How Do Characters Actually Appear on Your Computer Screen?
/ 12 min read
We all know that computers store information essentially as 0s and 1s. For numbers, this is relatively easy to understand—binary converts to decimal, or we can use scientific notation. But how exactly do computers transform a bunch of 0s and 1s into human-readable text? After reading this article, you should have a clear understanding! 😉
Prerequisites
Rather than prerequisites, these are more like helpful reminders:
- 1 bit is a single
1or0 - 1 byte = 8 bits
- 1 byte can range from
0b00000000to0b11111111 - Therefore, 1 byte can represent 2^8 = 256 different numbers
- Hexadecimal is an excellent format for representing bytes
- Instead of binary, we commonly use
0x00to0xffto represent 1 byte of content
The Origins of Character Encoding Tables
Character Encoding Tables are easy to understand—they’re simply mappings where each numerical value corresponds to a character. For now, we can roughly think of it this way: the characters you see on your computer are transformed from a bunch of 0s and 1s into visible text through mappings defined by these tables.
The most widely known and original encoding table is ASCII.
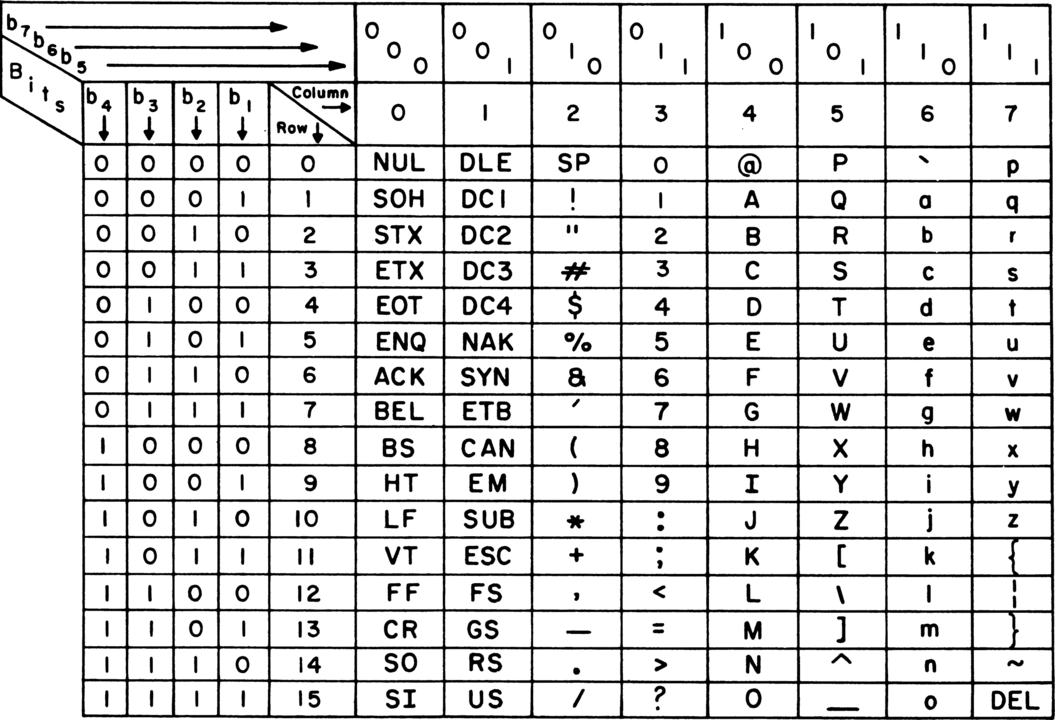
ASCII first emerged during the telegraph era. As you can see, ASCII originally used only 7 bits. Back then, 7 bits were indeed used to save bandwidth, but this wasn’t very computer-friendly, so it was later changed to 8 bits, which is 1 byte.
Since there was an extra bit available, it made sense to continue expanding the ASCII table. This led to two widely adopted 8-bit extended ASCII tables: ISO-8859-1 and Windows-1252. While the extended portions of these two tables differ, both were populated with letters used in Europe and America, such as: å æ ç è é, etc.
