皆さんもご存知の通り、コンピュータが情報を保存する際、本質的には0と1を保存しています。数字であれば理解しやすく、二進数を十進数に変換したり、科学記数法を使ったりできます。しかし、コンピュータは一体どのようにして0と1の羅列を人間が読める文字として表示しているのでしょうか?この記事を読み終えれば、きっと理解できるはずです😉
前提知識
前提知識というより、むしろ注意点として:
- 1 bit は1つの
1または0 - 1 byte = 8 bit
- 1 byte の可能性は
0b00000000から0b11111111まで - つまり1 byte は2の8乗、すなわち256個の数字を表現できる
- 十六進数はbyteを記録するのに適した形式
- 二進数よりも、
0x00から0xffで1 byte の内容を表現するのが一般的
コード表の起源
コード表(Character Encoding Table)は理解しやすい概念で、完全に数値と文字の一対一対応です。とりあえず大まかに言えば、コンピュータで見ることができる文字は、この表で規定されたマッピングによって0と1の羅列から見える文字に変換されているのです。
最も広く知られている最も原始的なコード表は ASCII です。
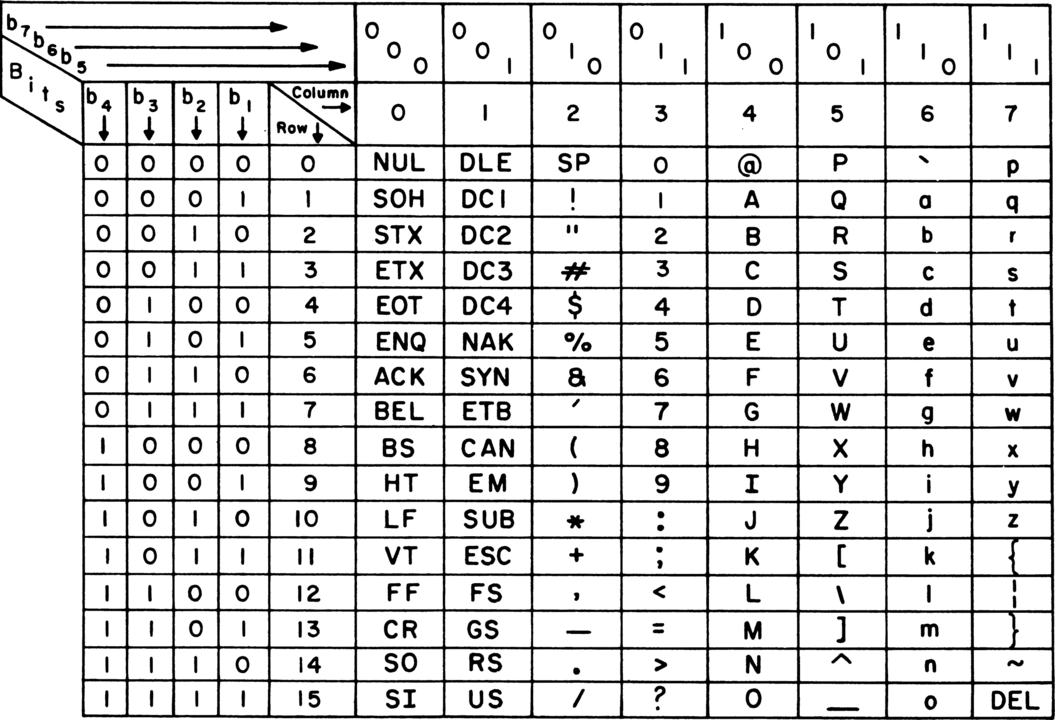
電報の時代から、ASCIIは頭角を現していました。ご覧の通り、最初のASCIIは7ビット(bit)しかありませんでした。当時は帯域幅を節約するために確かに7ビットを使用していましたが、この数値はコンピュータにとってあまり扱いやすくなかったため、後に8ビット、つまり1バイト(byte)に変更されました。
1ビット増えたのですから、ASCII表を拡張する十分な理由がありました。そこで、広く普及した2つの8ビット拡張ASCII表が生まれました:ISO-8859-1とWindows-1252です。これら2つの拡張表の拡張部分は完全に同じではありませんが、どちらも欧米で使用される文字、例えば:å æ ç è é などを追加しています。
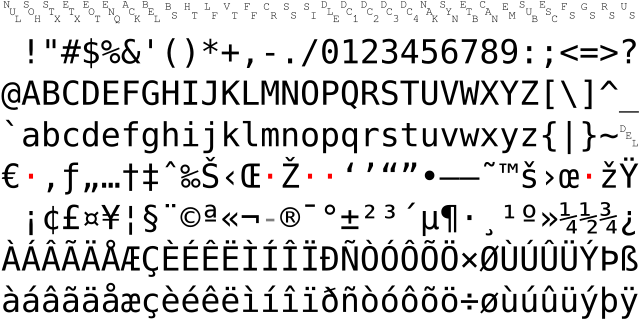
コンピュータはアメリカで生まれましたが、最終的には世界中に広がりました。英語だけしか表示できないのでは十分ではありませんよね?表音文字を使用する欧米諸国にとって、この状況は比較的解決しやすいものでしたが、表意文字を使用する中日韓(CJKと略称)にとっては大きな問題でした。そこで各国は自国の文字に適したコード表を制定し、これらのコード表はすべてASCIIとの互換性を保ちながら自国の文字を追加しました。例えば、中国のGBKとBig5、日本のShift-JIS、韓国のEUC-KR、ベトナムのVISCIIなどです。
ASCIIについては、元々256個のコードしかなく、1バイトで簡単に表現できました。しかし、各種拡張セットはすべて256を超えており、1文字を2バイトで表現することになりました…ここで皆さん、問題に気づきましたか?
