto.
¡Aquí viene el spoiler! ¡Vamos a hablar sobre JWT (JSON Web Token)! ¡Es un token! ¡Pero contiene información de sesión! Se almacena en el cliente y puedes elegir entre almacenarlo en una cookie o agregarlo manualmente en el encabezado de autorización. ¡Pero se llama token!
Por lo tanto, personalmente creo que no se puede determinar si es un token o un ID de sesión basándose en la ubicación de almacenamiento, ni se puede determinar si es un token o información de sesión basándose en el contenido. La sesión, el ID de sesión y el token son cosas muy abstractas, siempre y cuando entiendas qué son y cómo se utilizan, no importa cómo los llames.
Además, al buscar información, también he visto algunos artículos que dicen que la diferencia entre la sesión y el token es la diferencia entre las tecnologías antiguas y nuevas, lo cual parece tener sentido.
En la página de Wikipedia sobre la sesión (enlace), en la sección del token de sesión HTTP, los ejemplos son JSESSIONID (JSP), PHPSESSID (PHP), CGISESSID (CGI), ASPSESSIONID (ASP) y otras tecnologías más tradicionales, como si SESSIONID fuera su sinónimo. Por otro lado, al investigar las API y el inicio de sesión OAuth2.0 en diversas plataformas actuales, se utiliza el término “access token”, lo cual es realmente interesante.
Después de comprender la relación entre la sesión y el token, ¿dónde se puede ver un token “vivo”?
Abre GitHub, ve a Configuración y encuentra Configuración del desarrollador. Ahí podrás ver la opción de “Personal access tokens”. Después de generar un nuevo token, puedes usarlo a través de la API de GitHub para demostrar que “eres tú”.
En el sistema de OAuth, también se utiliza la palabra clave “Access token”. Aquellos que hayan implementado el inicio de sesión de WeChat deberían entender qué es un token.
El token es realmente importante para la autenticación, no debe ser revelado. Quien tenga el token es el “propietario”. Por lo tanto, es necesario tener un sistema de tokens en el que sea necesario actualizar o eliminar el token para solucionar rápidamente el problema de la divulgación del token.
Después de comprender las tres palabras clave y los dos métodos de almacenamiento, ahora vamos a hablar oficialmente sobre el conocimiento relacionado con el “inicio de sesión de usuario” y los dos estándares de inicio de sesión: JWT y OAuth2.0.
Luego, es posible que veas con frecuencia las palabras “Authentication” y “Authorization”, ambas comienzan con “Auth”, pero no tienen el mismo significado. En pocas palabras, el primero es “verificación” y el segundo es “autorización”. Al desarrollar un sistema de inicio de sesión, primero debes verificar la identidad del usuario, establecer el estado de inicio de sesión y otorgar un token al usuario, lo cual es la “autorización”.
JWT
JWT, cuyo nombre completo es JSON Web Token (RFC 7519), sí, JWT es un token. Para facilitar la comprensión, les diré de antemano que JWT utiliza el método de almacenamiento en el cliente mencionado anteriormente, por lo que es posible que se utilicen con frecuencia los nombres mencionados anteriormente.
