모든 사람이 알고 있듯이 컴퓨터는 정보를 저장할 때 본질적으로 0과 1을 저장하는데, 숫자라면 이해하기 쉽습니다. 이진법을 십진법으로 변환하거나 과학적 기수법을 사용하면 되죠. 하지만 도대체 컴퓨터는 어떻게 0과 1의 더미를 인간이 읽을 수 있는 문자로 표시하는 걸까요? 이 글을 다 읽고 나면 여러분도 이해하게 될 것입니다😉
사전 지식
사전 지식이라기보다는 몇 가지 상기시켜 드릴 내용들입니다:
- 1 bit는 1개의
1또는0입니다 - 1 byte = 8 bit
- 1 byte의 가능성은
0b00000000부터0b11111111까지입니다 - 따라서 1 byte는 2의 8제곱, 즉 256개의 숫자를 표현할 수 있습니다
- 16진법은 byte를 기록하기에 좋은 형식입니다
- 이진법보다는
0x00부터0xff까지로 1 byte의 내용을 표현하는 것이 더 일반적입니다
문자 인코딩표의 기원
문자 인코딩표(Character Encoding Table)는 이해하기 쉬운 개념으로, 완전히 하나의 수치가 하나의 문자에 대응되는 것입니다. 일단 대략적으로 생각해보면, 여러분이 컴퓨터에서 볼 수 있는 문자는 이런 표에서 규정한 매핑을 통해 0과 1의 더미에서 여러분이 볼 수 있는 문자로 변환되는 것입니다.
가장 널리 알려진 최초의 문자 인코딩표는 ASCII입니다.
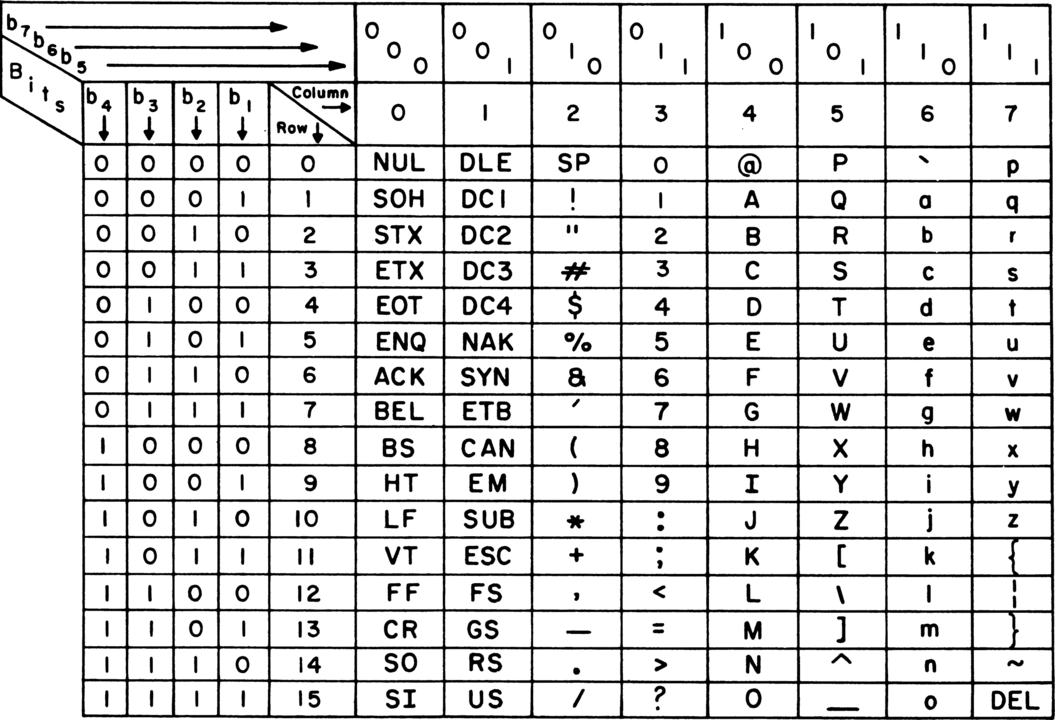
전신을 보내는 것부터 시작해서 ASCII가 두각을 나타내기 시작했습니다. 보시다시피 최초의 ASCII는 7비트(bit)만 있었는데, 당시 대역폭을 절약하기 위해 실제로 7비트를 사용했지만, 이 수치는 컴퓨터에게 그리 친화적이지 않아서 나중에 8비트, 즉 1바이트(byte)로 변경되었습니다.
