Paradigm Shift
Initially, we could only use AI for very basic programming assistance like function generation and tab completion. Back then, there was only VSCode Copilot, and many people looked down on AI programming.
The open-source chain of thought brought by Deepseek only exploded during this year’s Spring Festival. Soon after, chain of thought, tool calling, agents, and ultra-long context appeared one after another. After Claude 3.5 Sonnet emerged, the AI programming paradigm seemed to change overnight.
Originally, it was at best an assistant, but now it’s at least a capable mid-level engineer. Project setup, component refactoring - with proper guidance, it can handle them all.
Moreover, the cost of refactoring and trial-and-error is now extremely low. Previously, when a refactoring didn’t work well, we were reluctant to delete the code. Now, half a day is enough to refactor several times using different approaches.
Andrej Karpathy coined the term “Vibe Coding.” He himself rapidly builds web applications by constantly accepting AI suggestions (“I always accept all suggestions, I no longer read diffs”) and copy-pasting error messages to AI. After the recent explosion of AI IDEs, everyone should more or less realize that Vibe Coding is truly viable.
Prompt Engineering
Garbage in, garbage out
As AI has evolved, the effectiveness of prompt engineering has gradually weakened. AI IDEs and plugins come with thousands or even tens of thousands of words of system prompts, and sometimes they even ignore your additional prompts (for example, it’s hard to get Augment to not write tests and documentation - it always writes them automatically).
Role-playing and chain-of-thought prompts are no longer obviously effective, entering the realm of mystical improvements. In IDEs, the only really useful prompts now are basically one-shot and few-shot prompts.
Another approach is to set up a bunch of Rule prompts for the IDE:
Or the system that Kiro developed:
- Phase 1: Requirements clarification, transforming vague ideas into structured requirement documents
- Phase 2: Design and research, developing comprehensive design solutions based on requirements
- Phase 3: Task planning, creating executable implementation plans based on requirements and design
- Phase 4: Task execution, implementing tasks according to SPECS documentation
I once went through the complete process. Reviewing requirement documents was energy-consuming, doing a bunch of tasks was time-consuming and token-consuming, and the results weren’t particularly good. The tasks automatically generated by Kiro might include some seemingly advanced optimizations in the final steps, but they’re actually not recommended. Following the principle of “if it works, it’s good enough,” as long as you think the code meets your aesthetic standards along the way, the final optimizations might be over-optimization.
In summary, prompts should prioritize providing informational content rather than instructional content.
Context Engineering
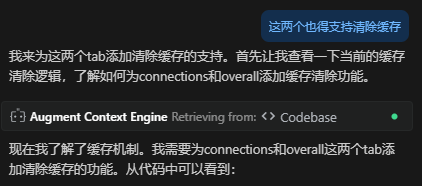
Augment Code is currently the best AI IDE plugin, with Context Engine and Diagnostics being two very powerful features.
Context Engine:
Diagnostics:
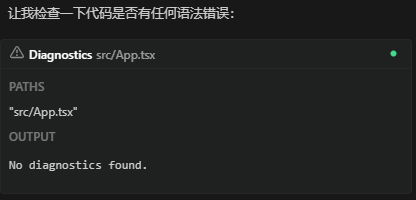
This is what’s called context engineering, with its core being retrieval, tools, and memory. Through the assembly of these three types of content, the system automatically helps users collect context.
However, the problem is that not all tools are this sophisticated. Context engineering may develop more perfectly in the future, but it’s still in a relatively primitive stage now. At this stage, we still often need to actively collect context to provide to large models.
Actively Providing Context
Below are some context gathering methods I use regularly.
UI Implementation
For multimodal models, images are part of the context, and using images to implement UI is a very basic operation.
At this stage, achieving pixel-perfect restoration is impossible, but there are some noteworthy points that can slightly improve generation quality.
When using images, you can first have the AI describe the basic layout of elements in the image, and even guide it to describe some details. If it describes inaccurately from the start, don’t expect it to write correctly later.
