
一、初认流
溪流绵延不绝,计算机科学的流也就如这个类比,是连续的数据传输。
为什么计算机科学需要流呢?主要有两点:
- 防止内存被撑爆
- 允许快速响应
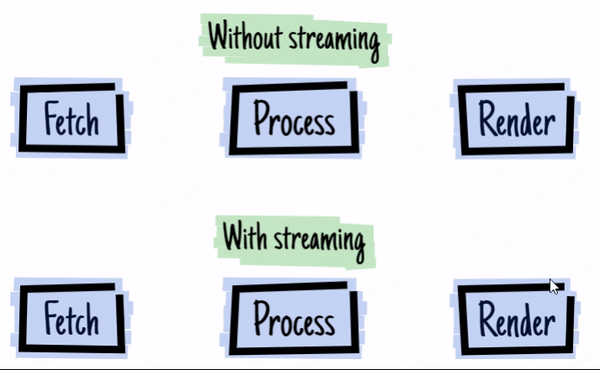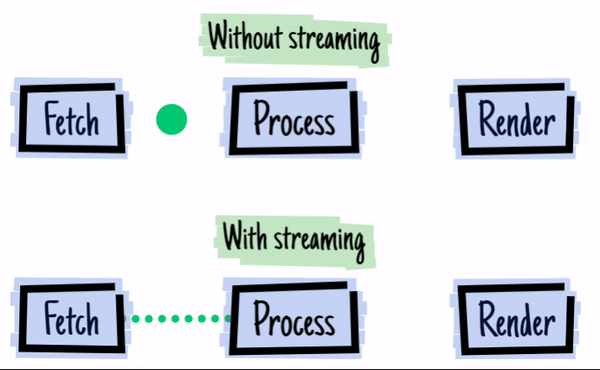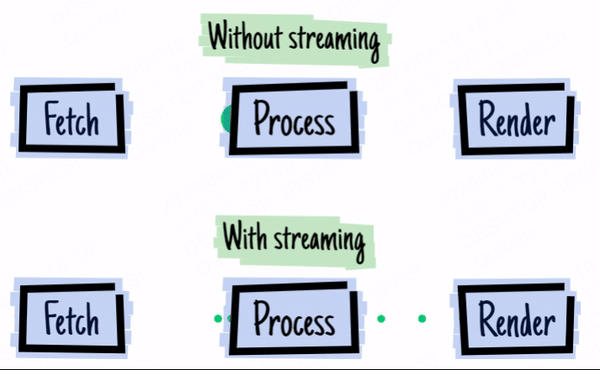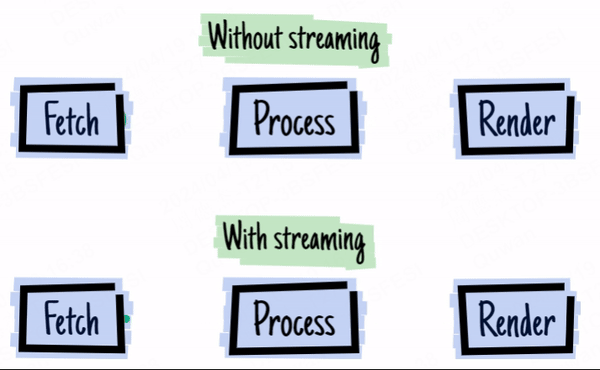
上图来源于 2016 - the year of web streams
举个现在大家都很熟悉的例子,gpt 的流式返回。LLM 的输出需要时间,而刚好 LLM 就是流式输出,那么一边输出一边直接发给你,你就能更快看到结果。
对于前端开发者,在 stream API 出现在浏览器前,我们无法对 Ajax 请求进行流式处理(除非迂回地使用 EventSource),这意味着我们对大型数据的请求就必须等待所有数据返回后才触发回调函数进行处理,这大大降低了用户体验。
所幸在 2016 年前后,终于更新了浏览器 stream API。除了 fetch 的流式返回,浏览器还有很多其他跟流相关的接口,例如:
二、流的基本构造
下面讲解最基础的两种流,可读流和可写流,我们可以通过 ReadableStream 和 WritableStream 构造实例。其他流相关的接口也是以此为基础,所以这两种流懂了,理解其他接口基本没有问题。
2.1 可读流
关键概念:
- 底层源:可以理解为真正产生数据的地方
- 队列策略(后面再详细说)
- 控制器:可读流的控制器,重点是
enqueue - reader:读取可读流的工具
const readableStream = new ReadableStream( { start(controller) { // 实例化时立即执行 // 主要是做一些事前准备 // 如果要在这里 enqueue 数据的话必须考虑 desiredSize },
pull(controller) { // 简单来说就是当队列有空余的时候,下游会从上游拉数据 // 这里说到队列策略再解释 controller.enqueue("chunk"); },