1비트가 더 생겼으니 ASCII 표를 계속 확장할 충분한 이유가 있었고, 이렇게 해서 널리 퍼진 두 가지 8비트 확장 ASCII 표가 생겨났습니다: ISO-8859-1과 Windows-1252. 이 두 확장표의 확장 부분은 완전히 같지는 않지만, 모두 유럽과 미국에서 사용하는 문자들로 채워졌습니다. 예를 들어: å æ ç è é 등등.
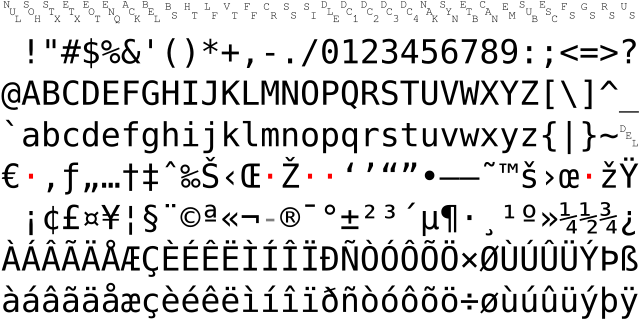
컴퓨터는 미국에서 시작되었지만 결국 전 세계로 퍼져나갔는데, 영어만 표시할 수 있다면 어떻게 충분하겠습니까? 표음 문자를 사용하는 유럽과 미국 각국에게는 이 상황이 잘 해결되었지만, 표의 문자를 사용하는 중일한(줄여서 CJK)에게는 매우 문제가 되었습니다. 그래서 각 나라마다 자국 문자에 적합한 문자 인코딩표를 제정했는데, 이런 인코딩표들은 모두 ASCII와 호환되는 기반 위에 자국 문자를 추가했습니다. 예를 들어 중국의 GBK와 Big5, 일본의 Shift-JIS, 한국의 EUC-KR, 베트남의 VISCII 등등입니다.
ASCII의 경우 본래 256개의 코드만 있어서 1바이트로 쉽게 표현할 수 있었지만, 각종 확장 집합들은 모두 256을 초과해서 2바이트로 1개 문자를 표현하게 되었습니다… 이때 여러분은 문제를 발견하셨나요?
단순히 숫자 순서대로 배열한다면, 257번째 값을 인코딩할 때 0x00과 0xff 하나씩이 되는데, 그러면 시스템은 이것이 도대체 1개 문자인지 2개 문자인지 전혀 알 수 없습니다. 따라서 대량의 문자를 인코딩하려면 시스템에게 한 글자의 바이트 수를 알려주는 명확한 표시가 있어야 합니다. GBK의 경우 0x7f보다 작으면 단일 바이트, 그 이상은 모두 더블 바이트로 규정했습니다. 이런 규정이 있으면 시스템은 0x81이 절대 단일 바이트로 문자가 될 수 없다는 것을 알고, 한 바이트를 더 읽어서 코드표에서 해당하는 문자를 찾습니다.
예를 들어 GBK의 A는 ASCII와 호환되는 0x41이고, 我는 0xce 0xd2인데, 앞의 바이트가 0x81보다 크므로 한 바이트를 더 읽어서 我를 구성합니다. 마찬가지로 Shift-JIS 등 다른 국가의 인코딩도 이런 방식으로 작동합니다.
