
1. ストリームの基本理解
小川は絶え間なく流れ続け、コンピュータサイエンスにおける連続的なデータ伝送に似ています。
なぜストリーミングがコンピュータサイエンスで重要なのでしょうか?主に2つの理由があります:
- メモリの過負荷を防ぐため
- 迅速な応答を可能にするため
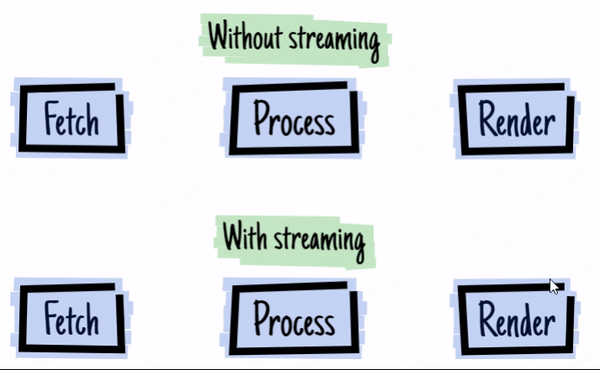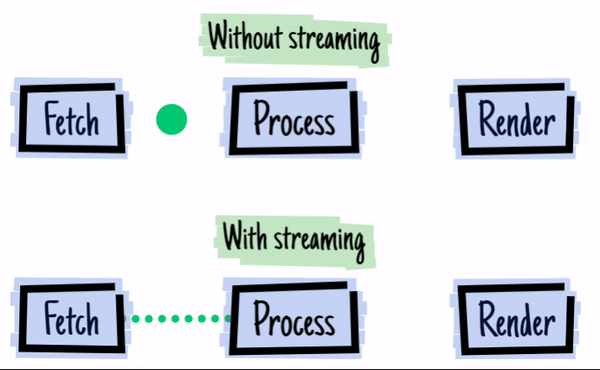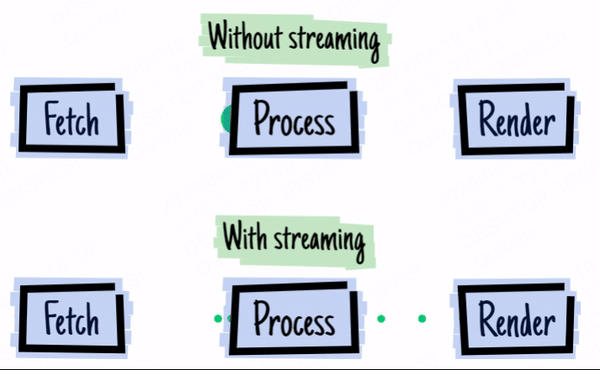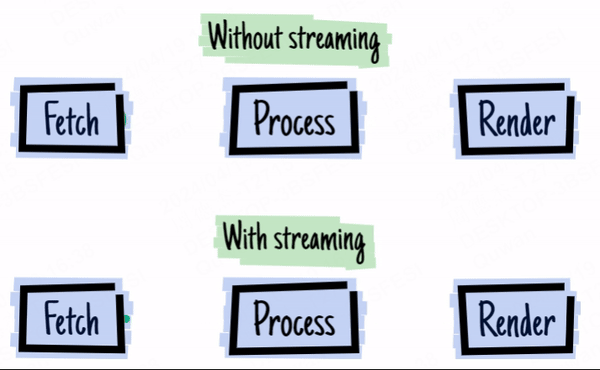
上の画像は2016 - ウェブストリームの年からのものです。
身近な例を考えてみましょう:GPTのストリーミング出力です。LLMの出力には時間がかかり、LLMがストリーミング方式で出力するため、生成されると同時にデータを送信し、結果をより早く見ることができます。
フロントエンド開発者にとって、ストリームAPIがブラウザで利用可能になる前は、Ajaxリクエストをストリーミング方式で処理することができませんでした(EventSourceを回避策として使用する場合を除く)。これにより、大量のデータリクエストの場合、すべてのデータが返されるのを待ってからコールバック関数で処理する必要があり、ユーザーエクスペリエンスが大幅に低下していました。
幸いなことに、2016年頃にブラウザのストリームAPIがついに更新されました。fetchのストリーミングリターンに加えて、ブラウザには他にも多くのストリーム関連のインターフェースがあります。
2. ストリームの基本構造
ここでは、最も基本的な2種類のストリームである読み取り可能なストリームと書き込み可能なストリームについて説明します。これらのインスタンスは ReadableStream と WritableStream を使って作成できます。他のストリーム関連のインターフェースはこれらを基礎としているため、これら2つを理解することで他のインターフェースも理解しやすくなります。
2.1 読み取り可能なストリーム
キーポイント:
- 基底ソース: データの実際の供給源
- キュー戦略(後で説明します)
- コントローラー: 読み取り可能なストリームのコントローラーで、特に
enqueueに注目 - リーダー: 読み取り可能なストリームを読み取るためのツール
const readableStream = new ReadableStream( { start(controller) { // インスタンス化されるとすぐに実行されます // 主に準備作業のためです // ここでデータをエンキューする場合、desiredSizeを考慮する必要があります },