cancel(reason) { // 取消回调 }, }, new CountQueuingStrategy({ highWaterMark: 5 }), // 非必填);底层源会收到一个 controller 参数,它是一个 ReadableStreamDefaultController。
ReadableStreamDefaultController.desiredSize(挖个坑,后面队列策略细说)ReadableStreamDefaultController.close()ReadableStreamDefaultController.enqueue()ReadableStreamDefaultController.error()
我们可以使用 controller.enqueue 提供数据,enqueue 后数据会进入队列,供给 reader 消费。
流水没有边界,但是这种无限的概念显然不能存在于人类实现的系统。对于浏览器端的 stream api,流传输以 chunk(数据块)为单位分割。上面提到的 enqueue,它的参数就是一个 chunk。chunk 的类型一般是字符串、Uint8Array,但是普通的可读流不会限制 chunk 的类型,所以对象也是可以传的。(此处不讨论可读字节流)
下面讲 reader,使用 stream.getReader() 获取对应流的默认 reader,ReadableStreamDefaultReader 拥有以下属性和方法:
ReadableStreamDefaultReader.closedReadableStreamDefaultReader.cancel()ReadableStreamDefaultReader.read()ReadableStreamDefaultReader.releaseLock()
const reader = readableStream.getReader();
reader.read().then( ({ value, done }) => { if (done) { console.log("The stream was already closed!"); } else { console.log(value); } }, (e) => console.error("The stream became errored and cannot be read from!", e),);一旦一个可读流和一个 reader 关联,那么这个流就被锁定了,如果一个流需要同时被两个 reader 读取,可以使用 tee() 分流。

2.2 可写流
同样的,可写流的关键概念与可读流基本类似:
- 底层槽:数据真正的处理点,数据的归宿
- 控制器:主要用于关闭与报错
- writer:可写流的写入器
const writableStream = new WritableStream( { start(controller) { // 实例化时立即执行 // 主要是做一些事前准备 },
write(chunk, controller) { // chunk 写入的最终处理 },
close(controller) { // 关闭回调 },
abort(reason) { // 报错回调 }, }, new CountQueuingStrategy({ highWaterMark: 5 }),);与底层源类似,底层槽会收到一个 controller 参数,它是一个 WritableStreamDefaultController。这个控制器就没有可读流控制器那么多操作了,主要跟终止流有关。
WritableStreamDefaultController.signal终止 writer 的 signalWritableStreamDefaultController.error()引起错误,终止流
接着是 writer,使用 stream.getWriter() 获取对应流的默认 writer, WritableStreamDefaultWriter 拥有以下属性和方法:
WritableStreamDefaultWriter.closedWritableStreamDefaultWriter.desiredSize(挖个坑,后面队列策略细说)WritableStreamDefaultWriter.ready(同上)WritableStreamDefaultWriter.abort()WritableStreamDefaultWriter.close()WritableStreamDefaultWriter.releaseLock()WritableStreamDefaultWriter.write()通过 writer 写入数据
// https://streams.spec.whatwg.org/#example-manual-write-dont-awaitasync function writeSuppliedBytesForever(writableStream, getBytes) { const writer = writableStream.getWriter();
while (true) { await writer.ready;
const bytes = getBytes(); writer.write(bytes).catch(() => {}); }}三、转换流与管道操作
除了可读和可写流,还有一种用于数据处理的流,一般称为转换流。
我们可以使用 TransformStream 构造转换流,但是其实只要实现读写两端的都可以算是转换流。
const transformStream = new TransformStream( // 这块名为 transformer { start(controller) { /* … */ },
transform(chunk, controller) { /* … */ },
flush(controller) { /* 所有任务完成的收尾工作 */ }, }, writableStrategy, readableStrategy,);transform 兼有可写流的 chunk 和可读流的 controller.enqueue,就是一个中转站的感觉。
在使用转换流时,一般会借助“管道操作”函数。管道操作可以联通可读、可写和转换流。
pipeTo()把可读 pipe 到可写pipeThrough()把可读 pipe 到转换
举个例子,要实现 underlying source -> 转换 -> 转换 -> underlying sink 可以这么写:
readableStream.pipeThrough(transformStream1).pipeThrough(transformStream2).pipeTo(writableStream);四、队列策略
4.1 解析
队列策略就是之前提到构建可读流和可写流需要传入的第二个值。它通过 highWaterMark 指定了流的队列的大小,这个队列可以用于流之间的缓冲。值得注意的是,这个大小不是绝对限制,只是一种约定。
为什么需要队列策略呢?因为可读流和可写流之间处理数据的速度不是恒定的,在忽快忽慢的时候如果中间有队列作为缓冲可以提高处理效率。
粗略说有两种,一是按次数,二是按 size:
new CountQueuingStrategy({ highWaterMark: 1 })new ByteLengthQueuingStrategy({ highWaterMark: 1024 })- 不用 class,直接写对象
直接写对象的话大概长这样:
// ...{ highWaterMark: 1024, size(chunk) { return chunk.length },},// ...当队列满了,就该提示上一层慢一点,不然内存又要被挤爆了。
比喻一下就像倒水,下面盆子满了,再倒也倒不下了。这个情况我们称为背压,背压通过 desiredSize 给出“暗示”。
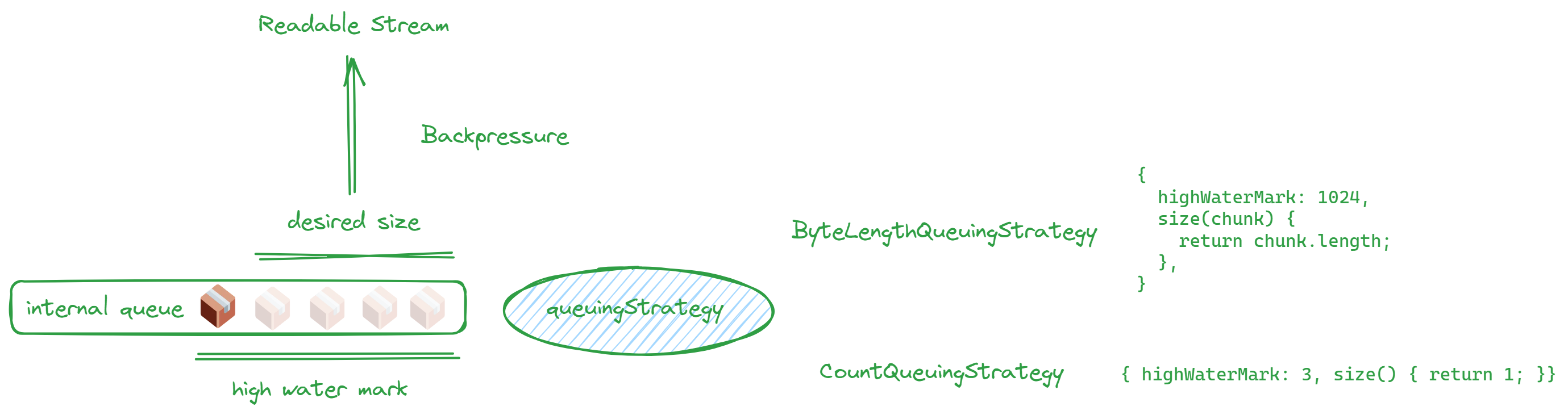
desiredSize 的计算方式是 high water mark - 内部队列的量。
回顾一下前面出现了两个 desiredSize:
ReadableStreamDefaultController.desiredSizeWritableStreamDefaultWriter.desiredSize
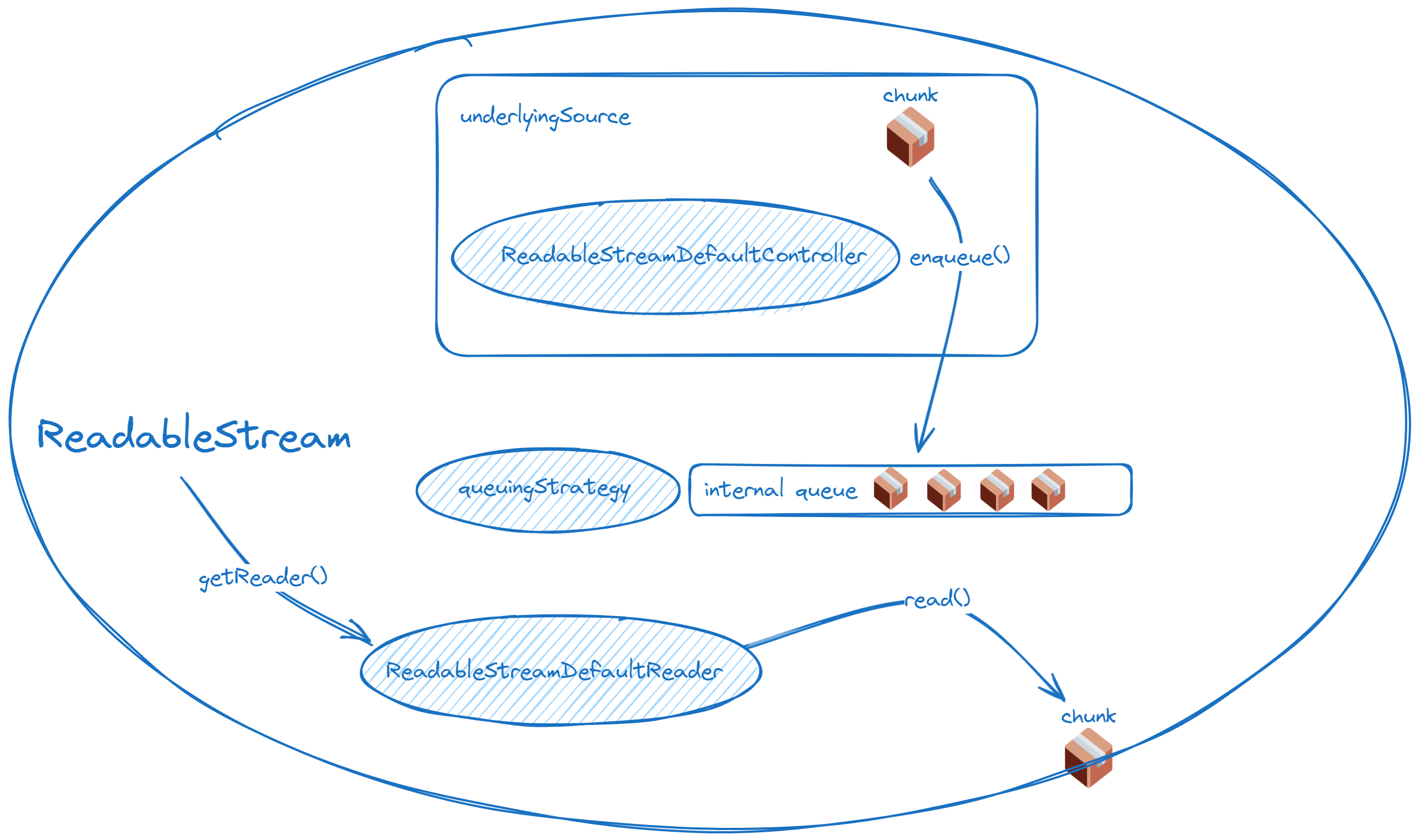
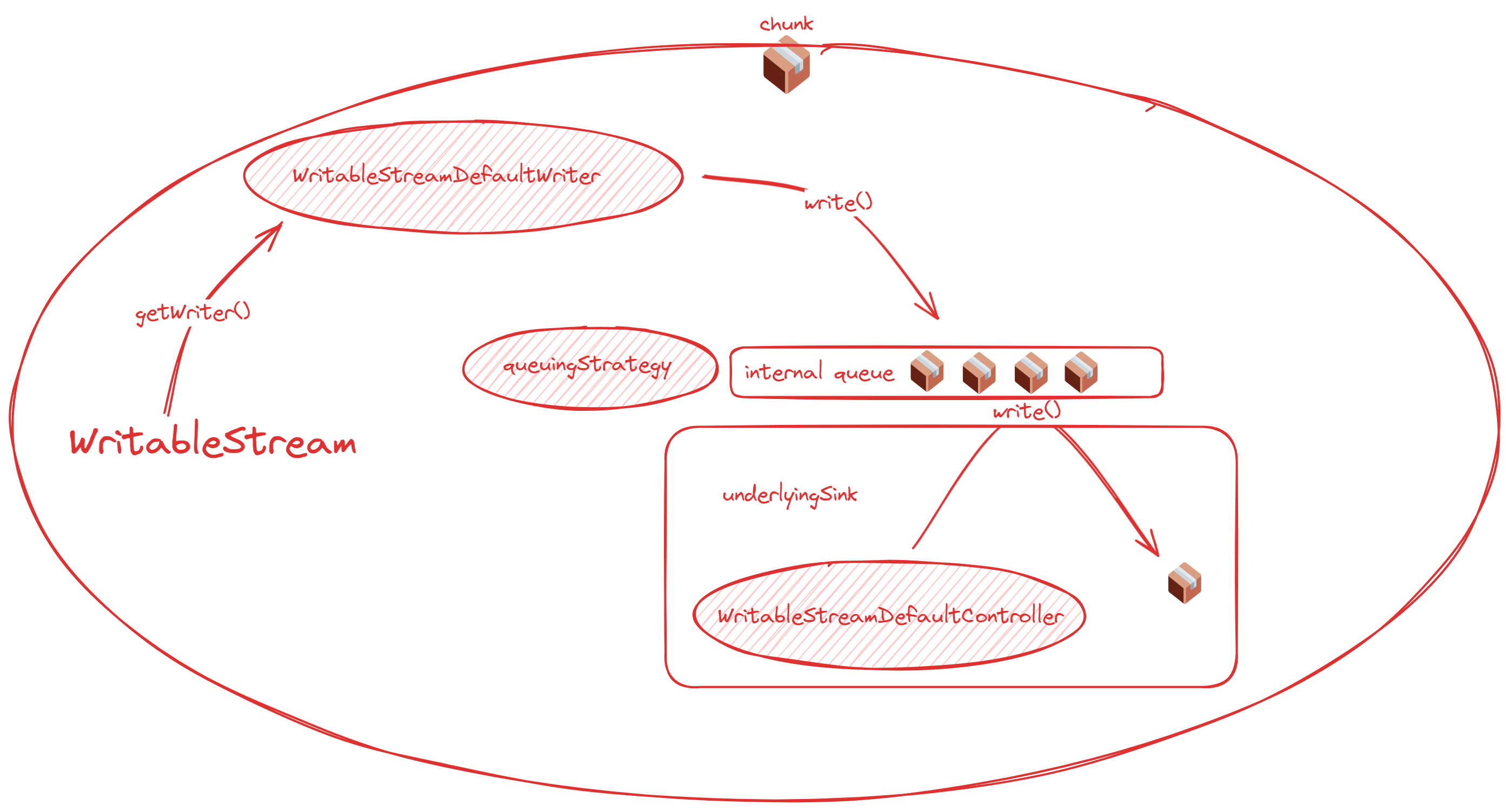
一个在可读的控制器,另一个在可写的写入器。你可能会很好奇,为什么一个在控制器,一个在写入器呢?我们看图,就懂了!