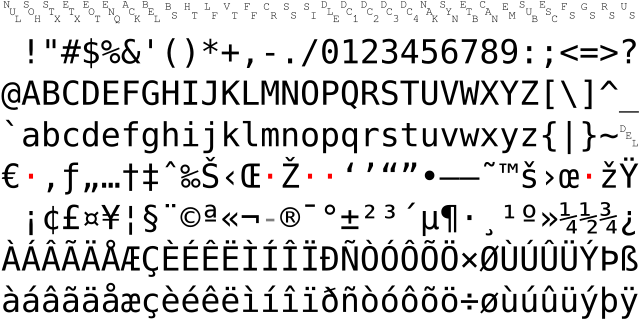
Computers originated in the United States but eventually spread worldwide. If they could only display English, how would that be sufficient? For European and American countries using phonetic scripts, this situation was easily resolved, but for China, Japan, and Korea (collectively known as CJK) using ideographic scripts, it became quite problematic. Consequently, each country developed encoding tables suitable for their own writing systems, all built upon ASCII compatibility while adding their national characters. Examples include China’s GBK and Big5, Japan’s Shift-JIS, Korea’s EUC-KR, Vietnam’s VISCII, and others.
For ASCII, there are only 256 codes, easily represented by 1 byte. However, various extended character sets exceeded 256, requiring 2 bytes to represent 1 character… Can you see the problem here?
If we simply arranged them in numerical order, the 257th value would become one 0x00 and one 0xff, leaving the system completely unable to determine whether this represents 1 character or 2 characters. Therefore, to encode large amounts of text, there must be a clear indicator telling the system how many bytes constitute one character. For GBK, values less than 0x7f are designated as single-byte, while anything above uses double-byte encoding. With this rule, the system knows that 0x81 cannot form a character by itself and will read an additional byte to find the corresponding character in the encoding table.
For example, GBK’s A is ASCII-compatible 0x41, while 我 is 0xce 0xd2. Since the first byte is greater than 0x81, the system reads an additional byte to form 我. Similarly, Shift-JIS and other national encodings operate the same way.
Having different encoding tables for different regions really wasn’t a solution. This caused a very common problem for internet users in the early 21st century: garbled text. When receiving files from other regions and opening them on your own computer, seeing a string of incomprehensible characters was perfectly normal. A text from Japan encoded in Shift-JIS, when decoded using GBK on the other side of the ocean, couldn’t possibly match up correctly. A Shift-JIS sentence こんにちは became 偙傫偵偪偼 in GBK territory, while a GBK sentence 你好 became ト羲テ in Japan. Forget about language barriers—this was practically encrypted communication.