pull(controller) { // 簡単に言うと、キューにスペースがあるとき、下流は上流からデータを引き出します // キューイング戦略はここで説明されます controller.enqueue("chunk"); },
cancel(reason) { // キャンセルコールバック }, }, new CountQueuingStrategy({ highWaterMark: 5 }), // オプション);基底ソースは、controllerパラメータを受け取ります。これはReadableStreamDefaultControllerです。
ReadableStreamDefaultController.desiredSize(キュー戦略については後で説明します)ReadableStreamDefaultController.close()ReadableStreamDefaultController.enqueue()ReadableStreamDefaultController.error()
controller.enqueueを使用してデータを提供できます。enqueueが呼び出されると、データはリーダーが消費するためのキューに入ります。
ストリームには境界がありませんが、そのような無限の概念は人間が実装するシステムには存在し得ません。ブラウザのストリームAPIでは、ストリームの伝送はチャンクに分割されます。上記のenqueueメソッドは、chunkをパラメータとして受け取ります。チャンクのタイプは一般的に文字列またはUint8Arrayですが、通常の読み取り可能なストリームはチャンクのタイプを制限しないため、オブジェクトも渡すことができます。(これは読み取り可能なバイトストリームについては議論しません)
stream.getReader()を使うと、対応するストリームのデフォルトリーダーを取得できます。ReadableStreamDefaultReaderには、次のプロパティとメソッドがあります:
ReadableStreamDefaultReader.closedReadableStreamDefaultReader.cancel()ReadableStreamDefaultReader.read()ReadableStreamDefaultReader.releaseLock()
const reader = readableStream.getReader();
reader.read().then( ({ value, done }) => { if (done) { console.log("The stream was already closed!"); } else { console.log(value); } }, (e) => console.error("The stream became errored and cannot be read from!", e),);リーダブルストリームが一度リーダーに接続されると、そのストリームはロックされます。同じストリームを2つのリーダーで読み取るためには、tee() メソッドを使ってストリームを分割することができます。