Generate a component list for your codebase and let the AI pick components from it when implementing pages from images. When necessary, you still need to actively tell it what abstracted components are needed, because it might not be able to tell just from the names.
v0 is an incredibly powerful screenshot-to-code tool with much higher fidelity than using Claude directly.
Fixing Problems
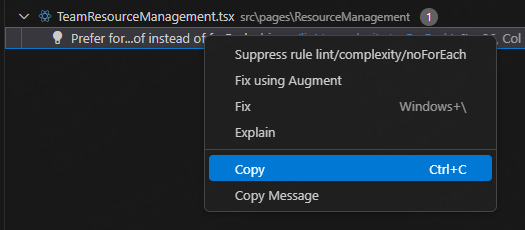
[ { "resource": "/d:/gpu/src/pages/ResourceManagement/TeamResourceManagement.tsx", "owner": "_generated_diagnostic_collection_name_#4", "code": { "value": "lint/style/useImportType", "target": { "$mid": 1, "path": "/linter/rules/use-import-type", "scheme": "https", "authority": "biomejs.dev" } }, "severity": 8, "message": "All these imports are only used as types.", "source": "biome", "startLineNumber": 35, "startColumn": 8, "endLineNumber": 35, "endColumn": 26, "origin": "extHost1" }]Apifox Copy
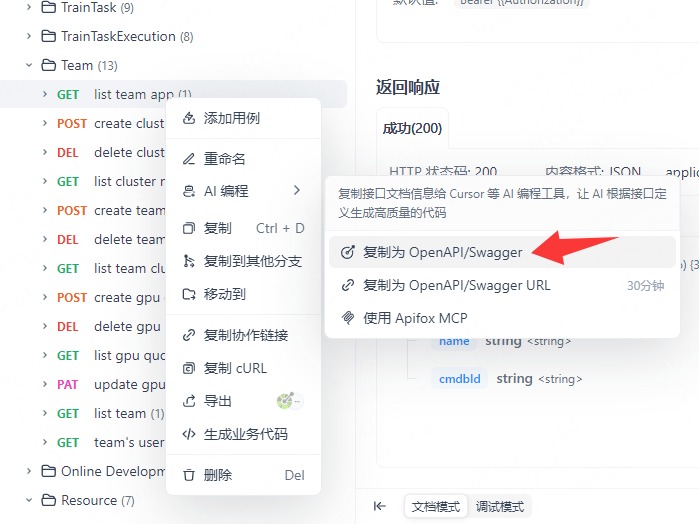
You can directly copy the OpenAPI specification of interfaces in Apifox and paste it to let AI add APIs, which is very convenient and reliable.
openapi: 3.0.1info: title: "" description: "" version: 1.0.0paths: /api/v1/team/app/list: get: summary: list team app deprecated: false description: "" tags: - Team parameters: - name: teamId in: query description: "" required: true schema: format: int type: integer - name: page in: query description: "" required: false schema: default: 1 format: int type: integer - name: size in: query description: "" required: false schema: default: 10 format: int type: integer - name: Authorization in: header description: "" example: Bearer {{Authorization}} schema: type: string default: Bearer {{Authorization}} responses: "200": description: "" content: application/json: schema: $ref: "#/components/schemas/mlops.api.team.v1.ListTeamAppRes" description: "" headers: {} x-apifox-name: 成功 security: [] x-apifox-folder: Team x-apifox-status: released x-run-in-apifox: https://app.apifox.com/web/project/6423715/apis/api-326223640-runcomponents: schemas: mlops.api.team.v1.ListTeamAppRes: properties: apps: format: "[]*dto.App" items: $ref: "#/components/schemas/mlops.internal.model.dto.App" description: "" type: array type: object x-apifox-orders: - apps x-apifox-ignore-properties: [] x-apifox-folder: "" mlops.internal.model.dto.App: properties: id: format: int type: integer name: format: string type: string cmdbId: format: string type: string type: object x-apifox-orders: - id - name - cmdbId x-apifox-ignore-properties: [] x-apifox-folder: "" securitySchemes: {}security: []Including Best Practices
The majority solution phenomenon refers to AI models’ tendency to generate the most common and direct solutions from training materials. In other words, training materials can only reflect the average coding ability of that language. Especially with React, React’s cognitive burden is very heavy, which is a problem with the framework itself. Despite this, there’s so much material available that it can almost always write “runnable” code. In fact, when you look closely, many strict rules will be flagged, and many implementations are not optimal solutions.