사실 이렇게 지역마다 다른 코드표를 사용하는 것은 정말 좋은 방법이 아니었습니다. 이는 21세기 초 네티즌들에게 매우 흔한 문제를 야기했습니다: 깨진 글자(문자 깨짐). 다른 지역의 파일을 받아서 자신의 컴퓨터에서 열면 알아볼 수 없는 문자열이 보이는 것은 당연했습니다. 일본에서 온 텍스트는 본래 Shift-JIS 인코딩을 사용했지만, 바다 건너편에 와서는 GBK 방식으로 디코딩되니, 이 두 코드표가 맞을 리가 없었죠. Shift-JIS로 된 こんにちは가 GBK 영역에 오면 偙傫偵偪偼가 되고, GBK의 你好가 일본에 가면 ト羲テ가 되었습니다. 언어가 통하지 않는 것을 넘어서 이것은 거의 암호 통신이었습니다.
위에서 설명한 신기한 인코딩 변환 체험을 해보고 싶다면 여기에서 해볼 수 있습니다. 어쨌든 최근 10년간은 기본적으로 이런 문제를 만날 일이 없었죠. 하지만 왜 그럴까요?
바로 우리의 위대한 Unicode가 모든 인코딩을 통일했기 때문입니다. 대통일의 시대가 온 것이죠!
Unicode
Unicode는 지구상의 모든 언어 문자를 집합한 하나의 표입니다. 이제부터 우리는 더 이상 서로 다른 인코딩 방식을 구분할 필요가 없어졌고, 통일된 Unicode 인코딩을 사용하게 되었습니다.
Unicode는 10FFFF개(즉, 1114111개)의 코드 포인트(code point)를 가지고 있습니다. 그 중 가장 중요한 것은 앞의 0000부터 ffff까지의 코드 포인트들로, 이 범위는 기본 다국어 평면(Basic Multilingual Plane, 줄여서 BMP)이라고 불립니다. 그 뒤로도 65536개 포인트마다 하나의 평면으로, 총 17개의 평면이 있습니다. 여전히 CJK 표의문자가 큰 비중을 차지하고 있으며, 전체 코드표에는 사실 아직도 많은 빈 자리가 있습니다.
대가의 매우 직관적인 그림을 빌려오면, 세계의 모든 상용 문자를 포함하는 BMP는 Unicode의 첫 번째 작은 블록에 불과합니다:
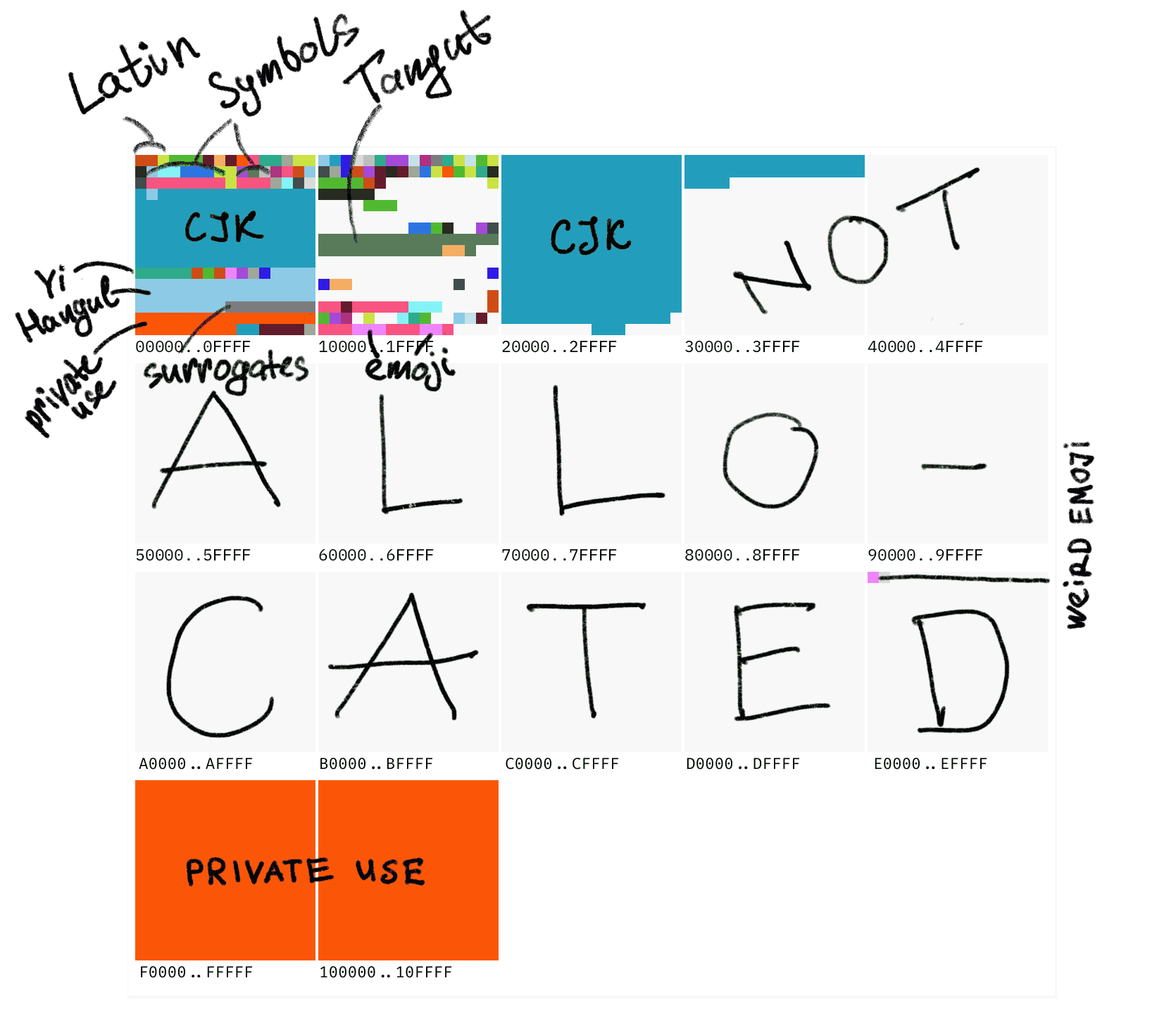