単純に数字順に並べるとすると、257番目の値は 0x00 と 0xff になってしまい、システムはこれが1文字なのか2文字なのか全く分からなくなります。そのため、大量の文字をエンコードするには、システムに1文字のバイト数を明確に示す標識が必要でした。GBKの場合、0x7f 未満を単一バイト、それ以上をすべて2バイトと規定しています。この規定により、システムは 0x81 が単独でバイト文字になることはないと知り、もう1バイト読んでからコード表で対応する文字を見つけます。
例えば、GBKの A はASCII互換の 0x41 ですが、我 は 0xce 0xd2 で、最初のバイトが 0x81 より大きいため、もう1バイト読んで 我 を構成します。同様に、Shift-JISなど他国のエンコーディングも同じ操作を行います。
実際、このように地域ごとに異なるコード表を使うのは良い方法ではありませんでした。これは21世紀初頭のネットユーザーによく見られた問題を引き起こしました:文字化けです。他の地域からのファイルを受け取って自分のコンピュータで開くと、理解できない文字列が表示される。これは当然のことで、日本からのテキストは元々Shift-JISでエンコードされているのに、海の向こう側ではGBKでデコードされる。この2つのコード表が一致するはずがありません。Shift-JISの こんにちは がGBKの領域に来ると 偙傫偵偪偼 になり、GBKの 你好 が島国に行くと ト羲テ になる。言語が通じないどころか、これはもはや暗号通信です。
上記で説明した変換の奇妙な体験を味わいたい方はこちらで試してみてください。とはいえ、ここ10年ほどはこのような問題にはほとんど遭遇しなくなりました。なぜでしょうか?
我らが偉大なUnicodeがすべてのエンコーディングを統一したからです。大統一の時代が到来したのです!
Unicode
Unicode は地球上のすべての言語の文字を集めた表で、これにより、もはや異なるエンコーディング方式を区別する必要がなくなり、統一してUnicodeエンコーディングを使用できるようになりました。
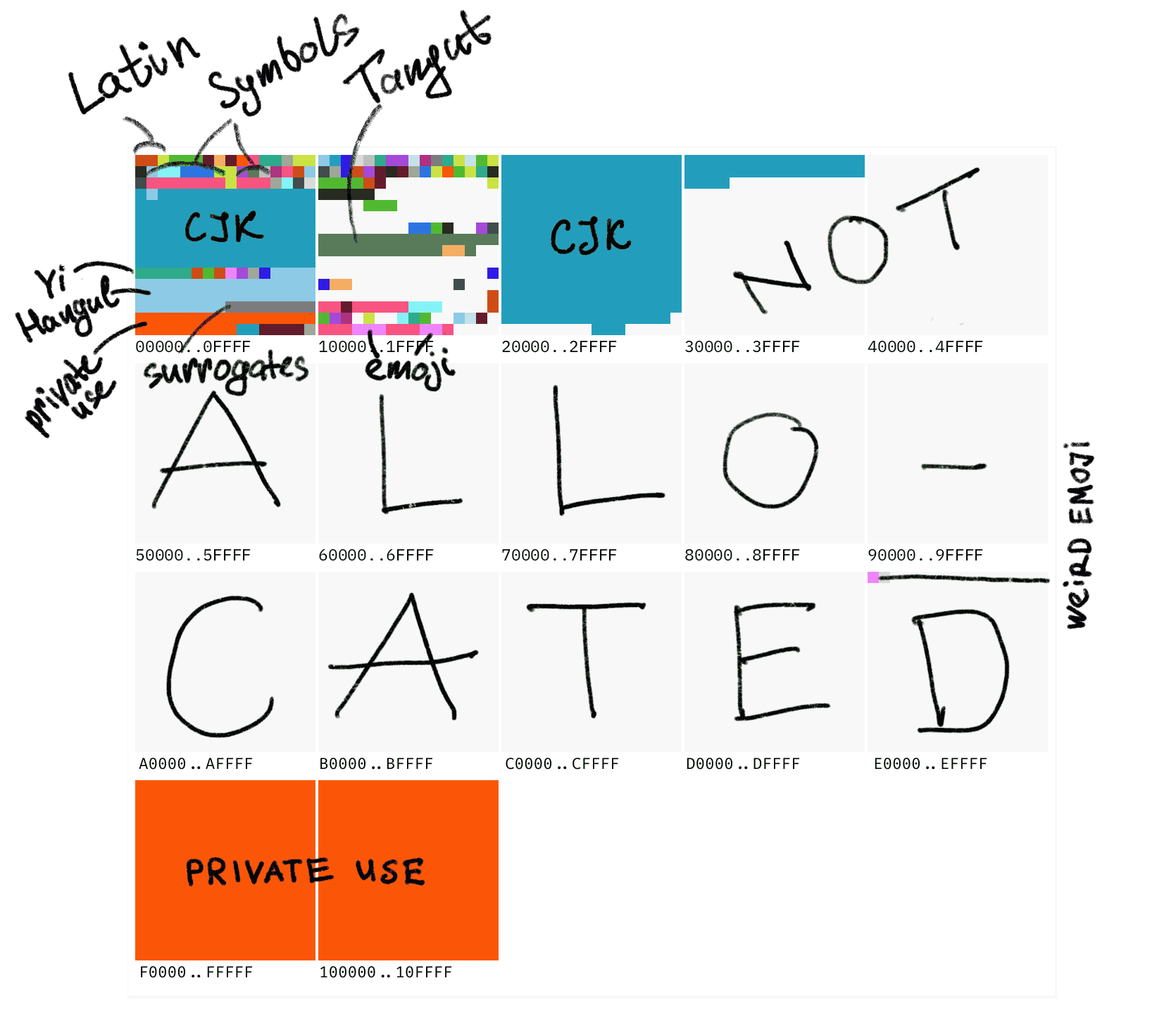
Unicodeには 10FFFF 個(つまり1114111個)のコードポイント(code point)があります。その中で最も重要なのは最初の 0000 から ffff までのコードポイントで、この範囲は基本多言語平面(Basic Multilingual Plane、略称BMP)と呼ばれています。その後も65536ポイントごとに1つの平面となり、合計17の平面があります。大部分を占めているのはやはりCJK表意文字で、全体のコード表には実際にはまだ大量の空きがあります。
大佬から非常に直感的な図を拝借すると、世界中のすべての常用文字を含むBMPは、Unicodeのほんの最初の小さなブロックに過ぎません:
最初、私は「コード」から「文字」への関係を変換を経ないシンプルな1対1の関係と大まかに考えることができると言いましたが、ここまで来ると、レベルアップの時です。Unicodeには「コードポイント」と「エンコーディング」という2層の概念があります。
