大家都知道计算机储存信息,本质上都是在储存 0 和 1,如果是数字比较容易理解,二进制转为十进制,或者用上科学计数法。但是到底计算机是怎么让一堆 0 和 1 显示成人类可读的文字呢?看完本文,大家应该就懂了😉
前置知识
与其说是前置知识不如说是一些提醒:
- 1 bit 就是 1 个
1或0 - 1 byte = 8 bit
- 1 byte 的可能性就是
0b00000000到0b11111111 - 于是 1 byte 可以表达 2 的 8 次方也就是 256 个数字
- 十六进制是记录 byte 很好的格式
- 与其用二进制,更常用
0x00到0xff可以表示 1 byte 的内容
码表的起源
码表(Character Encoding Table)是很容易理解的概念,完全就是一个数值对应一个字符。暂时我们可以粗略地认为,你能在电脑看到的字符,就是这么从这么个表格规定的映射从一堆 0 和 1 转换成你能看到的文字。
最广为人知最原始的码表是 ASCII。
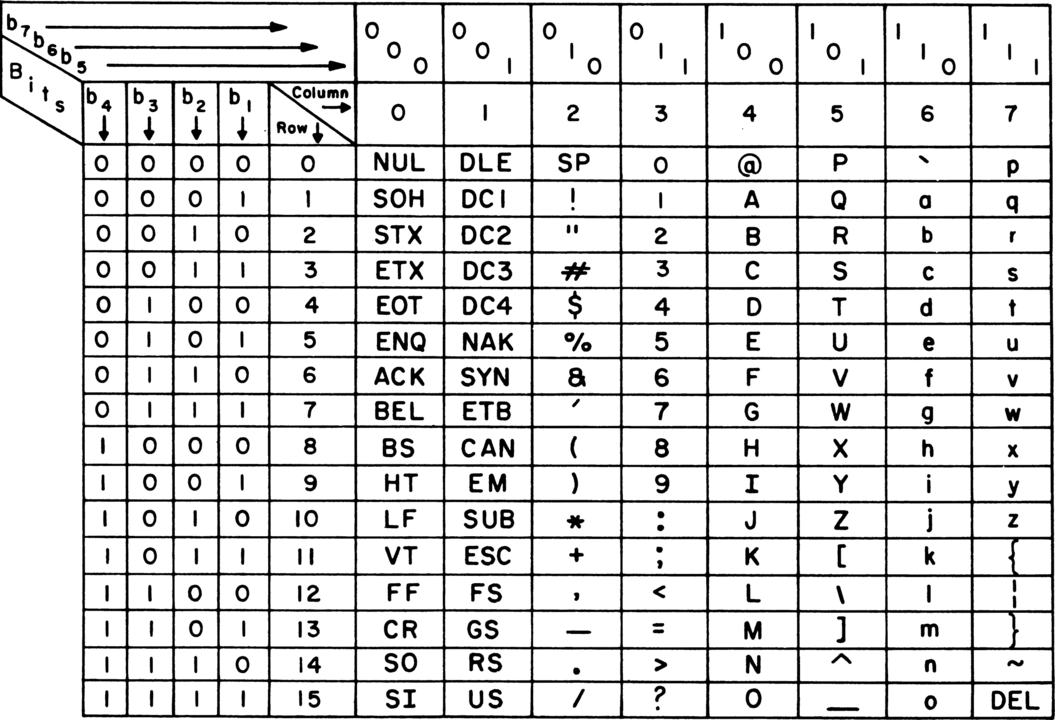
从发电报开始,ASCII 就初露头角。如你所见,最初 ASCII 只有 7 位(bit),当年为了节省带宽确实会用 7 位,但是这个数值对计算机来说不太友好,所以后来还是改成 8 位,也就是 1 字节(byte)。
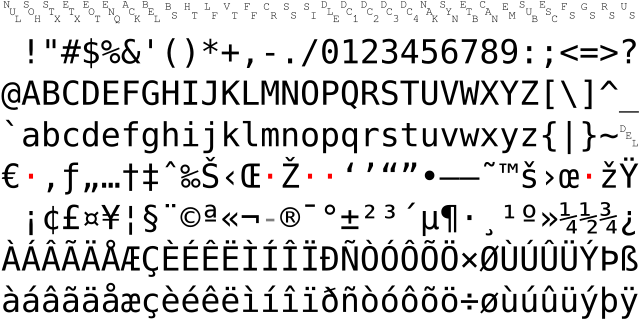
既然多了 1 位,那就很有理由继续扩充 ASCII 表咯,于是产生了两种广泛传播的 8 位的扩展 ASCII 表:ISO-8859-1 和 Windows-1252。这两种扩展表的扩展部分不尽相同,但都是填充欧美使用的字母例如:å æ ç è é 等等。