처음에 저는 “코드”에서 “문자”로의 관계를 변환을 거치지 않는 간단한 1대1 관계라고 대략적으로 생각할 수 있다고 말했지만, 여기까지 보셨다면 이제 한 단계 더 나아갈 때입니다. Unicode는 “코드 포인트”와 “인코딩” 두 층의 개념을 가지고 있습니다.
간단히 말해서, Unicode에서 UTF-8로 인코딩하는 방법은 코드 포인트를 4개 구간으로 나누어 각기 다른 구간에 서로 다른 인코딩 방식을 적용하는 것입니다:
| Code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
0000..007F는 표준 ASCII로 1바이트로 인코딩되고, 맨 뒤 부분인 10000..10FFFF는 네 부분으로 나뉘어 4바이트로 인코딩됩니다.
같은 코드 포인트 세트를 Unicode는 UTF-16으로도 인코딩할 수 있습니다. UTF-16으로 인코딩된 후 모든 문자는 16비트로 안정화되어, 최대 65536개의 문자(즉, BMP 범위)를 표현할 수 있습니다. UTF-16의 가장 치명적인 점은 모든 문자가 16비트로 인코딩되기 때문에 가장 원시적인 ASCII를 지원하지 않는다는 것입니다.
또한 UTF-16에는 추가로 서로게이트 쌍(surrogate pair)이라는 개념이 있습니다. Unicode가 FFFF를 초과하기 때문에 그 이상에서는 2바이트로 하나의 문자를 정의할 수 없어서, 일정한 규칙에 따라 4바이트로 변환해야 합니다. UTF-16은 일반적인 파일의 인코딩 방식은 아니지만, JavaScript를 사용한다면 그 문자열은 메모리에서 UTF-16으로 인코딩되어 있으며, 뒤의 프로그래밍 부분에서 더 자세히 설명하겠습니다.
하나의 코드표가 Emoji를 포함한 모든 문자를 담고 있어서 매우 아름다워 보이지만, 실제로 Unicode에는 매우 기이한 점이 있습니다: 10FFFF가 Unicode가 표현할 수 있는 문자의 상한이 아니라는 것입니다. Unicode는 여러 코드 포인트를 조합해서 1개의 문자로 만들 수 있습니다.