If you want to experience the wonderful transcoding experience described above, you can try it here. After all, this problem has basically disappeared over the past 10 years. But why?
Because our great Unicode has unified all encodings—the era of grand unification has arrived!
Unicode
Unicode is a table that encompasses characters from all languages on Earth. From now on, we no longer need different encoding methods—we can uniformly use Unicode encoding.
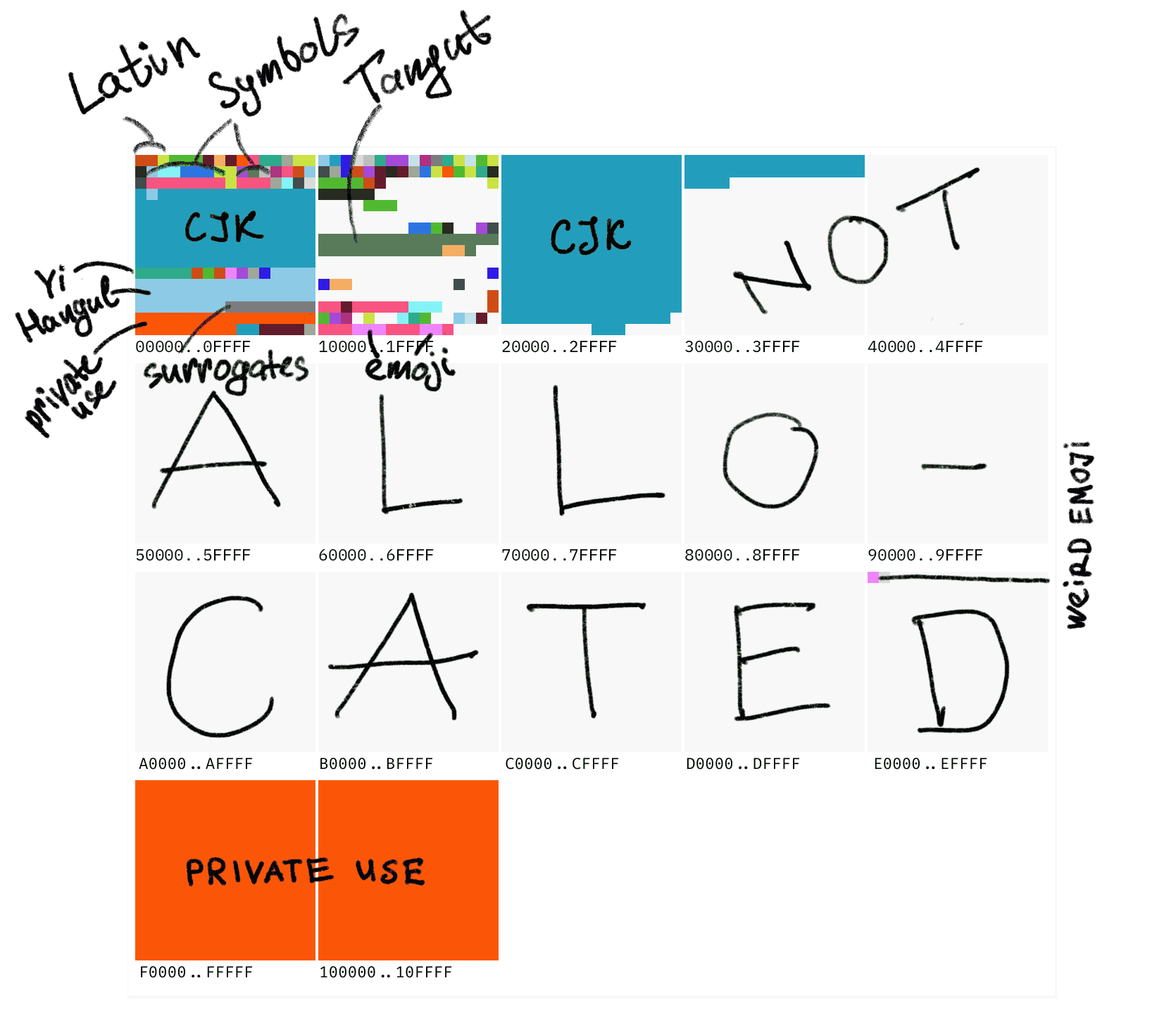
Unicode has 10FFFF (which is 1,114,111) code points. The most important are the first 0000 to ffff code points, a range called the Basic Multilingual Plane (abbreviated as BMP). Subsequently, every 65,536 points form one plane, totaling 17 planes. CJK ideographic characters still occupy the largest portion, and the entire code table actually still has plenty of vacant positions.
Borrowing a very intuitive diagram from this expert, the BMP containing all commonly used scripts in the world is merely the first small block of Unicode:
At the beginning, I said we could roughly consider the relationship from “code” to “character” as a simple 1-to-1 mapping without conversion, but having reached this point, it’s time to advance. Unicode has two layers of concepts: “code points” and “encoding”.
Simply put, the method for encoding Unicode to UTF-8 divides code points into 4 ranges, with different encoding methods for different ranges:
| Code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
0000..007F represents standard ASCII, encoded as 1 byte, while the final portion 10000..10FFFF is split into four parts and encoded as 4 bytes.
The same set of code points can be encoded as UTF-16 by Unicode. After UTF-16 encoding, all characters are stable at 16 bits, meaning it can represent at most 65,536 characters (i.e., the BMP range). UTF-16’s most fatal flaw is that because all characters are encoded as 16 bits, it doesn’t support the original ASCII.
Additionally, UTF-16 has the concept of surrogate pairs. Since Unicode extends beyond FFFF, you can’t guarantee that 2 bytes define one character beyond that point, so conversion to 4 bytes follows certain rules. Although UTF-16 isn’t a common file encoding method, if you use JavaScript, its strings are UTF-16 encoded in memory. I’ll elaborate on this in the programming section later.