2.2 書き込み可能なストリーム
書き込み可能なストリームの基本概念は、読み取り可能なストリームの基本概念と非常に似ています:
- 基底シンク:データが処理され、最終的に送られる実際のポイント
- コントローラー:主に閉鎖とエラーの処理に使用される
- ライター:書き込み可能なストリームに書き込む責任を持つコンポーネント
const writableStream = new WritableStream( { start(controller) { // インスタンス化されるとすぐに実行される // 主に準備作業を行う },
write(chunk, controller) { // 書き込まれたデータチャンクの最終処理を行う },
close(controller) { // ストリームが閉じられる際のコールバック },
abort(reason) { // エラーが発生した際のコールバック }, }, new CountQueuingStrategy({ highWaterMark: 5 }),);基底ソースと同様に、基底シンクも controller パラメータを受け取ります。これは WritableStreamDefaultController です。このコントローラーは、読み取りストリームコントローラーに比べて操作が少なく、主にストリームの終了に関与します。
WritableStreamDefaultController.signalはライターのシグナルを終了しますWritableStreamDefaultController.error()はエラーを発生させ、ストリームを終了します
次に、ライターについて説明します。stream.getWriter() を使用することで、対応するストリームのデフォルトライターを取得できます。WritableStreamDefaultWriter には以下のプロパティとメソッドがあります:
WritableStreamDefaultWriter.closedWritableStreamDefaultWriter.desiredSize(後で queue strategy で議論される)WritableStreamDefaultWriter.ready(同上)WritableStreamDefaultWriter.abort()WritableStreamDefaultWriter.close()WritableStreamDefaultWriter.releaseLock()WritableStreamDefaultWriter.write()はライターを通じてデータを書き込む