예를 들어 이 Emoji 👨👩👧👦를 JavaScript로 '👨👩👧👦'.length를 실행하면, 결과는 놀랍게도 11이 나옵니다. Emoji Spliter로 분해해보면, 겉보기에는 1개의 Emoji에 불과하지만 실제로는 아래와 같은 것들로 구성되어 있다는 것을 발견할 수 있습니다:
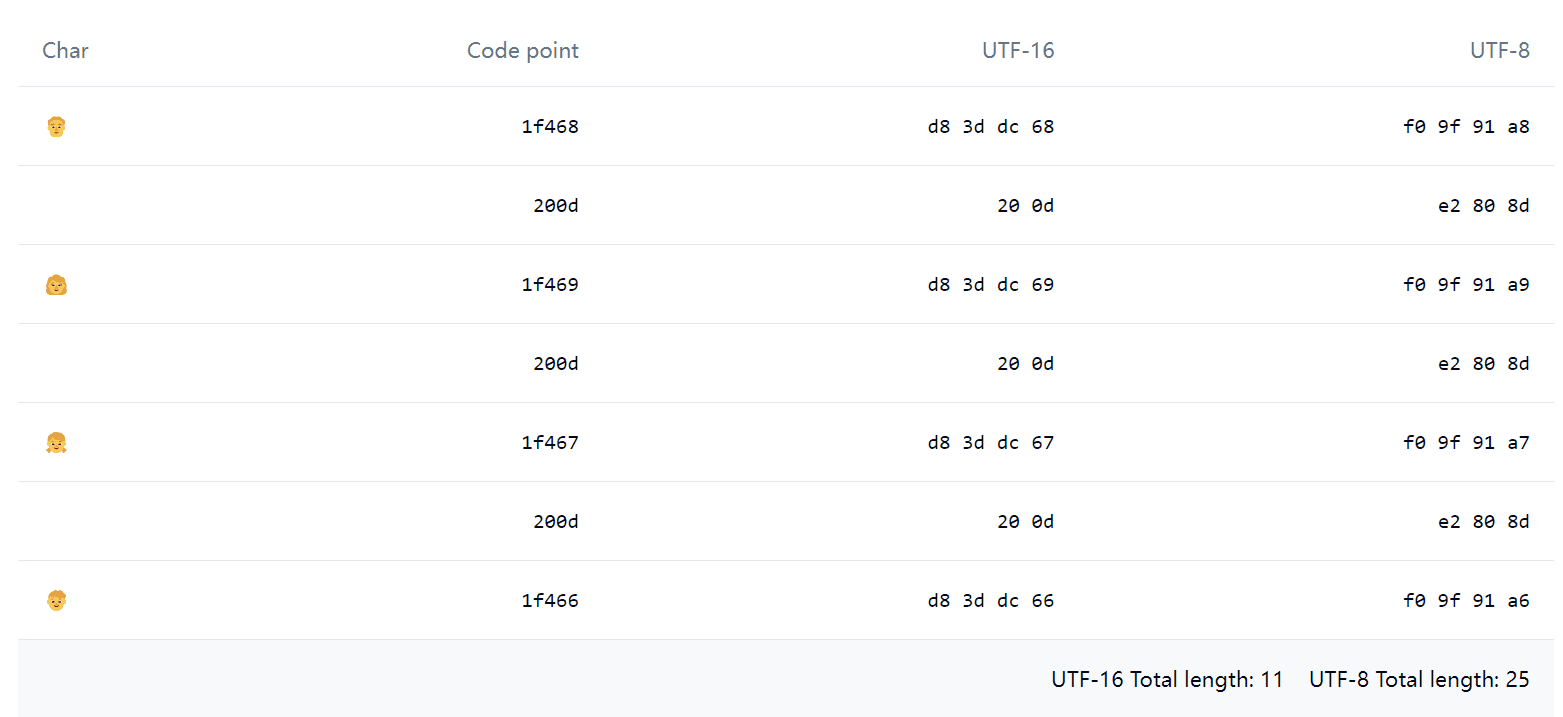
그 중 0x200d는 Zero-width joiner(줄여서 ZWJ)라고 불리며, ZWJ는 일부 Emoji들을 붙여서 하나로 조합할 수 있습니다. 예를 들어 위에서 보이는 네 식구 👨👩👧👦는 실제로 정말로 네 식구의 4개 Emoji를 포함하고 있습니다. Emoji 외에도 일부 인간 언어에서도 ZWJ를 사용합니다.