簡単に言うと、UnicodeからUTF-8へのエンコーディング方法は、コードポイントを4つの区間に分け、異なる区間で異なるエンコーディング方式を採用することです:
| Code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
0000..007F は標準ASCIIで、1バイトでエンコードされ、最後の部分 10000..10FFFF は4つに分割されて4バイトでエンコードされます。
同じコードポイントセットで、UnicodeはUTF-16にエンコードすることもできます。UTF-16にエンコードされた後、すべての文字は16ビットで安定し、最大65536文字(つまりBMP範囲)を表現できます。UTF-16の最も致命的な点は、すべての文字が16ビットでエンコードされるため、最も原始的なASCIIをサポートしないことです。
さらに、UTF-16にはサロゲートペア(surrogate pair)という概念があります。Unicodeが FFFF を超えるため、それ以上では2バイトで1文字を定義することが保証できないので、一定の規則に従って4バイトに変換する必要があります。UTF-16は一般的なファイルのエンコーディング方式ではありませんが、JavaScriptを使用している場合、その文字列はメモリ内でUTF-16エンコードされており、後のプログラミング部分で詳しく説明します。
1つのコード表にはすべての文字が含まれており、多くの可愛いEmojiも含まれていて、とても美しく見えますが、実際にはUnicodeには奇妙な点があります:10FFFF はUnicodeが表現できる文字の上限ではなく、Unicodeは複数のコードポイントを組み合わせて1つの文字にすることができるのです。
例えば、このEmoji 👨👩👧👦 について、JavaScriptで '👨👩👧👦'.length を実行すると、驚くべきことに結果は 11 になります。Emoji Spliter で分解してみると、見た目は1つのEmojiですが、実際には以下のような要素で構成されていることがわかります:
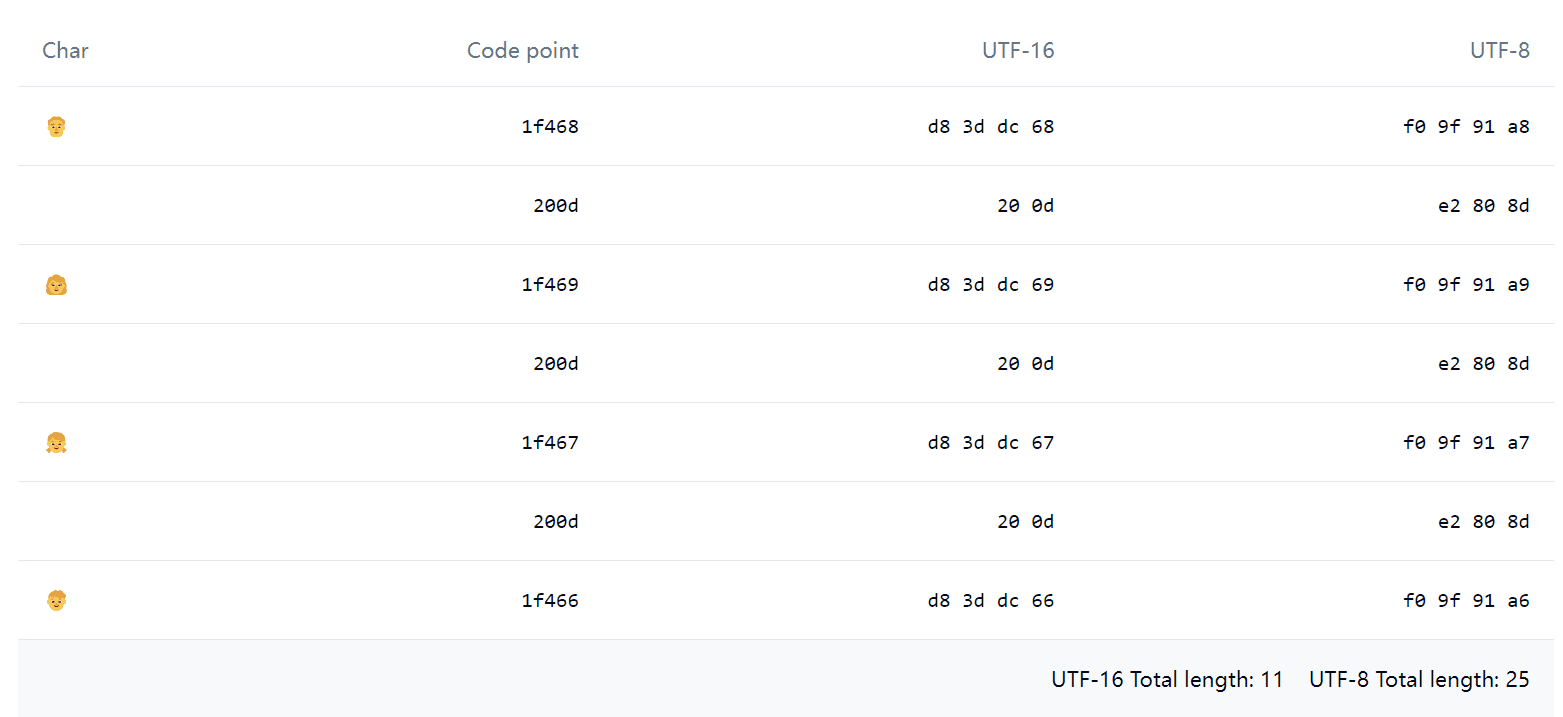
その中で 0x200d は Zero-width joiner(略称ZWJ)と呼ばれ、ZWJはいくつかのEmojiを結合して1つにまとめることができます。例えば、上記の一家四人に見える 👨👩👧👦 は、実際に一家四人の4つのEmojiを含んでいます。Emoji以外にも、一部の人間の言語でもZWJが使用されています。
エンコーディングからフォントへ
バイナリエンコーディングから文字を表示するまでに、もちろんフォント(font)も欠かせません。コンピュータにシステムをインストールする際、いくつかのフォントが付属しています。これは必須で、そうでなければレンダリング時にエンコーディングに対応する文字が見つからず、白い長方形が表示されることになり、これは「Tofu(豆腐ブロック)」と呼ばれます。GoogleのNotoフォントの名前の一つの意味は、コンピュータにTofuが現れないようにすることですが、願いは良いものの、実際には NotoはCJK Ext-Bをサポートしていません。