Estructura
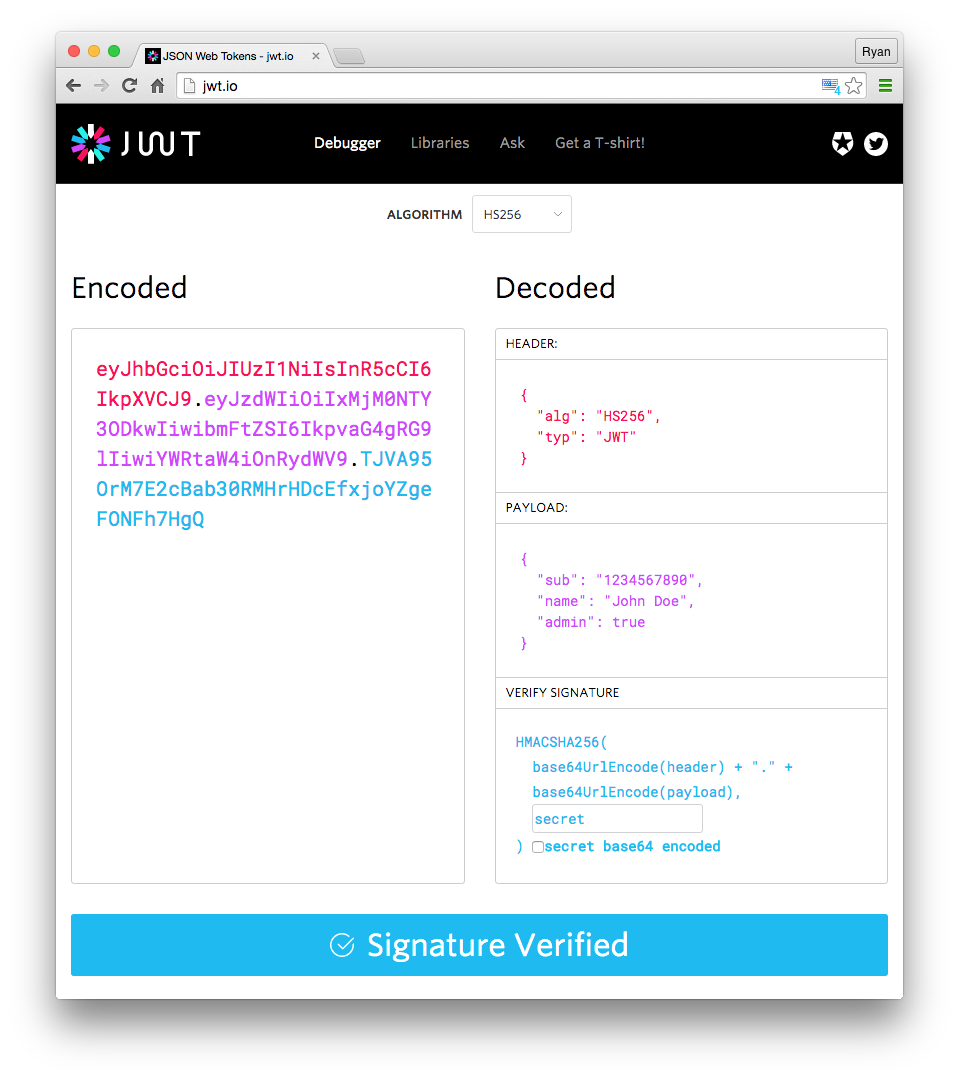
Aunque JWT es una forma de almacenar información de sesión en el cliente, tiene su propia estructura: Header.Payload.Signature (dividido en tres partes separadas por .).
Header
{ "alg": "HS256", "typ": "JWT"}El campo “typ” indica que el tipo de token es JWT, y “alg” representa el algoritmo de firma, como HMAC, SHA256, RSA, etc. Luego, se codifica en base64.
Payload
{ "sub": "1234567890", "name": "John Doe", "admin": true}El Payload es donde se coloca la información de sesión, y también se debe codificar en base64 al final. El resultado es similar a la información de sesión almacenada en el cliente mencionada anteriormente.
Sin embargo, JWT tiene algunas propiedades convencionales, conocidas como “Registered claims”, que incluyen:
- iss (issuer): Emisor
- exp (expiration time): Tiempo de expiración
- sub (subject): Sujeto
- aud (audience): Audiencia
- nbf (Not Before): Tiempo de entrada en vigencia
- iat (Issued At): Tiempo de emisión
- jti (JWT ID): ID del JWT
Firma
La última parte es la firma, que al igual que session.sig mencionado anteriormente, se utiliza para evitar la manipulación. Sin embargo, en JWT, la firma se combina con el contenido.
El algoritmo de generación de firma JWT es el siguiente:
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)Se utiliza el algoritmo especificado en el campo alg del encabezado y la clave secreta definida por uno mismo para codificar base64UrlEncode(header) + "." + base64UrlEncode(payload).