인코딩에서 폰트까지
이진 인코딩에서 문자를 화면에 표시하기까지, 필수적인 요소는 바로 폰트(font)입니다. 컴퓨터에 운영체제를 설치할 때 기본 폰트들이 함께 설치되는데, 이는 필수적입니다. 그렇지 않으면 렌더링 시 인코딩에 해당하는 문자를 찾을 수 없어 흰색 사각형이 표시되며, 이를 Tofu “두부 블록”이라고 부릅니다. 구글의 Noto 폰트는 컴퓨터에서 Tofu가 나타나지 않도록 하겠다는 의미를 담고 있지만, 좋은 취지에도 불구하고 실제로는 Noto가 CJK Ext-B를 지원하지 않습니다.
현재 일반적으로 사용되는 폰트 형식에는 ttf, otf, woff, woff2가 있습니다.
ttf(TrueType Font)와 otf(OpenType)의 주요 차이점은 otf는 3차 베지어 곡선을 사용하고, ttf는 2차 베지어 곡선을 사용한다는 것입니다. 또한 ttf의 힌팅이 더 우수하여 저해상도 기기에서 렌더링할 때 더 보기 좋습니다.
woff(Web Open Font Format)는 실제로 ttf의 핵심 부분을 zlib으로 압축한 것이고, woff2도 비슷하지만 압축 알고리즘이 Brotli로 업데이트되었습니다.
시스템이 인코딩에서 문자를 찾아야 하므로, 당연히 폰트는 인코딩과 문자의 매핑을 유지해야 합니다. 그래서 예전에는 폰트 뒤에 gbk라고 표시된 경우가 있었는데, 이는 gbk 인코딩 시스템 전용 폰트였습니다. 지금은 말할 것도 없이 모두 Unicode일 것입니다.
CJK 문자(및 일부 서양 문자)의 경우, 동일한 코드 포인트가 지역에 따라 다른 글리프(glyph)를 가집니다. 각 언어마다 동일한 의미의 문자(grapheme)를 별도로 인코딩하지 않는 이러한 상황을 한자 통합이라고 하며, 주로 인코딩 공간을 절약하기 위함입니다. 주목할 점은 중국어 기반의 한자 번체와 간체는 동일한 코드 포인트로 통합되지 않았기 때문에, 번체-간체 변환은 폰트 교체가 아니라 번체-간체 매핑 테이블이 존재한다는 것입니다.

단일 폰트가 지역에 따라 다른 글리프를 표시할 수 있다는 자료가 있지만, 실제로는 폰트 제공업체들이 언어별로 폰트를 패키징합니다. 모든 언어의 모든 문자를 하나로 묶으면 너무 크기 때문이며, 특히 웹용 폰트의 경우 페이지를 열 때 수십 메가바이트의 폰트 다운로드를 기다려야 한다면 사용자 경험이 매우 나빠집니다.
예를 들어, Noto-cjk를 다운로드할 때 지역별로 다운로드하는 것을 권장합니다. 굳이 CJK 전체 패키지를 다운로드하면 ttc 파일이 다운로드되는데, 실제로는 여러 ttf 파일의 집합으로, 하나의 패키지에 여러 지역의 이체자가 통합되어 있습니다.
<td lang="zh-Hans">关</td><td lang="zh-Hant">关</td><td lang="zh-Hant-HK">关</td><td lang="ja">关</td><td lang="ko">关</td>브라우저는 lang의 지시에 따라 각 언어의 기본 폰트를 사용해서 이 문자들을 렌더링하므로, 서로 다른 언어 간의 글리프 차이를 볼 수 있습니다. 다만 주의할 점은, 웹페이지 폰트가 특정 언어의 폰트로 설정되어 있고 그 폰트가 현재 문자와 일치한다면 브라우저는 다른 언어의 기본 폰트로 되돌아가지 않는다는 것입니다. 예를 들어 Microsoft YaHei는 중국어 간체의 기본 폰트인데, font-family: Microsoft YaHei로 명시적으로 설정했다면 lang을 무엇으로 설정하든 중국어 간체 글리프를 사용합니다.