現在一般的なフォントには ttf、otf、woff、woff2 があります。
ttf(TrueType Font)と otf(OpenType)の主な違いは、otfが3次ベジェ曲線を使用するのに対し、ttfは2次ベジェ曲線を使用することです。また、ttfの hinting の方が優秀で、低解像度のマシンでのレンダリングがより美しくなります。
woff(Web Open Font Format)は実際にはttfのコア部分をzlib圧縮したもので、woff2 も同様ですが、圧縮アルゴリズムが Brotli に更新されています。
システムがエンコーディングから文字を見つける必要があるため、当然ながら、フォントはエンコーディングから文字へのマッピングを維持する必要があります。そのため、以前はフォント名の後に gbk と表記される場合があり、これは gbk エンコーディングシステム専用のフォントでした。現在では言うまでもなく、すべてUnicodeになっているでしょう。
CJK文字(および一部の西洋文字)については、同一のコードポイントが異なる地域で異なる字形(glyph)を持ちます。同じ意味の文字(grapheme)を各言語ごとにエンコードするのではなく、この状況は Han unification と呼ばれ、主にエンコーディング空間を節約するためです。注目すべきは、中国語の漢字の繁体字と簡体字は同一のコードポイントに統合されていないため、繁簡変換はフォントの変更ではなく、繁簡マッピングテーブルが存在することです。

虽然有资料表明单个字体可以按不同区域显示不同的字形,但是实际上字体提供者都会分语言打包字体,因为将所有语言所有字符塞到一起太大了,尤其是对于网页使用的字体,打开页面要等待几十兆的字体下载体验会非常难受。
举个例子,在下载 Noto-cjk 时,会推荐你按地区下载。如果非要下载 CJK 整个包,下载下来是一个 ttc 文件,实际上它也是多个 ttf 文件的集合,一个包整合了多个区域的异体字。
<td lang="zh-Hans">关</td><td lang="zh-Hant">关</td><td lang="zh-Hant-HK">关</td><td lang="ja">关</td><td lang="ko">关</td>ブラウザは lang の指示に従って各言語のデフォルトフォントでこれらの文字をレンダリングするため、異なる言語間の字形の違いを見ることができます。ただし注意すべきは、ウェブページのフォントが特定の言語のフォントに設定されており、そのフォントが現在の文字にヒットした場合、ブラウザは他の言語のデフォルトフォントにフォールバックしないということです。例えば、Microsoft YaHeiは中国語簡体字のデフォルトフォントですが、明示的に font-family: Microsoft YaHei を設定した場合、lang を何に設定しても中国語簡体字の字形が使用されます。
フォントのその他の機能