This may cause AI-written code to be correct in general scenarios, but not optimal in specific project contexts, or even just usable spaghetti code. Allowing AI majority solutions may also cause code bloat.
Due to the existence of the majority solution phenomenon, developers must identify these potential assumptions and non-optimal choices and adjust them according to actual needs.
In the frontend development field, due to the low barrier to entry where anyone can write code, this may lead to some code quality issues. If this problematic code serves as training data, it will exacerbate the above majority solution problem. So as a frontend developer, you may need to attach React best practices to the context.
Writing ChangeLog
Get the git commit hash of the last release, and tell AI to generate a ChangeLog from the commit based on this hash to the latest commit. It will automatically collect the needed information through git commands and output it for you.
Providing a template can ensure consistent ChangeLog formatting.
## v1.0.0 (2025-01-15)
**Feature Description - Brief version highlight description****Codename: Project Codename**
### ✨ New Features
- **Core functionality enhancement** - Improved overall application performance and stability- **Better file formatting** - Saved files now have proper indentation for improved readability
### 🔧 Improvements
- **Updated macOS icon** - Refreshed application icon for better macOS integration- **Enhanced performance** - Various underlying improvements for better user experience
### 🐛 Bug Fixes
- **Fixed login issues** - Resolved problems where users couldn't log in under certain circumstances- **Fixed data synchronization** - Improved stability of data synchronization between devices
### 🚀 Performance Optimizations
- **Startup speed improvement** - Application startup time reduced by 30%- **Memory usage optimization** - Reduced memory footprint and improved runtime efficiency
### 📚 Documentation Updates
- **Updated user manual** - Added detailed descriptions of new features- **API documentation improvements** - Supplemented missing API interface documentation
### ⚠️ Breaking Changes
- **API changes** - Some API interfaces have been refactored, please check the migration guide- **Configuration file format** - Configuration file format has changed, manual updates required
---
**Upgrade Instructions:**
- It's recommended to backup important data before upgrading- For detailed upgrade guide, please refer to the official documentationOf course, the prerequisite is that your commit messages must be written to standard.
DeepWiki
DeepWiki is an awesome repository wiki generation tool. Just provide a GitHub address, and it can generate a fairly complete wiki page for that repository.
Meanwhile, DeepWiki provides MCP capabilities:
{ "mcpServers": { "deepwiki": { "serverUrl": "https://mcp.deepwiki.com/sse" } }}Through the ask_question tool, you can have your AI tools ask questions to DeepWiki. If the documentation for some obscure library you’re using isn’t well-written, you might be able to get solutions directly using this tool.
For your own projects, you can also have AI generate documentation. After you review it and find no issues, this can become context for future questions.
llms.txt
llms.txt is a “summary file” specifically for AI (large language models) to read, similar to README.md for humans, but with a more concise and structured format that makes it easy for AI to quickly understand your website or project.
- Location: Place in the website root directory, like
https://example.com/llms.txt - Format: Plain text (UTF-8), similar to simplified Markdown
- Purpose: Tell AI what key pages, API documentation, SDK download addresses, etc. your website has, avoiding the need to crawl the entire site
- Comparison:
robots.txt: Tells search engines which pages not to crawlsitemap.xml: Pure site map containing all site linksllms.txt: Tells AI which pages are worth looking at, with page descriptions
Many technical documentations (like Apple’s) use JavaScript for dynamic loading, so AI can only see blank pages when accessing directly. llms.txt organizes key information into static text in advance, allowing AI to read directly and generate more accurate code or answers. For addresses mentioned in llms.txt, the specification also recommends that websites add a .md extension after the original URL to provide a pure Markdown version of the page.
例子:
# FastHTML
> FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library for creating server-rendered hypermedia applications.