Finalmente, se combinan las tres partes separadas por .. Puedes ver el proceso de construcción de JWT de manera visual en el Depurador de JWT de jwt.io:
Cómo utilizarlo
Después de verificar al usuario y realizar el inicio de sesión correctamente, se le devuelve un JWT al usuario. Debido a que la información en el JWT no está cifrada, no se debe incluir la contraseña en él. Los detalles se mencionan en la sección de cookies almacenadas en el cliente.
Cuando un usuario accede a un enlace que requiere autorización, puede colocar el token en una cookie o incluirlo en el encabezado de la solicitud como Authorization: Bearer <token>. (Al colocarlo manualmente en el encabezado de la solicitud, no está sujeto a las restricciones de CORS y no tiene que preocuparse por CSRF).
El hecho de que la información del JWT se almacene en el cliente implica un problema de no poder invalidarlo, lo cual se considera una desventaja del JWT.
P.D. Aunque es común ver que el JWT se utiliza para iniciar sesión único (SSO), todavía no entiendo cuál es la conexión especial entre los dos.
Autenticación HTTP
La autenticación HTTP es una forma estandarizada de verificación que no utiliza tecnologías de cookies y sesiones. El encabezado de la solicitud contiene un campo de autorización en el formato Authorization: Basic <credentials>.
Las credenciales son el nombre de usuario codificado en Base64 + : + contraseña (o token). Cuando veas autenticación básica, simplemente recuerda que debes incluir el nombre de usuario y la contraseña en cada solicitud.
La autenticación básica es más adecuada para entornos sin servidor, ya que no tienen memoria en ejecución y no pueden almacenar sesiones. Simplemente se incluye la autenticación en cada solicitud y listo.
OAuth 2.0
OAuth 2.0 (RFC 6749) es un protocolo de autorización basado en tokens que permite utilizar interfaces de terceros en un alcance limitado y también permite a las aplicaciones utilizar sistemas de inicio de sesión de terceros, es decir, inicio de sesión de aplicaciones de terceros. (¡Ten en cuenta que el flujo de autorización de OAuth 2.0 podría ser un tema de entrevista!)
Dado que se trata de un inicio de sesión de terceros, aparte de la aplicación en sí, seguramente habrá un servidor de inicio de sesión de terceros. En OAuth 2.0, hay tres roles involucrados: el usuario, el proveedor de la aplicación y la plataforma de inicio de sesión, y su relación de llamada mutua es la siguiente:
+--------+ +---------------+ | |--(A)- Solicitud de autorización ->| Recurso | | | | Propietario | | |<-(B)-- Concesión de autorización ---| | | | +---------------+ | | | | +---------------+ | |--(C)-- Concesión de autorización -->| Servidor de autorización | | Cliente | | de | | |<-(D)----- Token de acceso -------| | | | +---------------+ | | | | +---------------+ | |--(E)----- Token de acceso ------>| Recurso | | | | Servidor | | |<-(F)--- Recurso protegido ---| | +--------+ +---------------+Muchas empresas grandes ofrecen inicio de sesión de terceros con OAuth 2.0, aquí vamos a tomar el ejemplo de WeChat de Xiaolong Ge.
Preparación
Por lo general, el proveedor de la aplicación debe solicitar un AppID y un AppSecret en la plataforma de inicio de sesión. (WeChat utiliza este nombre, pero otras plataformas son similares, un ID y un secreto)
Obtener el código
¿Qué es el código de autorización temporal (code)? Respuesta: El código se utiliza para obtener el
access_tokencuando se realiza la solicitud de terceros. El código tiene un tiempo de expiración de 10 minutos y solo se puede intercambiar con éxito por unaccess_tokenuna vez, después de lo cual se vuelve inválido. La temporalidad del código garantiza la seguridad del inicio de sesión de autorización de WeChat. Los terceros pueden fortalecer aún más la seguridad de su inicio de sesión de autorización utilizando los parámetros https y state.