ある日Googleドキュメントでこのような奇妙なアイコンを発見しました。これをコピーすると元のテキスト(つまり文字列「block」)がコピーされます。実際、これは Material Symbols Outlined というフォントで、文字列をアイコンとして表示できるのは、合字(ligature)と呼ばれる技術を使用しているからです。簡単に言うと、特定の文字の組み合わせにマッチした時に、自動的に別の文字に置き換えられるということです。
FontForgeを使って合字の設定を確認することができます。メニューから Ligatures を見つけます:
詳細な設定を見ることができます:
Googleドキュメントのこのようなアイコンを合字として使用するのは、非主流の例と言わざるを得ません。より一般的な合字は、ラテン文字の fi、fl などの連字や、一部のコードエディタ専用フォントが !=、==、=> などの記号を連字にして、より美しく見せることです。
類似のフォント学の知識は他にも多くあります。もう一つの例を挙げると:フォントを使用したJavaScriptシンタックスハイライトの実装です。JavaScriptコードなし、余分な要素やCSSなし、純粋なフォント実装です。原理はフォントファイルで定義された Chaining Contextual lookup で、特定の順序の文字を検出した後、異なる色のバリアントに置き換えることだと思われます。
複雑なエンコーディングとプログラミング
Unicodeの大統一後、基本的にすべてのプログラミング言語の文字列はUnicodeエンコーディングになり、JavaScriptも同様です。しかし前述したように、Unicodeコード表はUTF-8、UTF-16、UTF-32にエンコードできますが、JavaScriptはメモリ内でUTF-16を使用しています。
charAt は皆さんが最初に接触する場面では、文字列内のN番目の文字そのものを取得することでしょう。
charCodeAt と codePointAt はどちらも文字のコードポイント(つまりcode point)を返します。しかし、codePointAt は完全なUnicodeコードポイントを返し、charCodeAt はその位置の単一のcode unit(コードポイントではありません!)の10進値を返します。ただし、0xffff 以内であれば、サロゲートペアの干渉がないため、codePointAt と charCodeAt は同じです。
例を挙げて、まず最も普通な 0xffff 以下のコードポイントの文字を見てみましょう:
"天".charAt(); // '天'"天".charCodeAt().toString(16); // '5929'"天".codePointAt().toString(16); // '5929'すべて正常です。
次に奇妙なサロゲートペアを見てみましょう:
"𪜹".charAt(); // '\uD869'"𪜹".charCodeAt().toString(16); // 'd869'"𪜹".codePointAt().toString(16); // '2a739'コードポイント値 0x2a739 は 0xffff を超えており、サロゲートペアを使用しているため、単一の charAt と charCodeAt は機能せず、UTF-16サロゲートペアの片方のみを返します。次の位を読み取るには "𪜹".charCodeAt(1).toString(16) を使用する必要があります。しかし、サロゲートペアの半分を読み取ることに一体何の意味があるのでしょうか 😂