폰트의 기타 능력

어느 날 구글 문서에서 이런 이상한 ICON을 발견했는데, 복사할 때 원본 텍스트(즉, 문자열 block)가 복사되었습니다. 사실 이것은 Material Symbols Outlined라는 폰트로, 문자열을 아이콘으로 표시할 수 있는 이유는 합자(ligature)라는 기술을 사용했기 때문입니다. 간단히 말해서 특정 문자 그룹이 매칭되면 자동으로 다른 문자로 대체되는 것입니다.
FontForge를 사용해서 합자 설정을 볼 수 있는데, 메뉴에서 Ligatures를 찾으면 됩니다:
그러면 자세한 설정을 볼 수 있습니다:
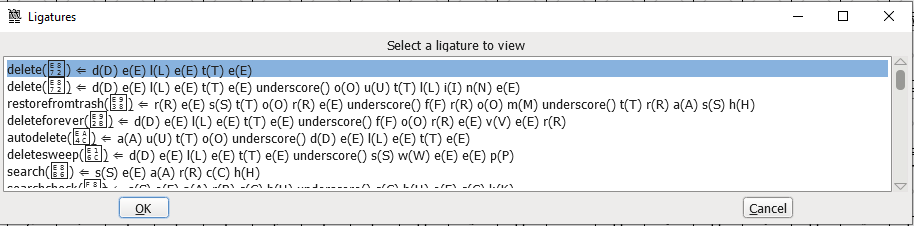
구글 문서의 이런 ICON을 합자로 사용하는 것은 비주류 예시라고 할 수 있고, 더 일반적인 합자는 라틴 문자 fi, fl 등의 연결 표기나, 일부 코드 에디터 전용 폰트에서 !=, ==, => 등의 기호를 연결 표기해서 더 아름답게 보이게 하는 것입니다.
이와 비슷한 폰트 학문은 많이 있습니다. 또 다른 예시로는 폰트를 사용한 JavaScript 구문 강조 구현이 있는데, JavaScript 코드도, 추가 요소나 CSS도 없이 순수하게 폰트만으로 구현한 것입니다. 원리는 폰트 파일에서 정의한 연쇄 문맥 룩업으로, 특정 순서의 문자를 찾아낸 후 다른 색상의 변형으로 대체하는 것으로 보입니다.
복잡한 인코딩과 프로그래밍
Unicode 대통일 이후, 기본적으로 모든 프로그래밍 언어의 문자열은 Unicode 인코딩이며, JavaScript도 마찬가지입니다. 하지만 앞서 말했듯이 하나의 Unicode 코드표를 UTF-8, UTF-16, UTF-32로 인코딩할 수 있는데, JavaScript는 메모리에서 UTF-16을 사용합니다.
charAt는 여러분이 가장 먼저 접했을 상황으로 문자열에서 N번째 문자 자체를 가져오는 것입니다.
charCodeAt와 codePointAt는 모두 문자의 코드 포인트(즉, code point)를 반환합니다. 하지만 codePointAt는 완전한 Unicode 코드 포인트를 반환하고, charCodeAt는 해당 위치의 단일 code unit(코드 포인트가 아닙니다!)의 십진값을 반환합니다. 다만 0xffff 범위 내에서는 서로게이트 쌍의 간섭이 없기 때문에 codePointAt와 charCodeAt가 같습니다.
예시를 들어보겠습니다. 먼저 가장 일반적인 0xffff 이하의 코드 포인트 문자를 보겠습니다:
"天".charAt(); // '天'"天".charCodeAt().toString(16); // '5929'"天".codePointAt().toString(16); // '5929'모든 것이 정상입니다.