En este paso, el usuario primero realiza la verificación de identidad en la plataforma de inicio de sesión.
https://open.weixin.qq.com/connect/qrconnect?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=SCOPE&state=STATE#wechat_redirect| Parámetro | Obligatorio | Descripción |
|---|---|---|
| appid | Sí | Identificador único de la aplicación |
| redirect_uri | Sí | Utilice urlEncode para procesar el enlace |
| response_type | Sí | Rellene con “code” |
| scope | Sí | Alcance de autorización de la aplicación, separado por comas (,) si hay varios alcances. Para aplicaciones web, solo complete “snsapi_login” |
| state | No | Se utiliza para mantener el estado de la solicitud y la devolución de llamada, se devuelve sin cambios al proveedor de terceros después de la solicitud de autorización. Este parámetro se utiliza para prevenir ataques CSRF (falsificación de solicitudes entre sitios) |
Tenga en cuenta que scope es una característica del control de permisos de OAuth2.0, que define para qué interfaces se puede utilizar el token obtenido mediante este código.
Después de configurar correctamente los parámetros, al abrir esta página se mostrará la página de autorización. Después de que el usuario haya autorizado con éxito, el plataforma de inicio de sesión redirigirá a la redirect_uri especificada por el proveedor de aplicaciones junto con el código:
redirect_uri?code=CODE&state=STATEEn caso de fallo de autorización, se redirigirá a:
redirect_uri?state=STATEEs decir, si falla, no habrá código.
Obtener el token
Después de redirigir a la URI de redireccionamiento, el backend del proveedor de aplicaciones debe utilizar el código proporcionado por WeChat para obtener el token. También puede utilizar el estado devuelto para verificar la fuente.
Para obtener el token, acceda a esta API con los parámetros correctos:
https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code| Parámetro | Obligatorio | Descripción |
|---|---|---|
| appid | Sí | Identificador único de la aplicación, obtenido después de que la aplicación haya sido aprobada en WeChat |
| secret | Sí | Clave secreta de la aplicación, obtenida después de que la aplicación haya sido aprobada en WeChat |
| code | Sí | Complete el parámetro “code” obtenido en el primer paso |
| grant_type | Sí | Complete “authorization_code”, que es uno de los modos de autorización, y WeChat solo admite este modo |
Respuesta correcta:
{ "access_token": "ACCESS_TOKEN", "expires_in": 7200, "refresh_token": "REFRESH_TOKEN", "openid": "OPENID", "scope": "SCOPE", "unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL"}Una vez que obtengas el token, puedes llamar a la API según el alcance que hayas solicitado al solicitar el código anteriormente.
Llamadas a la API de WeChat utilizando el token
| Alcance de autorización (scope) | API | Descripción de la API |
|---|---|---|
| snsapi_base | /sns/oauth2/access_token | Intercambio de código por access_token, refresh_token y alcance autorizado |
| snsapi_base | /sns/oauth2/refresh_token | Actualización o renovación del access_token |
| snsapi_base | /sns/auth | Verificación de la validez del access_token |
| snsapi_userinfo | /sns/userinfo | Obtención de información personal del usuario |
Por ejemplo, para obtener información personal, se utiliza GET https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN
Ten en cuenta que en OAuth 2.0 de WeChat, el access_token se transmite a través de la consulta (query), no a través de Authorization como se mencionó anteriormente.
Un ejemplo de uso de Authorization, como la autorización de GitHub, los pasos anteriores son similares. Después de obtener el token, se realiza la siguiente solicitud a la API:
curl -H "Authorization: token OAUTH-TOKEN" https://api.github.comVolviendo a la API de userinfo de WeChat, el formato de los datos devueltos es el siguiente:
{ "openid": "OPENID", "nickname": "NICKNAME", "sex": 1, "province":"PROVINCE", "city":"CITY", "country":"COUNTRY", "headimgurl":"https://thirdwx.qlogo.cn/mmopen/g3MonUZtNHkdmzicIlibx6iaFqAc56vxLSUfpb6n5WKSYVY0ChQKkiaJSgQ1dZuTOgvLLrhJbERQQ4eMsv84eavHiaiceqxibJxCfHe/46", "privilege":[ "PRIVILEGE1" "PRIVILEGE2" ], "unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL"}Uso posterior
Después de obtener la información personal del usuario utilizando el token, puedes utilizar el openid devuelto por la API de userinfo junto con la tecnología de sesión para implementar el inicio de sesión en tu propio servidor.