下面两张图总结读写流和队列的关系,清晰说明了队列到底存在于哪里。
可读流:
可写流:
对于可读端:内部队列有空余时,可读流的 pull 会被自动调用,直至达到 high water mark;如果使用在 start 定义数据的发生方式,应尽量在 desiredSize 为非正数时停止数据发生。
对于可写端:作为可写端一般不直接关注 desiredSize 的值,还记得 WritableStreamDefaultWriter.ready 吗?ready 时,desiredSize 就是正值。所以实现可写流时一般会 await writer.ready,这样就能正常运用队列了。
简单来说只要记住,底层源和底层槽必定处于整个流的两端,而队列会夹在中间就可以了。
4.1 队列堆积 Demo
这里看 Demo,可视化一下上面提到的概念。
const rQueuingStrategy = new CountQueuingStrategy({ highWaterMark: 15 })const readableStream = new ReadableStream( { start(controller) { button.onclick = () => { const log = index++ + ' start: ' + randomChars() + controller.desiredSize logInDiv(readableDiv!, log) controller.enqueue(log) console.log('controller.desiredSize', controller.desiredSize) } }, pull(controller) { const log = index++ + ' pull: ' + randomChars() + controller.desiredSize logInDiv(readableDiv!, log) controller.enqueue(log) console.log('controller.desiredSize', controller.desiredSize) }, }, rQueuingStrategy,)这个 readableStream 在 start 时不产生任何数据,只注册一个按钮点击回调,在按钮点击时,会 enqueue 一条数据。pull 是在内部队列还有空余时自动调用的函数,只要队列有空余,这里会源源不断地 enqueue 数据。
const wQueuingStrategy = new CountQueuingStrategy({ highWaterMark: 10 })const writableStream = new WritableStream( { async write(chunk) { await sleep(5000) logInDiv(writableDiv!, chunk) }, }, wQueuingStrategy,)在 writableStream 我们模拟一个超慢的消费速度(5 秒 1 条),这样队列必然堆积,也就能很清楚看出队列的运作了。
最后写一个 bridge 函数衔接输入输出流:
const bridge = async function () { const reader = readableStream.getReader() const writer = writableStream.getWriter() while (true) { const { value, done } = await reader.read() if (value) { console.log('writer.desiredSize', writer.desiredSize) await writer.ready writer.write(value) // 中间列的输出 logInDiv(transformDiv!, value) } if (done) { break } }}代码运行,因为第一次底层槽完成数据处理需要 5 秒,底层源的 pull,又不断产生数据,所以数据会直接充满队列,就能产生这个效果 👇