计算机发源于美国,但最终走向全世界,如果只能显示英文,那怎么够呢?对使用表音文字的欧美各国,这个情况很好解决,但使用表意文字的中日韩(简称 CJK)就很成问题。于是各个国家都制定了适合本国文字的码表,这些码表都在兼容 ASCII 的基础上添加本国文字。例如中国的 GBK 和 Big5、日本的 Shift-JIS、韩国的 EUC-KR、越南的 VISCII 等等。
对于 ASCII,本身就只有 256 个码,1 个字节轻松表示,但是,各种扩展集都超过了 256,再就变成了 2 个字节表示 1 个字……这时候大家看出问题了吗?
如果仅仅按数字顺序排列的话,编码第 257 个值就会变成一个 0x00 和一个 0xff,那么系统就根本不知道你这到底是 1 个字符还是 2 个字符。所以要编码大量文字就必须有一个明确标志告诉系统一个字的字节数。对于 GBK,会规定小于 0x7f 为单字节,再往上的均为双字节。有了这个规定,系统就知道 0x81 必不会单个字节成字符,会多读一个字节再找到码表对应的字符。
例如 GBK 的 A 是兼容 ASCII 的 0x41,而 我,是 0xce 0xd2,前面的字节大于 0x81,于是再读一个字节构成 我。同理可得,Shift-JIS 等其他国家的编码也是这个操作。
其实这么不同地区不同码表真不是办法,这会造成 21 世纪初网民很常见的一个问题:乱码。接收到其他地区的文件,在自己电脑打开看到一串看不懂的东西,这是当然的,一个来自日本的文本,本身编码使用的是 Shift-JIS,但是来到海的另一边,解码方式却是 GBK,这两个码表,能对上才怪。Shift-JIS 语一句 こんにちは 来到 GBK 的地盘变成了 偙傫偵偪偼,GBK 的一句 你好 到岛国变成 ト羲テ,别说语言不通,这甚至是加密通话。
想体验上面描述的转码奇妙体验可以来这里玩玩,毕竟近 10 年已经基本上不会遇到这种问题了。但是为什么呢?
因为我们伟大的 Unicode 统一了所有编码,大一统的时代来啦!