// https://streams.spec.whatwg.org/#example-manual-write-dont-awaitasync function writeSuppliedBytesForever(writableStream, getBytes) { const writer = writableStream.getWriter();
while (true) { await writer.ready;
const bytes = getBytes(); writer.write(bytes).catch(() => {}); }}3. 変換ストリームとパイプライン操作
読み取り可能なストリームと書き込み可能なストリームの他に、データ処理に使用される別のタイプのストリームがあり、これを変換ストリームと呼びます。
TransformStream を使って変換ストリームを作成することができますが、実際には読み取りと書き込みの両方の機能を持つストリームはすべて変換ストリームと見なされます。
const transformStream = new TransformStream( // This section is called transformer { start(controller) { /* … */ },
transform(chunk, controller) { /* … */ },
flush(controller) { /* Final cleanup after all tasks are done */ }, }, writableStrategy, readableStrategy,);transform ストリームは、中間体として機能し、書き込み可能なストリームの chunk と読み取り可能なストリームの controller.enqueue を組み合わせます。
transform ストリームを使用する場合、「パイプ操作」が一般的に使用されます。これらの操作は、読み取り可能なストリーム、書き込み可能なストリーム、および transform ストリームを一緒にリンクすることができます。
pipeTo()は、読み取り可能なストリームを書き込み可能なストリームに接続します。pipeThrough()は、読み取り可能なストリームをtransformストリームに接続します。
例えば、underlying source -> transform -> transform -> underlying sink を実装するには、次のように書くことができます:
readableStream.pipeThrough(transformStream1).pipeThrough(transformStream2).pipeTo(writableStream);4. キュー戦略
4.1 説明
キュー戦略とは、前述のように、読み取り可能および書き込み可能なストリームを作成する際に提供する必要がある2番目のパラメータを指します。この戦略は、highWaterMarkを使用してストリームのキューのサイズを指定し、ストリーム間のバッファとして機能します。このサイズは絶対的な制限ではなく、あくまでガイドラインであることに注意してください。
なぜキュー戦略が必要なのでしょうか?それは、読み取り可能および書き込み可能なストリームのデータ処理速度が一貫していないためです。速度に変動がある場合、バッファとしてキューを持つことで処理効率を向上させることができます。
広く言えば、2つのタイプがあります。1つはカウントに基づくもので、もう1つはサイズに基づくものです:
new CountQueuingStrategy({ highWaterMark: 1 })new ByteLengthQueuingStrategy({ highWaterMark: 1024 })- クラスを使用せずに、直接オブジェクトを書くことができます
オブジェクトを直接書くと、次のようになります:
// ...{ highWaterMark: 1024, size(chunk) { return chunk.length },},// ...キューが容量に達した場合、メモリのオーバーフローを防ぐために上位レイヤーに減速を促す信号を送る必要があります。
これは、洗面器に水を注ぐ状況に似ています。洗面器が満杯になると、それ以上水を追加することはできません。この状況はバックプレッシャーと呼ばれ、desiredSizeによって示されます。
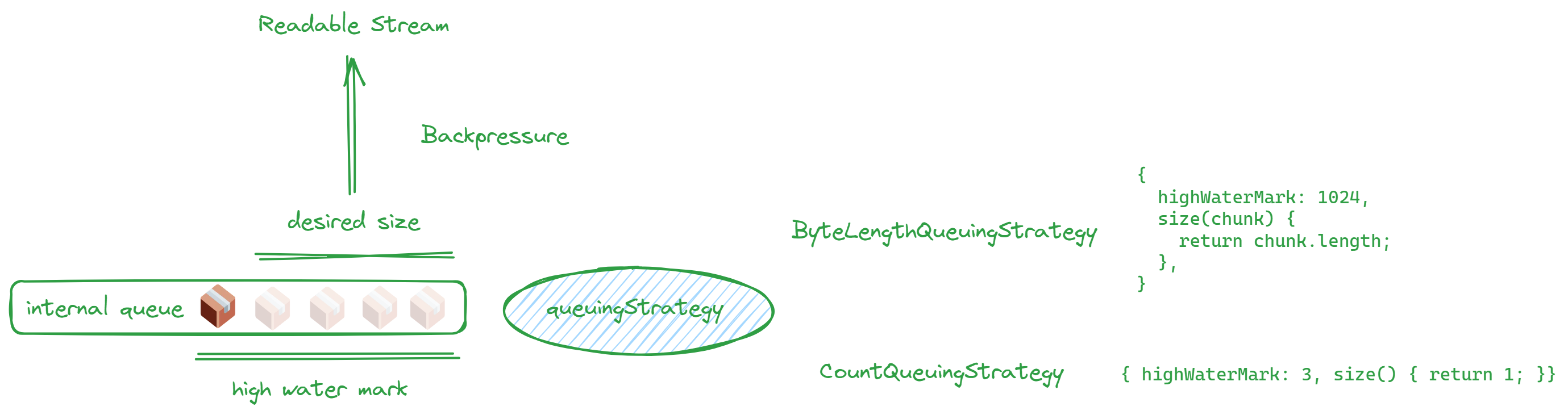
desiredSize は、high water mark から内部キュー内の量を引いた値として計算されます。
次に、前述の2つの desiredSize プロパティについて再確認しましょう:
ReadableStreamDefaultController.desiredSizeWritableStreamDefaultWriter.desiredSize
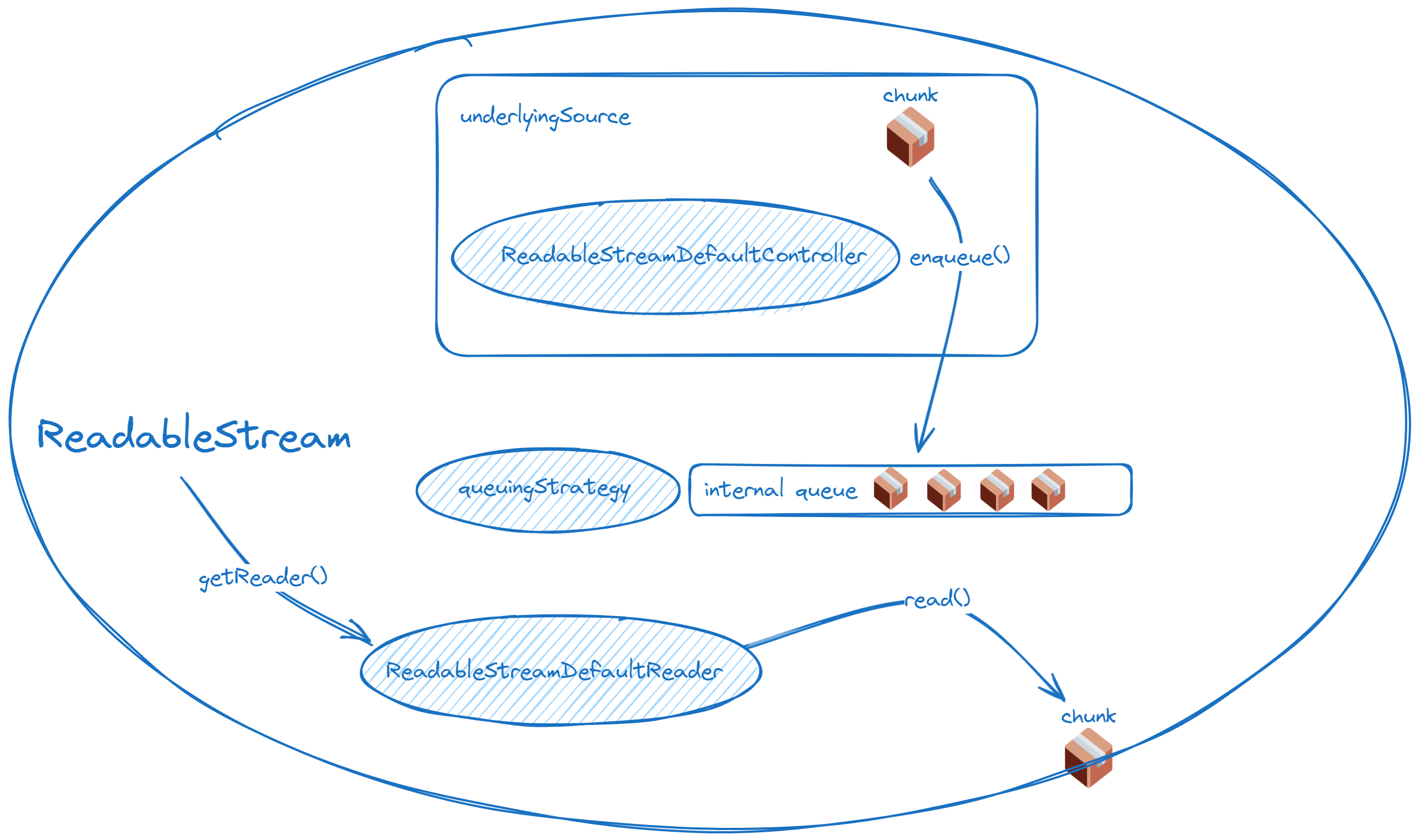
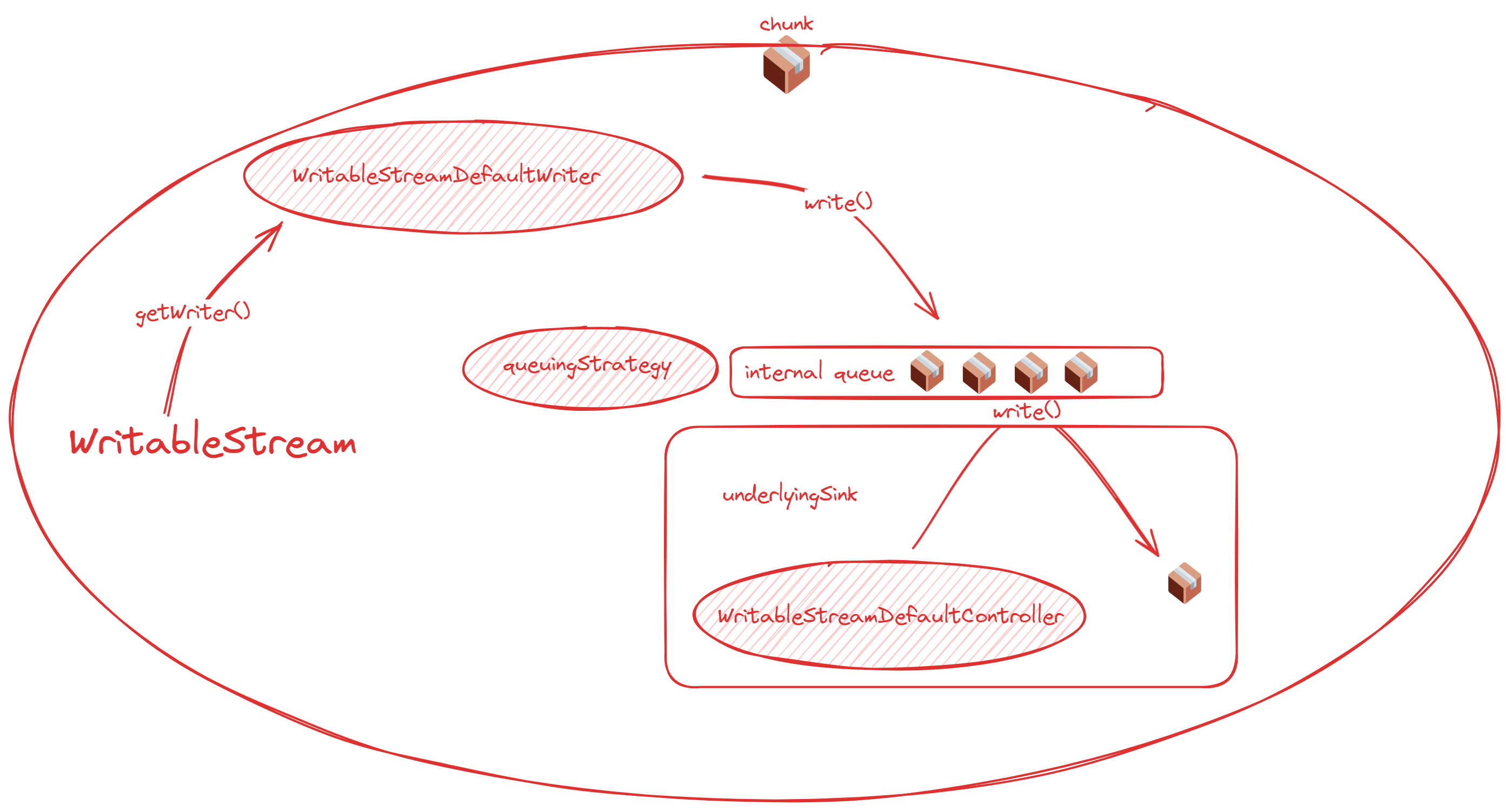
一方はReadableStreamのコントローラーにあり、もう一方はWritableStreamのライターにあります。なぜ一方がコントローラーに関連し、もう一方がライターに関連しているのか疑問に思うかもしれません。以下の図がその理由を明確にします!