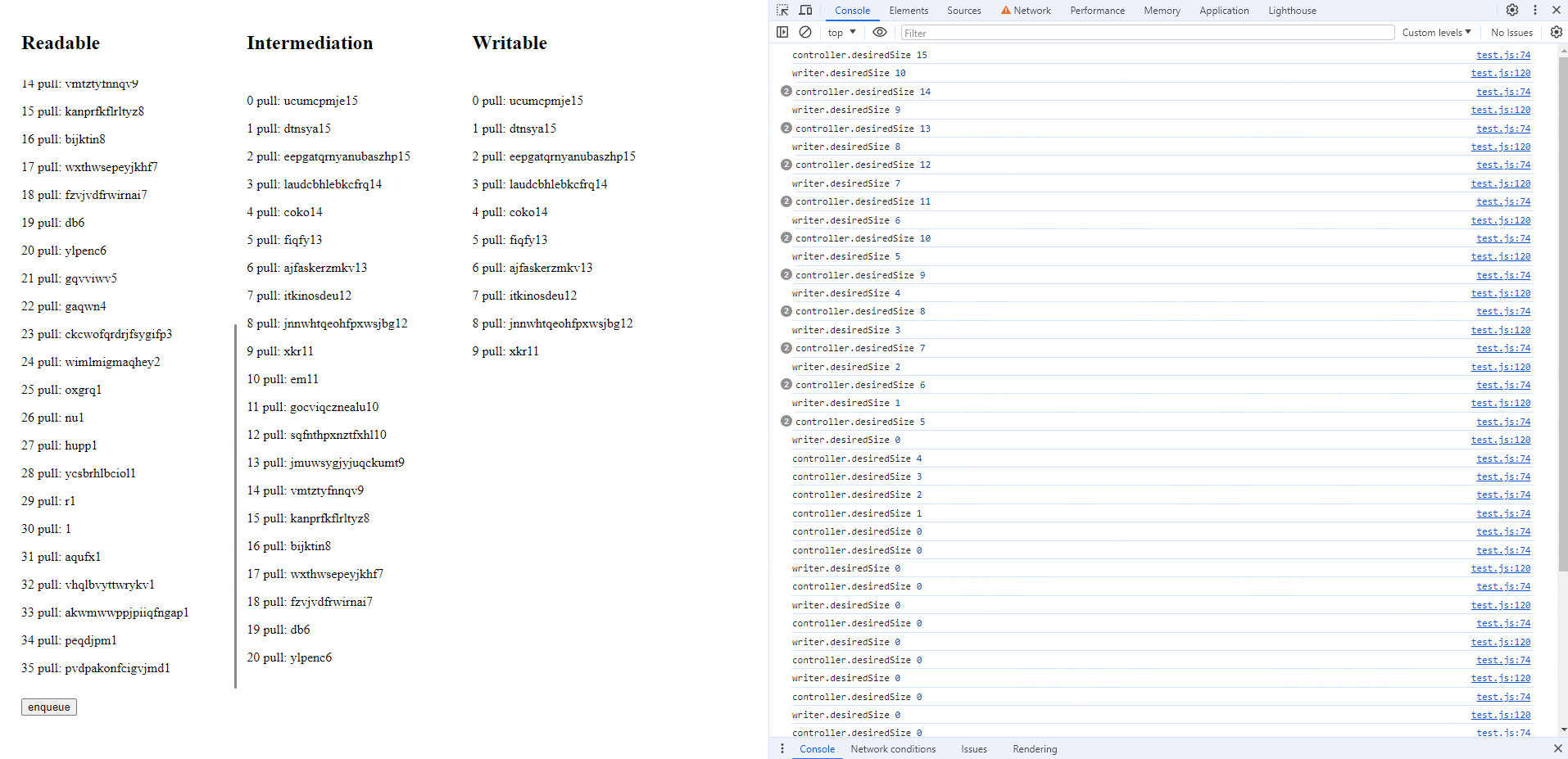
看两边就知道实际上可写流到底写了多少,以及可读流读了多少,用左边的条数减掉右边的条数,其实就是队列的容量。
打开控制台我们可以看到 desiredSize 一直是 0,但当我们点击 enqueue 按钮,一样可以写入,不过是继续排队罢了。所以 **highWaterMark 只是一个约定值,而不是严格的限制。即使队列超过 highWaterMark,你仍然可以继续操作数据。**不过这一切也不是免费的,都存在内存罢了,这样告诉我们设计流的时候要讲武德,desiredSize 为 0 就尽量不要再生产数据了。
五、实践
5.1 加密大文件传输
基本场景:从后端传输一个加密的大 txt 文件到前端,前端解密后显示,对比使用流和等待全部接受后再处理的速度差距。
app.get("/novel", async (req, res) => { // get file const file = fs.createReadStream("les-miserable.txt", { highWaterMark: 1024 * 25 }); // set header res.set("Content-Type", "message"); const encryptStream = new Transform({ transform(chunk, encoding, callback) { setTimeout(() => { const encrypted = []; chunk.forEach((byte) => { encrypted.push(map[byte]); }); const encryptedBuffer = Buffer.from(encrypted); this.push(encryptedBuffer); callback(); }, 10); }, }); file.pipe(encryptStream).pipe(res);});先从后端服务开始,这个接口读取一本 3.21 M 的《悲惨世界》,加密后返回前端。
加密步骤十分简单,只是建立一个把 0 到 255 随机打乱的 Map,把每个字节映射为加密的值。如果需要更严谨的加密系统应该要使用真正的加密算法,甚至可以搭配 wasm、定期更新密钥等措施。
此时打开浏览器开发者工具可以看到请求内容是一堆乱码,因为映射之后的内容是完全没办法 UTF-8 解码的。
前端采取两种读取方式处理这个接口,第一种是流式处理后解密,第二种是等待所有数据送达再一次性处理。
流式处理代码如下:
class Decrypter extends TransformStream { constructor() { super({ transform(chunk, controller) { const decrypted = chunk.map((byte) => decryptMap[byte]); controller.enqueue(decrypted); }, }); }}class DomWriter extends WritableStream { constructor() { super({ write(chunk) { resultsContainer.append(chunk); }, }); }}
let ac = null;const getNovelStream = async () => { if (ac) { ac.abort("refetch"); } resultsContainer.innerHTML = ""; const start = performance.now(); // prevent wrong callback ac = new AbortController(); const signal = ac.signal; // signal = null const response = await fetch(`/novel`, { signal });