Important notes:
- Although parts of its API are inspired by FastAPI, it is _not_ compatible with FastAPI syntax and is not targeted at creating API services- FastHTML is compatible with JS-native web components and any vanilla JS library, but not with React, Vue, or Svelte.
## Docs
- [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features- [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes, CSS classes, headers, events, extensions, js lib methods, and config options
## Examples
- [Todo list application](https://github.com/AnswerDotAI/fasthtml/blob/main/examples/adv_app.py): Detailed walk-thru of a complete CRUD app in FastHTML showing idiomatic use of FastHTML and HTMX patterns.
## Optional
- [Starlette full documentation](https://gist.githubusercontent.com/jph00/809e4a4808d4510be0e3dc9565e9cbd3/raw/9b717589ca44cedc8aaf00b2b8cacef922964c0f/starlette-sml.md): A subset of the Starlette documentation useful for FastHTML development.Some production examples:
| Site | Address |
|---|---|
| Vite | https://vite.dev/llms.txt |
| Svelte | https://svelte.dev/llms.txt |
| Windsurf | https://docs.windsurf.com/llms.txt |
| Ant Design | https://ant.design/llms.txt |
Index sites:
These three directory sites continuously collect new llms.txt files added to the internet, allowing direct search or browsing by tags.
Other AI Programming Strategies
Infinite Retry Flow
After failure, directly find the error and then update the prompt to retry the whole thing. For example, if you know it will overcomplicate the problem, tell it the simple approach from the beginning. Additionally, after knowing AI’s capability boundaries, supplement the context. For instance, if you ask it to implement functionality using a library but it doesn’t know how to use it, you need to supplement documentation links.
The benefit of doing this is that there are no erroneous steps in the entire conversation, and the context is completely clean.
Copy And Paste Great Again
Copy-pasting similar components was a big problem in the pre-AI era. When two components or functions had slight differences, we generally tended to directly copy one rather than create abstractions. But during subsequent modifications, we had to modify each place one by one. This wasn’t difficult, but it was manual labor.
After the AI era arrived, we can more confidently use the copy-paste pattern during initial development. AI can find similar content and modify it in batches, eliminating the need for manual labor. Later, if there are truly more use cases, we can also use AI to create abstractions afterward.
After all, premature optimization is the root of all evil. The earlier you encapsulate methods and components, the more hesitant you become when business changes require modifications.
Bidirectional Approach
When encountering problems that you sense AI cannot or will have difficulty solving, assign the task while simultaneously trying to find solutions yourself on ChatGPT. This has two benefits:
- Makes it easier to understand AI’s implementation approach after it finishes writing
- Find better approaches to guide AI optimization
As mentioned above regarding the majority solution phenomenon, the answers AI gives are just an average. When necessary, we need to further guide AI refactoring, such as not writing useEffect for everything and prioritizing event-driven approaches.
There’s also a hidden benefit: your thinking remains within context, making efficiency slightly higher.
Starter Templates
Using AI requires selection capabilities. From a Web frontend perspective alone, AI excels at this tech stack:
- Latest React, or second-latest version, to prevent AI from not knowing how to write it. However, with model improvements and expanded context, directly adding documentation links isn’t a big problem
- Latest Tailwind
- Shadcn/UI for beautiful components. AI writes this stuff very well - components are download-and-use, high visual appeal, and you can fine-tune styles yourself
- Vite for high-speed builds
- TypeScript for type safety. Without TS now, I can’t write code anymore
- Zustand for simplified state management. Also a means of compressing context - the more streamlined the interface design, the better AI adapts
- React Query for data fetching. In the past, hand-writing every loading state was very manual work. Now we’re not afraid - just let AI write it all, greatly improving user experience
- ESLint for code quality checking
- Prettier for code formatting
Candidate: Biome, a two-in-one existence of eslint and prettier. Processing speed is very fast, and it has more code optimization rules (for example, if you return early in an if, it will prompt you that you can omit the subsequent else. AI still basically writes with else)
React and Tailwind are almost standard configuration. Many app generation websites on the market (Lovable, Bolt, etc.) default to outputting this combination.