これらの2つの図は、ReadableStreamとWritableStreamおよびそれらのキューとの関係を要約しており、キューがどこにあるかを明確に示しています。
読み取り可能なストリーム:
書き込み可能なストリーム:
内部キューに空きがある場合、リーダブルストリームのpullメソッドが自動的に呼び出され、高水位マークに達するまで続きます。startメソッドでデータの生成方法を定義する場合、desiredSizeが正でないときにデータの生成を停止するようにしてください。
書き込み側について:書き込みストリームとして、通常はdesiredSizeの値を直接気にすることはありません。WritableStreamDefaultWriter.readyを覚えていますか?readyがtrueのとき、desiredSizeは正です。したがって、書き込みストリームを実装する際には、通常await writer.readyを使用し、キューを適切に管理します。
簡単に言えば、基礎となるソースと基礎となるシンクは常にストリーム全体の両端にあり、キューはその間に位置しています。
4.2 キュー蓄積デモ
上記の概念を視覚化するには、デモをご覧ください。
const rQueuingStrategy = new CountQueuingStrategy({ highWaterMark: 15 })const readableStream = new ReadableStream( { start(controller) { button.onclick = () => { const log = index++ + ' start: ' + randomChars() + controller.desiredSize logInDiv(readableDiv!, log) controller.enqueue(log) console.log('controller.desiredSize', controller.desiredSize) } }, pull(controller) { const log = index++ + ' pull: ' + randomChars() + controller.desiredSize logInDiv(readableDiv!, log) controller.enqueue(log) console.log('controller.desiredSize', controller.desiredSize) }, }, rQueuingStrategy,)このReadableStreamは、start時にデータを生成することはなく、ボタンクリックのコールバックを登録するだけです。ボタンがクリックされると、データがenqueueされます。内部キューに空きがあるときは、pull関数が自動的に呼び出されます。キューに空きがある限り、データは継続的にenqueueされます。
const wQueuingStrategy = new CountQueuingStrategy({ highWaterMark: 10 })const writableStream = new WritableStream( { async write(chunk) { await sleep(5000) logInDiv(writableDiv!, chunk) }, }, wQueuingStrategy,)writableStreamでは、5秒ごとに1つのアイテムを消費する非常に遅い速度をシミュレートします。これにより、キューが蓄積され、キューの動作を簡単に観察できるようになります。
最後に、入力ストリームと出力ストリームをリンクするためのbridge関数を作成してください:
const bridge = async function () { const reader = readableStream.getReader() const writer = writableStream.getWriter() while (true) { const { value, done } = await reader.read() if (value) { console.log('writer.desiredSize', writer.desiredSize) await writer.ready writer.write(value) // 中间列的输出 logInDiv(transformDiv!, value) } if (done) { break } }}コードが実行されると、最初に基礎スロットがデータを処理するのに5秒かかります。基礎ソースのpullはデータを生成し続けるため、キューがすぐにいっぱいになり、次のような効果が生じます👇