그다음 기이한 서로게이트 쌍을 보겠습니다:
"𪜹".charAt(); // '\uD869'"𪜹".charCodeAt().toString(16); // 'd869'"𪜹".codePointAt().toString(16); // '2a739'코드 포인트 값이 0x2a739로 0xffff를 초과해서 서로게이트 쌍을 사용했기 때문에, 단일 charAt와 charCodeAt가 모두 실패하고 UTF-16 서로게이트 쌍 중 한 그룹만 반환했습니다. "𪜹".charCodeAt(1).toString(16)을 사용해야 다음 위치를 읽어낼 수 있습니다. 정말 한마디 하고 싶은 것은, 서로게이트 쌍의 절반을 읽어내는 것이 도대체 무슨 의미가 있는지 모르겠습니다 😂
다행히 codePointAt는 여전히 정확합니다.
마지막으로 위에서 언급한 더욱 기이한 조합 Emoji를 보겠습니다:
"👨👩👧👦".charAt(); // '\uD83D'"👨👩👧👦".charCodeAt().toString(16); // 'd83d'"👨👩👧👦".codePointAt().toString(16); // '1f468'버프가 가득 쌓인 상태라고 밖에 표현할 수 없습니다. codePointAt는 맞지만 완전히 맞지는 않아서, 조합 중 첫 번째 문자(👨)의 코드 포인트만 반환할 수 있고, charAt와 charCodeAt도 첫 번째 서로게이트 쌍만 반환합니다.
위의 표를 다시 살펴보겠습니다:
| 문자 | 코드 포인트 | UTF-16 | UTF-8 |
|---|---|---|---|
| 👨 | 1f468 | d8 3d dc 68 | f0 9f 91 a8 |
| | 200d | 20 0d | e2 80 8d |
| 👩 | 1f469 | d8 3d dc 69 | f0 9f 91 a9 |
| | 200d | 20 0d | e2 80 8d |
| 👧 | 1f467 | d8 3d dc 67 | f0 9f 91 a7 |
| | 200d | 20 0d | e2 80 8d |
| 👦 | 1f466 | d8 3d dc 66 | f0 9f 91 a6 |
JavaScript의 문자 연산은 code unit 단위(바이트 단위가 아닌)로 계산되는 것 같습니다. (UTF-16의 code unit은 16비트, UTF-8은 8비트, UTF-32는 당연히 32비트인데, 이것은 실제로 하나의 문자를 구성하는 최소 조합의 길이입니다)
따라서 '👨👩👧👦'.length가 11인 이유는 11개의 UTF-16 코드가 있기 때문입니다. 만약 어떤 프로그래밍 언어의 문자열이 메모리에서 UTF-8을 사용한다면, 예를 들어 Rust의 경우 길이는 더욱 끔찍한 25가 됩니다…
다행히 좋은 소식은 CJK 문자가 많아 보이지만 실제로 상용 문자들도 모두 BMP 내에 있어서 위에서 언급한 상황이 거의 발생하지 않는다는 것입니다. Emoji의 경우… 일반적으로 엄밀한 연산을 다루지 않죠. 어쨌든 서로게이트 쌍과 조합 문자 덕분에 이런 문자 연산에서 많은 반직관적인 결과가 나타나니 주의하시기 바랍니다.
CSS와 HTML의 Unicode 인코딩 관련 소소한 지식은 몇 년 전 옛 글에서 볼 수 있습니다.
용어
- 문자집합(Character Set): 문자의 집합으로, 어떤 문자들이 표현될 수 있는지를 정의합니다.
- 문자 인코딩(Character Encoding): 문자집합의 문자를 숫자로 매핑하는 규칙입니다.
- 코드 포인트(Code Point): 문자집합에서 문자의 고유 식별자로, 보통 숫자입니다.
- 코드 유닛(Code Unit): 인코딩 방식의 기본 단위로, UTF-16에서는 16비트 단위입니다.
- 서로게이트 쌍(Surrogate Pair): UTF-16에서 기본 다국어 평면을 벗어나는 문자를 표현하기 위한 메커니즘입니다.
- 기본 다국어 평면(Basic Multilingual Plane, BMP): Unicode의 첫 번째 평면으로, 가장 자주 사용되는 문자들을 포함합니다.
- 합자(Ligature): 여러 문자를 조합해서 하나의 글리프로 표시하는 타이포그래피 기술입니다.
- 글리프(Glyph): 문자의 시각적 표현 형태입니다.