Unicode
Unicode 是集合了地球上所有语言字符的一个表格,从此,我们不再需要分不同编码方式了,统一使用 Unicode 编码。
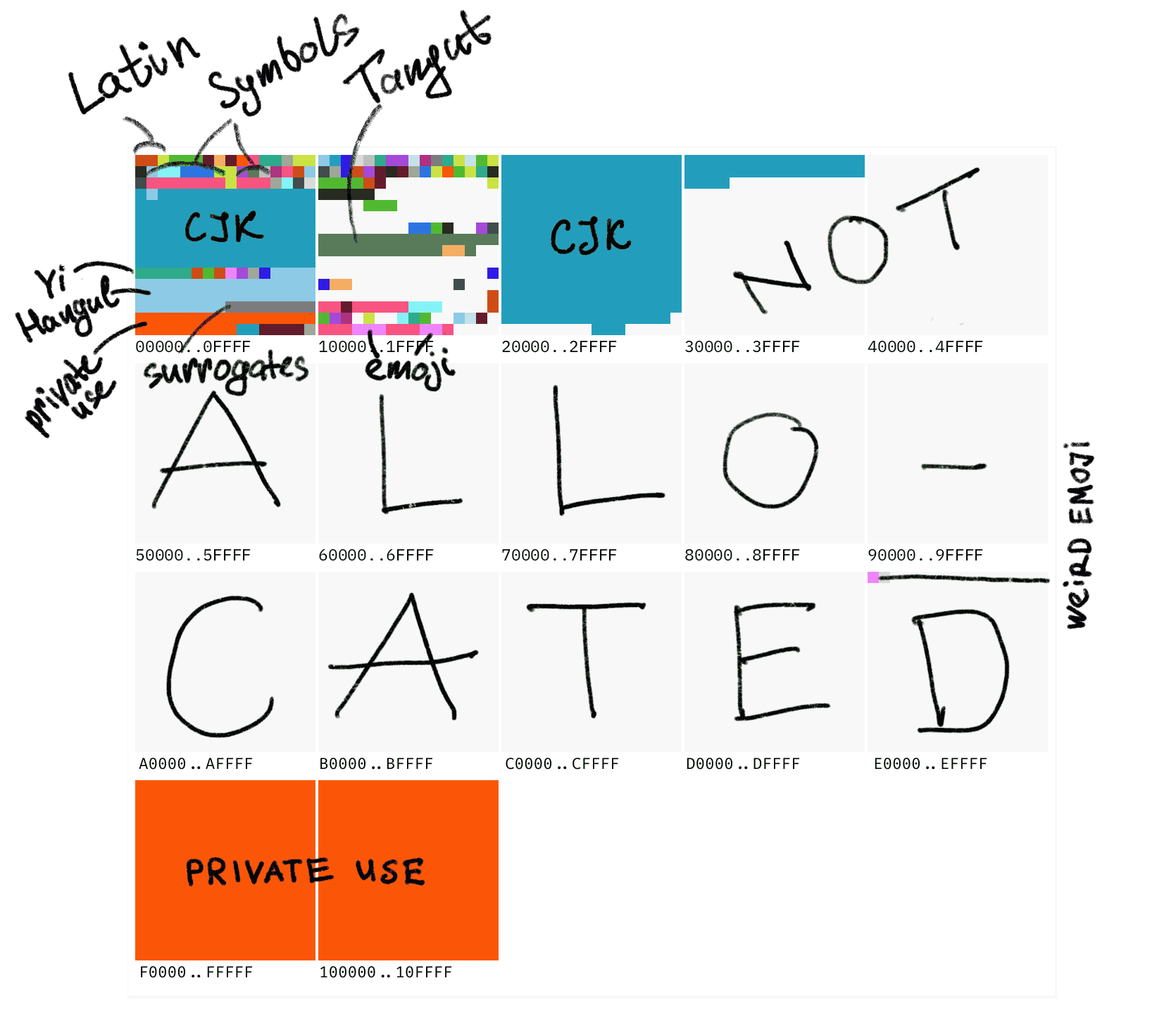
Unicode 有 10FFFF 个(也就是 1114111)码点(code point)。其中最重要的是前 0000 到 ffff 个码点,这个范围被称为基本多语言平面(Basic Multilingual Plane 缩写 BMP),后面也是每 65536 个点一个平面,共 17 个平面。占大头的还是 CJK 表意文字,并且整个码表现在其实还有大量空位。
偷大佬一个很直观的图,包含世界上所有常用文字的 BMP 仅仅是 Unicode 的第一小块:
最开始,我说可以粗略地认为“码”到“字”是不经过转换的简单的 1 对 1 关系,但是看到这里,是时候进阶了。Unicode 具有“码点”和“编码”两层概念。
简单来说,从 Unicode 编码到 UTF-8 的方法是把码点分成 4 个区间,不同区间采取不同的编码方式:
| Code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
0000..007F 也就是标准 ASCII,编码为 1 个字节,而最后面的部分 10000..10FFFF 会被拆开四份编码为 4 个字节。
同样的一套码点,Unicode 可以编码成 UTF-16。编码成 UTF-16 之后所有字符都稳定在 16 位,也就是最多可以表示 65536 个字符(也就是 BMP 范围)。UTF-16 最致命的一点是因为所有字符都被编码成 16 位,所以不支持最原始的 ASCII。
另外对 UTF-16 额外有代理对(surrogate pair)的概念,因为 Unicode 会超过 FFFF 所以再往上不能保证 2 字节定义一个字符,所以要根据一定规则转为 4 字节。虽然 UTF-16 不是常用文件的编码方式,但如果你使用 JavaScript,它的字符串在内存中就是 UTF-16 编码的,后面在编程部分会再细讲一下。
一个码表包含了所有字符,包括很多可爱的 Emoji,看起来很美好,但实际上 Unicode 有个很奇葩的地方:10FFFF 并不是 Unicode 能表示的字符的上限,Unicode 可以把多个码点组合成 1 个字符。