A code table containing all characters, including many adorable Emoji, seems wonderful, but Unicode actually has a peculiar aspect: 10FFFF is not the upper limit of characters Unicode can represent. Unicode can combine multiple code points into 1 character.
For example, this Emoji 👨👩👧👦—if you run '👨👩👧👦'.length in JavaScript, the result will be a surprising 11. Using Emoji Splitter to break it down, you’ll discover that what appears to be just 1 Emoji is actually composed of the following collection of elements:
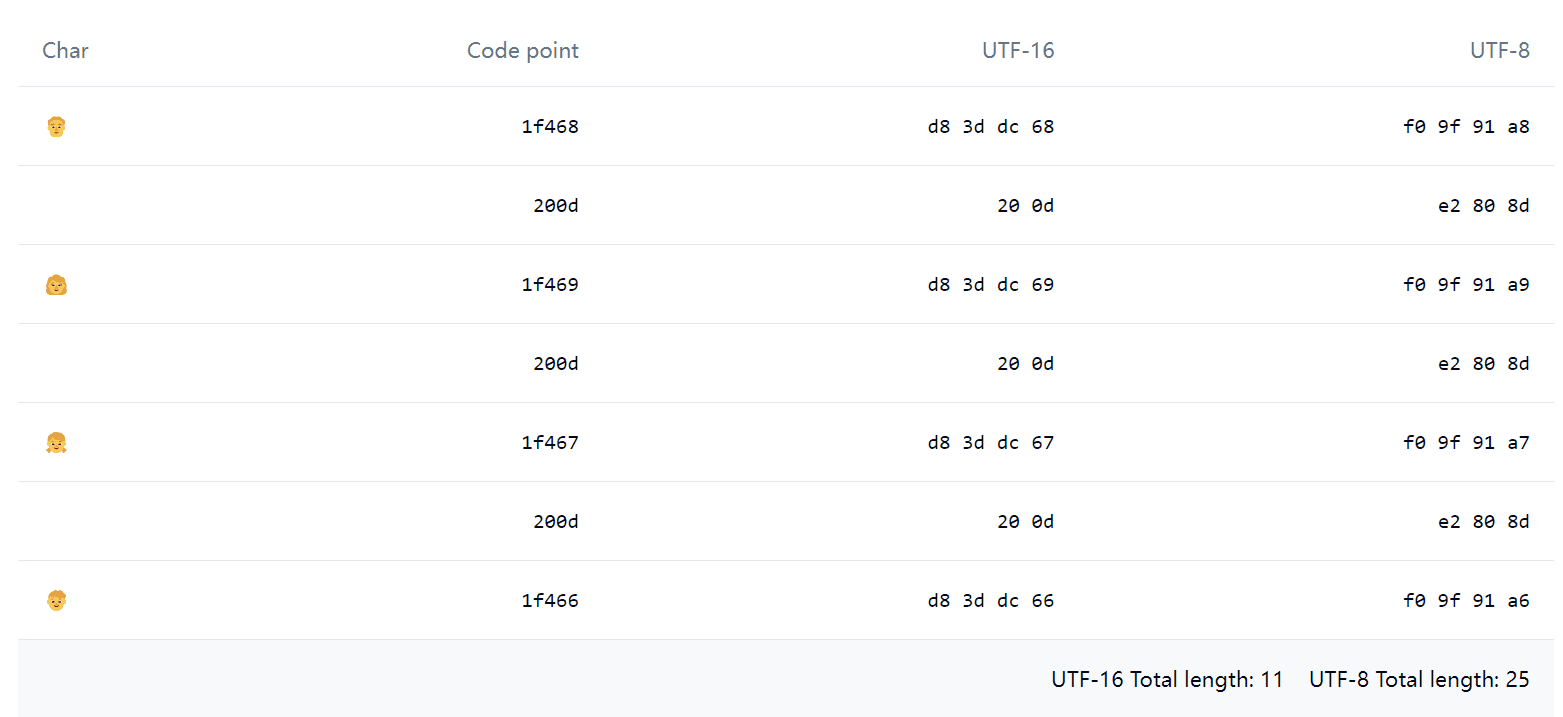
Among these, 0x200d is called the Zero-width joiner (abbreviated as ZWJ). ZWJ can stick some Emoji together to form a combination. For example, the family of four 👨👩👧👦 above actually contains 4 individual Emoji representing a family of four. Besides Emoji, some human languages also use ZWJ.