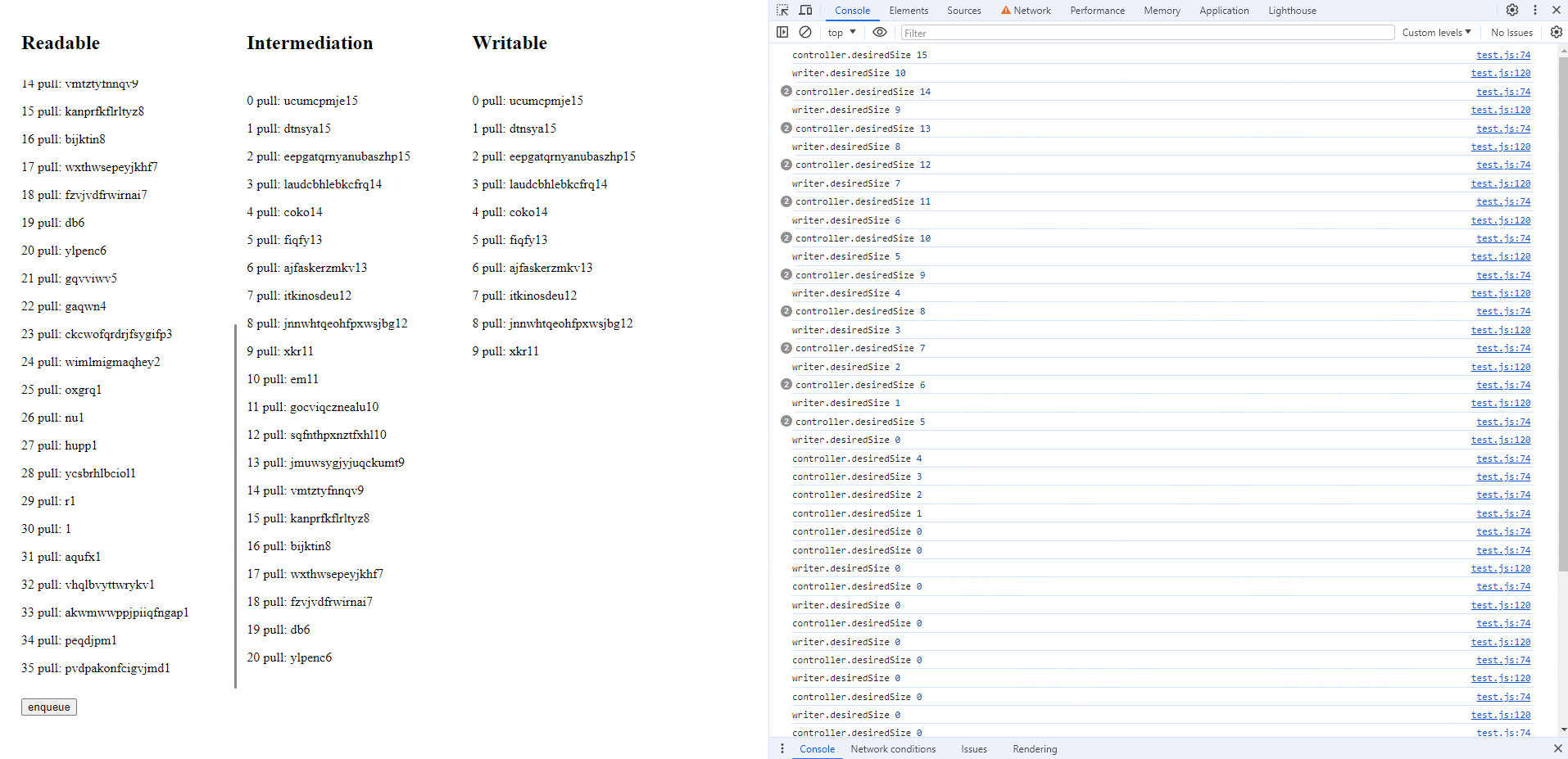
両側の状態を確認することで、書き込みストリームがどれだけ書き込んだか、読み取りストリームがどれだけ読んだかを把握できます。両者のカウントの差がキューの容量を示します。
コンソールでは、desiredSizeが常に0のままであることに気付くでしょう。しかし、enqueueボタンをクリックするとデータを追加でき、キューにどんどん追加されていきます。これは、highWaterMarkが単なるガイドラインであり、厳密な制限ではないことを意味します。キューがhighWaterMarkを超えてもデータ操作は可能です。 ただし、これはメモリを消費するため、コストがかかります。そのため、ストリームを設計する際には、desiredSizeが0のときにさらにデータを生成しないように注意することが重要です。
5. 実践的な応用
5.1 暗号化された大容量ファイルの転送
シナリオ: バックエンドからフロントエンドに暗号化された大容量のtxtファイルを転送します。フロントエンドはファイルを復号して表示します。ストリーミングを使用する場合と、ファイル全体を受信してから処理する場合の速度の違いを比較します。
app.get("/novel", async (req, res) => { // get file const file = fs.createReadStream("les-miserable.txt", { highWaterMark: 1024 * 25 }); // set header res.set("Content-Type", "message"); const encryptStream = new Transform({ transform(chunk, encoding, callback) { setTimeout(() => { const encrypted = []; chunk.forEach((byte) => { encrypted.push(map[byte]); }); const encryptedBuffer = Buffer.from(encrypted); this.push(encryptedBuffer); callback(); }, 10); }, }); file.pipe(encryptStream).pipe(res);});バックエンドサービスから始めましょう。このインターフェースは「レ・ミゼラブル」の3.21 MBのファイルを読み込み、暗号化してフロントエンドに返します。
暗号化プロセスは非常にシンプルです。0から255までの値をランダムにシャッフルするマップを作成し、各バイトを暗号化された値にマッピングします。より堅牢な暗号化システムを実現するためには、実際の暗号化アルゴリズムを使用し、WebAssembly(wasm)の利用やキーの定期的な更新などの追加対策を検討する必要があります。
この時点で、ブラウザの開発者ツールを開くと、リクエスト内容が乱れたテキストの塊であることがわかります。これは、マッピングされた内容がUTF-8で全くデコードできないためです。
フロントエンドはこのインターフェースを2つの方法で処理します。1つ目はストリーミング処理後にデコードする方法、2つ目はすべてのデータが到着してから一度に処理する方法です。
ストリーミング処理のコードは以下の通りです:
class Decrypter extends TransformStream { constructor() { super({ transform(chunk, controller) { const decrypted = chunk.map((byte) => decryptMap[byte]); controller.enqueue(decrypted); }, }); }}class DomWriter extends WritableStream { constructor() { super({ write(chunk) { resultsContainer.append(chunk); }, }); }}
let ac = null;const getNovelStream = async () => { if (ac) { ac.abort("refetch"); } resultsContainer.innerHTML = ""; const start = performance.now(); // prevent wrong callback ac = new AbortController(); const signal = ac.signal; // signal = null const response = await fetch(`/novel`, { signal });