幸い、codePointAt は正しく動作します。
最後に、上記で言及したさらに奇妙な組み合わせEmojiを見てみましょう:
"👨👩👧👦".charAt(); // '\uD83D'"👨👩👧👦".charCodeAt().toString(16); // 'd83d'"👨👩👧👦".codePointAt().toString(16); // '1f468'バフが満載としか言いようがありません。codePointAt は正しいですが完全ではなく、組み合わせの最初の文字(👨)のコードポイントしか返せません。charAt と charCodeAt も最初のサロゲートペアを返すだけです。
上記のテーブルを再度確認してみましょう:
| Char | Code point | UTF-16 | UTF-8 |
|---|---|---|---|
| 👨 | 1f468 | d8 3d dc 68 | f0 9f 91 a8 |
| | 200d | 20 0d | e2 80 8d |
| 👩 | 1f469 | d8 3d dc 69 | f0 9f 91 a9 |
| | 200d | 20 0d | e2 80 8d |
| 👧 | 1f467 | d8 3d dc 67 | f0 9f 91 a7 |
| | 200d | 20 0d | e2 80 8d |
| 👦 | 1f466 | d8 3d dc 66 | f0 9f 91 a6 |
JavaScriptの文字操作はcode unit単位(バイト単位ではなく)で計算されているようです。(UTF-16のcode unitは16ビット、UTF-8は8ビット、UTF-32は当然32ビットで、これは実際に1つの文字を構成する最小の組み合わせの長さです)
つまり、'👨👩👧👦'.length が 11 である理由は、11組のUTF-16コードがあるからです。プログラミング言語の文字列がメモリ内でUTF-8を使用している場合、例えばRustでは、長さはさらに異常な 25 になります……
良いニュースは、CJK文字は多く見えますが、実際には常用文字もBMP内にあり、上記の状況が発生することは稀だということです。Emojiについては……一般的に厳密な操作は関係ないでしょう。とにかくサロゲートペアと組み合わせ文字のおかげで、これらの文字操作には多くの直感に反する結果があることを注意喚起します。
CSSとHTMLのUnicodeエンコーディング関連の小知識については、数年前の古い記事をご覧ください。
用語
- code point:コードポイント、符号点
- code unit:コードユニット
- surrogate pair:サロゲートペア、UTF-16エンコーディングを補助するために使用
- grapheme:字素、一つの意味を表す文字
- glyph:字形