例如这个 Emoji 👨👩👧👦,如果使用 JavaScript 运行 '👨👩👧👦'.length,结果会是惊人的 11,用 Emoji Spliter 拆开,会发现这看起来只有 1 个 Emoji,实际上却是由下面这一堆东西组成的:
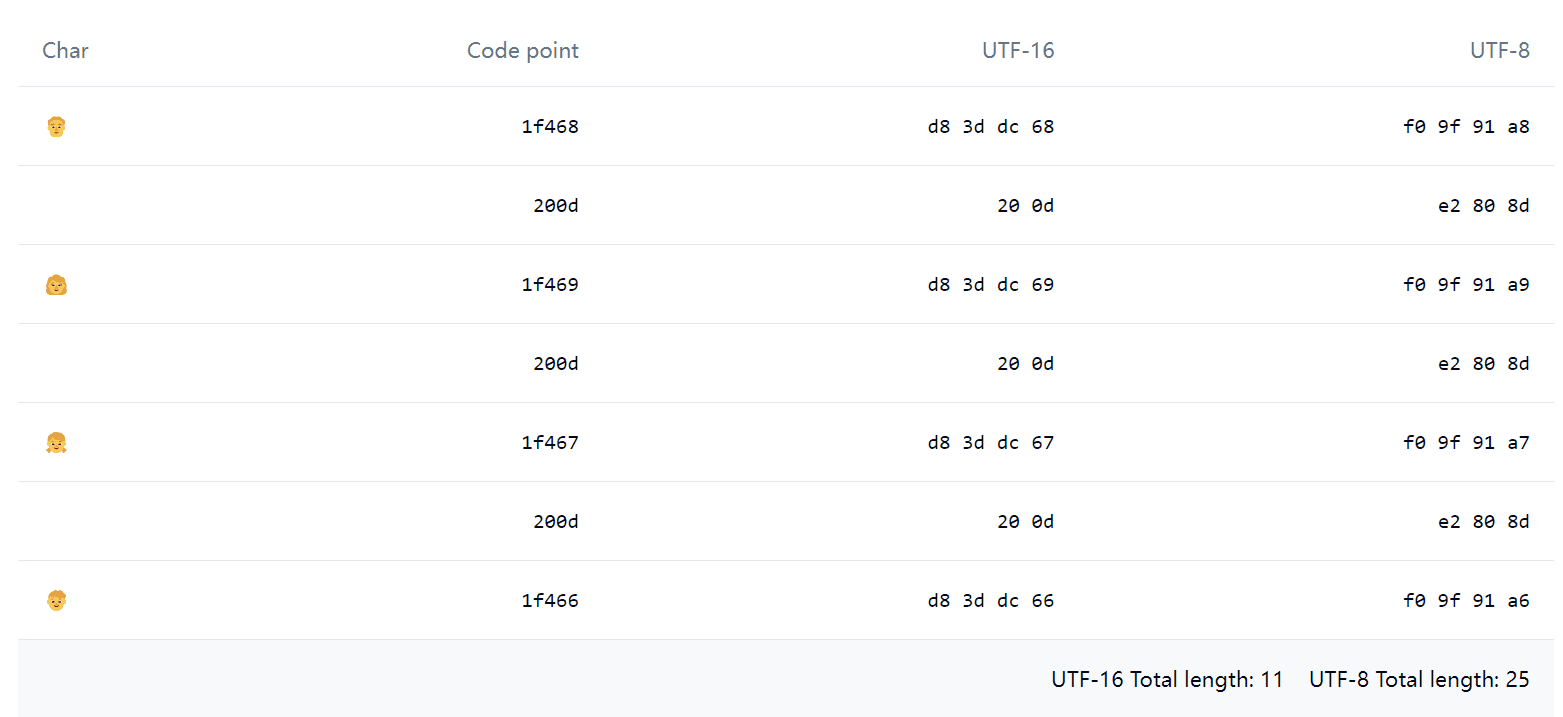
其中 0x200d 被称为 Zero-width joiner(简称 ZWJ),ZWJ 可以把一些 Emoji 粘起来组合成一个,例如上面看起来一家四口的 👨👩👧👦 实际上真就是包含了一家四口的 4 个 Emoji。除了 Emoji,有一些人类语言也会用到 ZWJ。
从编码到字体
从二进制编码到显示出一个字符,必不可少的当然还有字体(font)。电脑安装系统时会自带一些字体,这是必须的,否则渲染时找不到编码对应的字,就会显示一个白色长方形,被称为 Tofu“豆腐块”。谷歌的 Noto 字体其名称的一层含义就是让电脑不会出现 Tofu,虽然愿景很好,但是其实 Noto 并没支持 CJK Ext-B。
现在常见的字体有 ttf、otf、woff、woff2。
ttf(TrueType Font)和 otf(OpenType)主要区别是 otf 使用三次贝塞尔曲线,而 ttf 使用二次贝塞尔曲线。另外 ttf 的 hinting 会优秀一点,在分辨率低的机器上渲染起来会好看点。
woff(Web Open Font Format)其实就是 tff 的核心部分进行 zlib 压缩,woff2 也是类似,不过压缩算法更新为 Brotli。
因为系统需要从编码找到文字,所以很自然,字体必须维护编码到文字的映射。所以以前会有字体后面标注 gbk 的情况,就是 gbk 编码系统专用的字体,现在就不用说了,应该全是 Unicode 了吧。
对于 CJK 字符(以及部分西方字符),同一个码点在不同地区,拥有不同字形(glyph)。而不是为每种语言都编码一个相同含义的字(grapheme),这种情况被称为 Han unification,主要是为了节省编码空间。值得注意的是,基于中文的汉字繁体和简体没有被归到同一个码点,所以繁简转换并非更换字体而是存在一个繁简映射表。