The V0 image-to-component mentioned above generates React components as results, which can be used immediately with React.
In the future, open source library user bases will become increasingly “winner-takes-all.” The more AI understands a library, the more users it has. The more users, the more training materials. The easier it is for AI to write well, and then it cycles.
Frontend-Backend Integration
If one person manages both frontend and backend code, it’s strongly recommended to put frontend and backend repositories together. Or directly return to the era of non-separated frontend and backend - trends really are circular.
Non-separated frontend and backend is more suitable for users without coding background. They originally don’t know how to distinguish between frontend and backend errors. AI Agents can flexibly access code from both frontend and backend sides, allowing them to more clearly distinguish which side has problems, preventing ineffective efforts in another codebase.
Actual Efficiency Improvements
Regarding the actual efficiency improvements of AI programming, they may not be as obvious as expected. Some comparative studies abroad show efficiency improvements might be around 20%, and some experimental results even show negative improvements.
The Last 30% Time Consumption
The 70% Problem: Many developers find that AI can complete about 70% of the initial solution, but the remaining 30% is frustrating and may lead to “one step forward, two steps back” issues. This is especially true for non-engineers who lack the underlying mental models to understand code and struggle to fix new bugs introduced by AI.
For the 70% problem, there’s currently no solution for users who completely rely on Vibe Coding (without understanding code). But as programmers, we must be wary of the long-term accumulation of vibe coding problems, which could turn into garbage coding.
We must have a preliminary understanding of the code before every commit - a general understanding is sufficient, and we can look more closely when encountering errors. I’m more accustomed to directly using git to check AI-updated code rather than using the accept/reject feature built into AI tools. Accepting everything directly and then checking with diff in git tools better fits my original habits.
Time Illusion
Developers spend additional time validating, debugging, and adjusting AI output. AI may produce low-performance or even incorrect code that then requires manual correction. Essentially, “hallucinations” and erroneous steps introduce additional loops.
Developers may too easily accept AI output and then spend longer debugging when errors occur, rather than writing simpler, correct solutions. Research indicates that even after experiencing slowdowns, developers still feel that AI helped - a cognitive bias because AI makes things feel easier, even when it’s not actually faster.
So try to ignore this “illusion” and pay attention to how much faster it really is compared to writing it yourself after waiting through multiple rounds of conversation, correcting AI, and scolding AI.
More Fragmented Thinking
Although there are more tasks that can be parallelized, this is probably not good for humans themselves.
This completely breaks the flow state that could previously be achieved. You can’t stare at AI coding - even if you don’t mind wasting time watching it, your eyes can hardly keep up with its implementation. But not watching means you’ve interrupted your current task to do something else.
This creates a terrifying effect: modern people’s already fragmented attention becomes even more fragmented, potentially causing problems with inability to concentrate or memory decline.
Beyond Coding
AI coding assistants excel at improving individual coding efficiency, but in the overall software development process, there are still many aspects that AI struggles to optimize:
- Cannot shorten cross-team collaboration time: Software development isn’t just about writing code; it also involves coordination between multiple teams, or communication and collaboration between different roles within teams (product, design, frontend, backend, testing, operations, etc.).
- Cannot shorten meeting time: Various meetings remain an indispensable part of the software development process. The purpose of these meetings isn’t just to convey information, but to form consensus and make decisions - processes that AI cannot currently participate in.
- Complexity of decision-making processes: Decisions like technology selection, architecture design, and resource allocation require weighing technical factors, business factors, team factors, and many other aspects. While AI can provide suggestions, final decisions still need to be made by humans based on experience and judgment.
What to Learn
- Learn to ask questions
- Refine debugging strategies, quickly locate problems, and provide context for AI debugging
- Understand performance optimization principles, identify shortcomings in AI implementations, and guide optimization
- Test edge cases, learn software testing methods, or use AI to write test code
- Familiarize yourself with overall project architecture and operations
- Creative UI design - from what I can see, even when prompts encourage it to make interfaces creative, the results still can’t escape very ordinary page structures