From Encoding to Fonts
To display a character from binary encoding, fonts are of course indispensable. Computers come with some fonts pre-installed when the system is installed—this is necessary, otherwise when rendering can’t find the character corresponding to the encoding, it will display a white rectangle, called “Tofu.” One layer of meaning behind Google’s Noto font name is to prevent computers from displaying Tofu. While the vision is admirable, Noto actually doesn’t support CJK Ext-B.
Common font formats today include ttf, otf, woff, and woff2.
The main difference between ttf (TrueType Font) and otf (OpenType) is that otf uses cubic Bézier curves while ttf uses quadratic Bézier curves. Additionally, ttf’s hinting is somewhat superior, rendering better on low-resolution machines.
woff (Web Open Font Format) is essentially the core part of ttf compressed with zlib, while woff2 is similar but uses the updated Brotli compression algorithm.
Since systems need to find characters from encodings, naturally, fonts must maintain encoding-to-character mappings. This is why fonts used to be labeled with gbk—they were fonts specifically for the gbk encoding system. Nowadays, needless to say, everything should be Unicode.
For CJK characters (and some Western characters), the same code point has different glyphs in different regions. Rather than encoding a character with the same meaning (grapheme) for each language, this situation is called Han unification, primarily to save encoding space. It’s worth noting that Chinese traditional and simplified characters are not assigned to the same code point, so traditional-simplified conversion isn’t about changing fonts but involves a traditional-simplified mapping table.

Although some sources indicate that a single font can display different glyphs for different regions, font providers actually package fonts by language because cramming all languages and all characters together would be too large, especially for web fonts—waiting for tens of megabytes of font downloads when opening a page would be extremely unpleasant.
For example, when downloading Noto-cjk, you’ll be recommended to download by region. If you insist on downloading the entire CJK package, what you get is a ttc file, which is actually a collection of multiple ttf files—one package integrating variant characters from multiple regions.
<td lang="zh-Hans">关</td><td lang="zh-Hant">关</td><td lang="zh-Hant-HK">关</td><td lang="ja">关</td><td lang="ko">关</td>Browsers will follow the lang directive to use each language’s default font for rendering these characters, allowing you to see glyph differences between languages. However, note that if your webpage font is set to a specific language’s font and that font matches the current character, the browser won’t fall back to other languages’ default fonts. For example, Microsoft YaHei is the default font for Simplified Chinese—if you explicitly set font-family: Microsoft YaHei, it will use Simplified Chinese glyphs regardless of what you set for lang.
Other Font Capabilities

One day while looking at Google Docs, I discovered this strange ICON—when copying it, it would copy the original text (i.e., the string “block”). This is actually a font called Material Symbols Outlined. The reason it can display icons from a string of characters is through a technology called ligatures. Simply put, when a group of characters is matched, it gets automatically replaced with another character.
We can use FontForge to view ligature configurations by finding Ligatures in the menu:
Then you can see the detailed configuration:
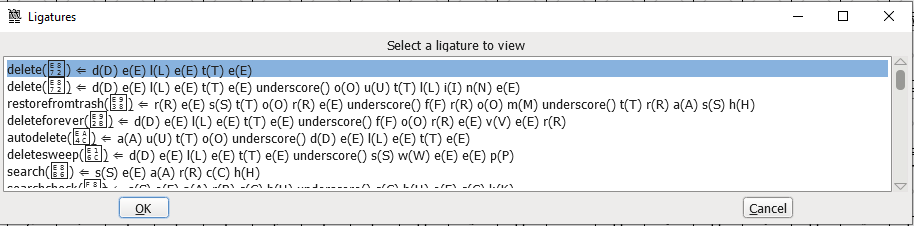
Google Docs’ use of ICONs as ligatures is admittedly a non-mainstream example. More common ligatures include Latin letter combinations like fi, fl, and some code editor-specific fonts that combine symbols like !=, ==, => to make them look more aesthetically pleasing.