虽然有资料表明单个字体可以按不同区域显示不同的字形,但是实际上字体提供者都会分语言打包字体,因为将所有语言所有字符塞到一起太大了,尤其是对于网页使用的字体,打开页面要等待几十兆的字体下载体验会非常难受。
举个例子,在下载 Noto-cjk 时,会推荐你按地区下载。如果非要下载 CJK 整个包,下载下来是一个 ttc 文件,实际上它也是多个 ttf 文件的集合,一个包整合了多个区域的异体字。
<td lang="zh-Hans">关</td><td lang="zh-Hant">关</td><td lang="zh-Hant-HK">关</td><td lang="ja">关</td><td lang="ko">关</td>浏览器会遵循 lang 的指示使用各个语言的默认字体渲染这些文字,于是你就能看到不同语言间的字形差异了。不过注意,如果你的网页字体被设置为某一语言的字体,且字体命中了当前字符浏览器就不会回退到其他语言的默认字体,例如微软雅黑,是中文简体的默认字体,如果显式设置了 font-family: Microsoft YaHei,那么无论你 lang 设置为什么都会使用中文简体字形。
字体的其他能力

一天看谷歌文档发现了这种奇怪的 ICON,在复制他的时候会复制出原本的文字(也就是字符串 block)。事实上这是一款叫做 Material Symbols Outlined 的字体,他之所以能让一串字符显示出图标,是使用了一种被称为连字(ligature)的技术。简单来说就是匹配到一组字符的时候,会被自动替换为另一个字符。
我们可以借助 FontForge 查看到连字配置,在菜单找到 Ligatures:
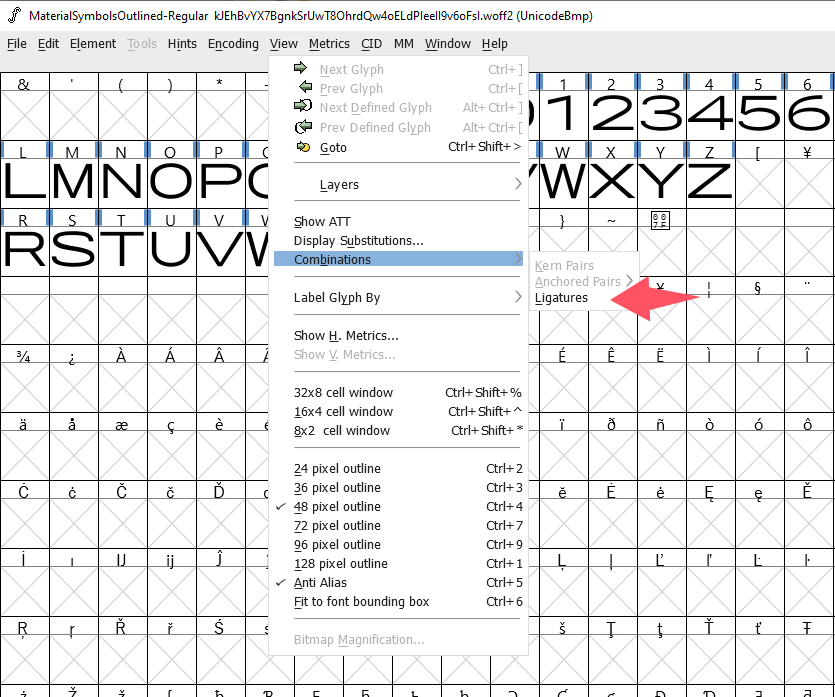
就能看到详细配置:
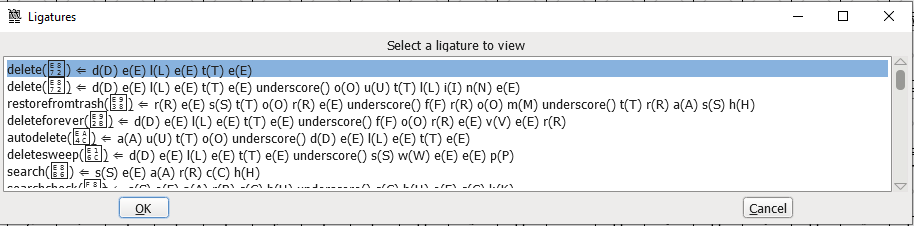
谷歌文档这种 ICON 当连字不得不说是个非主流例子,更常见的连字是拉丁字母 fi、fl 等的连写,以及一些代码编辑器专用字体会把 !=、==、=> 等符号连写,使其看起来更美观。