let firstResponse = performance.now(); console.log(`Done! 🔥 Took ${firstResponse - start}ms`);
await response.body .pipeThrough(new Decrypter()) .pipeThrough(new TextDecoderStream()) .pipeTo(new DomWriter()); console.log(`Streaming done! 🔥 ${performance.now() - firstResponse}ms after request.`); ac = null;};以下の4つのシンプルなストリームクラスがあります:
- フェッチ結果を読み取るためのリーダブルストリーム
Decrypter: 暗号化の逆マップを使用してデータを復号化するTextDecoderStream: フェッチ結果のバイト配列を文字列に変換するDomWriter: データをDOMに書き込むためのライタブルストリーム
従来のすべてのデータを待つ方法の方が簡単に見えます:
const getNovel = async () => { if (ac) { ac.abort("fetch all"); } resultsContainer.innerHTML = "";
let firstResponse = performance.now(); const response = await fetch(`/novel`); const arrayBuffer = await response.arrayBuffer(); const view = new Uint8Array(arrayBuffer); for (let i = 0; i < view.byteLength; i++) { view[i] = decryptMap[view[i]]; } const decoder = new TextDecoder(); resultsContainer.innerHTML = decoder.decode(view); console.log(`Streaming done! 🔥 ${performance.now() - firstResponse}ms after request.`);};テストの結果、これら二つの処理方法の間でユーザー体験に大きな違いがあることが判明しました。ストリーム処理ではコンテンツが即座に表示されるのに対し、従来の方法ではコンテンツが表示されるまでに2秒の待ち時間が必要です。
5.2 ログ出力
一万行のログを送信する必要がある場合、すべてのデータが到着するのを待つのは現実的ではなく、すべてのデータを一度にレンダリングすることはパフォーマンスの問題を引き起こす可能性があります。したがって、このシナリオではストリーミングを使用することが適切な解決策です。
class LineSplitStream extends TransformStream { constructor() { let leftover = ""; super({ transform(chunk, controller) { console.log(chunk); leftover += chunk; const lines = leftover.split("\n"); leftover = lines.pop(); controller.enqueue(lines); }, flush(controller) { if (leftover) { controller.enqueue([leftover]); } }, }); }}ログ出力を処理する際には、fetchを通じて取得されるストリームが改行文字で自動的に分割されないことに注意する必要があります。そのため、「行」を定義するための独自のロジックを実装する必要があります。これは「境界のないストリーム」の良い例です。
コンソール出力のchunkを確認すると、データの境界が\nで定義されていないことがわかります。したがって、データのグループ化を正しく処理するためにLineSplitStreamを実装する必要があります。HTTPの上に他のプロトコルを構築する場合、このステップは重要です。データチャンクには明確な境界が必要であり、正確に処理される必要があります。