There are many similar font techniques. Here’s another example: Implementing JavaScript syntax highlighting using fonts—no JavaScript code, no extra elements or CSS, purely font-based implementation. The principle should be Chaining Contextual lookup defined in the font file, which identifies specific character sequences and replaces them with different colored variants.
Complex Encoding and Programming
After Unicode’s grand unification, basically all programming languages use Unicode encoding for strings, and JavaScript is no exception. But as mentioned earlier, one set of Unicode code points can be encoded as UTF-8, UTF-16, or UTF-32, while JavaScript uses UTF-16 in memory.
charAt is probably the first method most people encounter for getting the Nth character itself from a string.
charCodeAt and codePointAt both return the code point of a character. However, codePointAt returns the complete Unicode code point, while charCodeAt returns the decimal value of a single code unit (not a code point!) at that position. Within 0xffff, codePointAt and charCodeAt are the same because there’s no surrogate pair interference.
Let’s look at examples, starting with ordinary characters below code point 0xffff:
"天".charAt(); // '天'"天".charCodeAt().toString(16); // '5929'"天".codePointAt().toString(16); // '5929'Everything works normally.
Now let’s look at the peculiar surrogate pairs:
"𪜹".charAt(); // '\uD869'"𪜹".charCodeAt().toString(16); // 'd869'"𪜹".codePointAt().toString(16); // '2a739'The code point value 0x2a739 exceeds 0xffff and uses surrogate pairs, so both charAt and charCodeAt fail, returning only one part of the UTF-16 surrogate pair. You’d need to use "𪜹".charCodeAt(1).toString(16) to read the next part. I really have to complain—what’s the point of reading half a surrogate pair? 😂
Fortunately, codePointAt is still correct.
Finally, let’s look at the even more peculiar composite Emoji mentioned above:
"👨👩👧👦".charAt(); // '\uD83D'"👨👩👧👦".charCodeAt().toString(16); // 'd83d'"👨👩👧👦".codePointAt().toString(16); // '1f468'This can only be described as maximum complexity stacking. codePointAt is correct but not completely—it can only return the code point of the first character (👨) in the combination, while charAt and charCodeAt just return the first surrogate pair.
Let’s review the table above:
| Char | Code point | UTF-16 | UTF-8 |
|---|---|---|---|
| 👨 | 1f468 | d8 3d dc 68 | f0 9f 91 a8 |
| | 200d | 20 0d | e2 80 8d |
| 👩 | 1f469 | d8 3d dc 69 | f0 9f 91 a9 |
| | 200d | 20 0d | e2 80 8d |
| 👧 | 1f467 | d8 3d dc 67 | f0 9f 91 a7 |
| | 200d | 20 0d | e2 80 8d |
| 👦 | 1f466 | d8 3d dc 66 | f0 9f 91 a6 |
It appears that JavaScript’s char operations are calculated in code unit terms (rather than byte terms). (UTF-16’s code unit is 16 bits, UTF-8 is 8, UTF-32 is naturally 32—this is essentially the minimum combination length that forms a character)
So, the reason '👨👩👧👦'.length is 11 is because there are 11 UTF-16 code units. If a programming language uses UTF-8 for strings in memory, like Rust, the length would be an even more outrageous 25…
The good news is that while CJK characters seem numerous, commonly used characters are actually all within the BMP, so the situations mentioned above rarely occur. As for Emoji… they generally don’t involve rigorous operations anyway. In any case, thanks to surrogate pairs and composite characters, there will be many counterintuitive results in these character operations—consider this a friendly reminder.
For additional knowledge about CSS and HTML related to Unicode encoding, you can check out an old article from years ago.
Terminology
- code point: A numerical value assigned to a character in Unicode
- code unit: The basic unit of encoding (16-bit for UTF-16, 8-bit for UTF-8, etc.)
- surrogate pair: A pair of code units used to represent characters beyond the BMP in UTF-16
- grapheme: A character unit representing one meaningful symbol
- glyph: The visual representation/shape of a character