类似的字体学问还有很多,再举一个例子:使用字体实现 JavaScript 高亮显示,无 JavaScript 代码,无多余元素和 CSS,纯粹的字体实现。原理应该是字体文件定义的 Chaining Contextual lookup,查出特定顺序的字符后替换为不同颜色的变体。
复杂编码与编程
在 Unicode 大一统之后,基本所有编程语言的字符串都是 Unicode 编码,JavaScript 也是如此。但之前也说过,一套 Unicode 码表可以编码成 UTF-8、UTF-16、UTF-32,而 JavaScript 在内存中使用的是 UTF-16。
charAt 大家最早接触到的情况应该是获取字符串里的第 N 个字符本身。
charCodeAt 和 codePointAt 都返回字符的码点(也就是 code point)。但是 codePointAt 会返回完整的 Unicode 码点,charCodeAt 会返回那个位置的单个 code unit(不是码点!)的十进制值。不过在 0xffff 内的话 codePointAt 和 charCodeAt 是一样的,因为没有代理对的干扰。
上例子,先看最普通的码点 0xffff 以下的字符:
"天".charAt(); // '天'"天".charCodeAt().toString(16); // '5929'"天".codePointAt().toString(16); // '5929'一切正常。
然后看看奇葩的代理对:
"𪜹".charAt(); // '\uD869'"𪜹".charCodeAt().toString(16); // 'd869'"𪜹".codePointAt().toString(16); // '2a739'码点值 0x2a739,超过 0xffff,使用了代理对,于是单个 charAt 和 charCodeAt 都失效了,只返回了 UTF-16 代理对中的其中一组,必须用 "𪜹".charCodeAt(1).toString(16) 才能把下一位读出来。不过真想吐槽一句,把代理对的一半读出来到底有什么意义 😂
不过还好,codePointAt 都还是正确的。
最后看看上面提到的更奇葩的组合 Emoji:
"👨👩👧👦".charAt(); // '\uD83D'"👨👩👧👦".charCodeAt().toString(16); // 'd83d'"👨👩👧👦".codePointAt().toString(16); // '1f468'只能用 buff 叠满来形容。codePointAt 是对的但也没全对,只能返回组合中的第一个字符(👨)的码点,charAt 和 charCodeAt 也就返回第一代理对。
再来回顾一下上面的 table:
| Char | Code point | UTF-16 | UTF-8 |
|---|---|---|---|
| 👨 | 1f468 | d8 3d dc 68 | f0 9f 91 a8 |
| | 200d | 20 0d | e2 80 8d |
| 👩 | 1f469 | d8 3d dc 69 | f0 9f 91 a9 |
| | 200d | 20 0d | e2 80 8d |
| 👧 | 1f467 | d8 3d dc 67 | f0 9f 91 a7 |
| | 200d | 20 0d | e2 80 8d |
| 👦 | 1f466 | d8 3d dc 66 | f0 9f 91 a6 |
看起来 JavaScript 的 char 操作就是以 code unit 为单位(而不是以字节为单位)计算。(UTF-16 的 code unit 是 16 bit,UTF-8 是 8,UTF-32 自然是 32,这其实就是组成一个字符的最小组合的长度)
所以呢,'👨👩👧👦'.length 是 11 的原因就是有 11 组 UTF-16 码。如果一个编程语言字符串在内存中使用的是 UTF-8 的话,例如 Rust,那长度就是更变态的 25……
不过好消息是,看起来 CJK 字符很多,但是其实常用字也都在 BMP 内,很少发生上面提到的情况,至于 Emoji……一般也不涉及什么严谨的操作吧。总之拜代理对和组合字符所赐在这些字符操作上会有很多反直觉的结果,谨此提醒。
还有 CSS 和 HTML 与 Unicode 编码相关的小知识可以看多年前一篇老文。
名词
- code point:码点、编码点、代码点
- code unit:代码单元
- surrogate pair:代理对,用于辅助 UTF-16 编码
- grapheme:字素,代表一个含义的字
- glyph:字形