let firstResponse = performance.now(); console.log(`Done! 🔥 Took ${firstResponse - start}ms`);
await response.body .pipeThrough(new Decrypter()) .pipeThrough(new TextDecoderStream()) .pipeTo(new DomWriter()); console.log(`Streaming done! 🔥 ${performance.now() - firstResponse}ms after request.`); ac = null;};这里涉及四个简单的 stream 类:
- fetch 结果的可读流
Decrypter:用加密的反向 map 解密TextDecoderStream:将 fetch 结果的字节数组编码为字符串DomWriter:一个把数据写入 DOM 的可写流
等待全部数据的传统数据方法看起来会比较简单:
const getNovel = async () => { if (ac) { ac.abort("fetch all"); } resultsContainer.innerHTML = "";
let firstResponse = performance.now(); const response = await fetch(`/novel`); const arrayBuffer = await response.arrayBuffer(); const view = new Uint8Array(arrayBuffer); for (let i = 0; i < view.byteLength; i++) { view[i] = decryptMap[view[i]]; } const decoder = new TextDecoder(); resultsContainer.innerHTML = decoder.decode(view); console.log(`Streaming done! 🔥 ${performance.now() - firstResponse}ms after request.`);};通过测试会发现这两种处理方式的用户体验差别很明显,流式处理可以立即展现内容,传统方式则要等待两秒才能看到内容。
5.2 日志输出
如果有一万行日志需要传输,等待全部数据到达不实际,全部数据一次性渲染也会存在性能问题,所以这是一个使用流的好时机。
class LineSplitStream extends TransformStream { constructor() { let leftover = ""; super({ transform(chunk, controller) { console.log(chunk); leftover += chunk; const lines = leftover.split("\n"); leftover = lines.pop(); controller.enqueue(lines); }, flush(controller) { if (leftover) { controller.enqueue([leftover]); } }, }); }}处理日志输出的细节是,fetch 得到的流不会自动帮你根据换行符分块,所以我们需要自己添加逻辑判定何为“一行”。这是一个说明“流没有边界”的很好的例子。
观察控制台输出 chunk 可以知道数据分界确实不是 \n,所以额外实现 LineSplitStream 正确处理数据分组。如果要在 http 基础上建立其他协议,这一步也是必不可少的,数据块需要有明确的分界点才能正确处理他们。