// Iniciar sesiónreq.session.id = openid;if (req.session.id) { // Sesión iniciada} else { // Sesión no iniciada}// Cerrar sesiónreq.session.id = null;// Limpiar sesiónResumiendo el proceso y los puntos clave de OAuth2.0:
- Solicitar un ID y una clave secreta para tu aplicación
- Preparar una interfaz de redireccionamiento
- Obtener correctamente el código de autenticación <- Importante
- Pasar el código a tu interfaz de redireccionamiento
- Usar el código en la interfaz de redireccionamiento para obtener el token <- Importante
- Utilizar el token para acceder a la API de WeChat
OAuth2.0 se centra en la autenticación de terceros y en la limitación de permisos. Además, OAuth2.0 no es el único método de autorización utilizado por WeChat, existen otros métodos que se pueden consultar en el artículo de Cuatro métodos de autorización de OAuth 2.0 del profesor Ruanyifeng.
Otros métodos
Tanto JWT como OAuth2.0 son métodos de autenticación completos, pero eso no significa que un sistema de inicio de sesión deba ser tan complejo.
De hecho, se puede implementar un sistema de inicio de sesión simple utilizando los dos métodos de almacenamiento de sesión mencionados anteriormente.
-
Utilizando el almacenamiento de sesión en el servidor como base, se puede utilizar un método similar a
req.session.isLogin = truepara marcar el estado de la sesión como iniciada. -
Utilizando el almacenamiento de sesión en el cliente como base, establecer una fecha de vencimiento para la sesión y el usuario que ha iniciado sesión es suficiente.
{ "exp": 1614088104313, "usr": "admin"}(Es básicamente el mismo principio que JWT, pero sin un sistema completo)
- Incluso puedes utilizar los conocimientos anteriores para escribir tu propio sistema de inicio de sesión en Express:
- Inicializar un almacenamiento, puede ser en memoria, Redis o una base de datos.
- Después de que la autenticación del usuario sea exitosa, generar un código hash aleatorio como token.
- Escribir el token en la cookie utilizando
set-cookie. - Luego, en el servidor, almacenar el estado de inicio de sesión, por ejemplo, en el caso del almacenamiento en memoria, agregar el código hash como propiedad en el almacenamiento.
- En las solicitudes posteriores, verificar si el token proporcionado en la cookie está almacenado en el almacenamiento.
let store = {};
// Después de iniciar sesión correctamentestore[HASH] = true;cookie.set("token", HASH);
// En las solicitudes que requieren autenticaciónconst hash = cookie.get("token");if (store[hash]) { // Sesión iniciada} else { // Sesión no iniciada}
// Cerrar sesiónconst hash = cookie.get("token");delete store[hash];Resumen
A continuación, se enumeran los puntos clave de este artículo:
- Las cookies son contenedores para almacenar sesiones, identificadores de sesión o tokens.
- Las cookies se suelen configurar mediante la cabecera de solicitud
set-cookie. - La información de la sesión se puede almacenar en el navegador o en el servidor.
- Cuando la sesión se almacena en el servidor, se utiliza el identificador de sesión para obtener la información.
- Los límites entre token, sesión e identificador de sesión son difusos.
- Por lo general, las nuevas tecnologías utilizan tokens, mientras que las tecnologías tradicionales utilizan identificadores de sesión.
- Las cookies, los tokens, las sesiones y los identificadores de sesión son tecnologías prácticas utilizadas para la autenticación.
- JWT es una forma de almacenar sesiones en el navegador.
- El token de OAuth2.0 no es emitido por la aplicación, sino por un servidor de autorización independiente.
- OAuth2.0 se utiliza comúnmente para el inicio de sesión de aplicaciones de terceros.