📚 小猫都能懂的大模型原理
- 📍 小猫都能懂的大模型原理 6 - 模型优化

本文旨在用简单易懂的语言解释大语言模型的基本原理,不会详细描述和解释其中的复杂数学和算法细节,希望各位小猫能有所收获 🐱
蒸馏
简单来说,大模型蒸馏(Model Distillation) 就是一种“老师带学生”的技术手段。
它的核心目的是:把一个超大模型(老师)的能力,“传授”给一个较小的模型(学生),让小模型在变小、变快、变便宜的同时,还能保留大模型的大部分能力。下面稍微具体说说怎么做到蒸馏。
可以想象,现在头部模型 800GB - 1TB 的硬盘文件大小,里面有很多冗余信息。对于小模型不需要那么面面俱到,所以通过大模型对小模型某些领域的指导,即使小模型没有那么大的规模,也能让小模型在该领域效果足够好。蒸馏后的模型只有 2GB ~ 4GB 的大小,完全可以在消费级电脑和手机上使用。
虽说参数量能大幅减少,但是蒸馏模型遇到老师没教的知识,回答就会十分滑稽。
顺带一提,类似的方法不只是可以用于大模型带小模型,也可以用于两个大模型之间左脚踩右脚互相进步,例如 2025 年春节爆火的 Deepseek R1 就是这么诞生的,他就是 V3 跟 R1 原型机互相成就,通过评分系统共同进步的典范。
蒸馏可以降低模型参数量且保留较高的智能,但优化方式还有不少。
量化
根据前面的章节我们也知道,每个 Token 都会被映射到很高维度的数组,这个数组里都带有精度很高的小数,聪明的小猫就会想到,哇小数那么难算,能不能砍掉几位?还真能。
量化就是通过降低模型的精度节省推理需要的显存,提高计算速度。
标准推理状态使用 FP16 的精度,研究表明 4-bit 量化到 INT4 也能保持模型大致能力,且节省很多内存空间。
打开 Hugging Face 的 Llama-3.2-3B-Instruct 仓库我们可以看到 Llama-3.2-3B 占硬盘大概 6.5G,而 4 bit 量化后的版本仅 2.02G。
从原理上看,量化之后的回答越长,能力应该是越差的,毕竟计算的次数越多,丢失精度造成的误差就会不断扩大。
超长上下文
上下文限制是大语言模型很致命的缺点,在前面所说的注意力矩阵中,默认整个上下文的所有 Token 都会对当前 Token 的真正含义造成影响,也就是如果上下文长度到了 ,这个矩阵的大小就是 ,完整计算整个矩阵需要的计算资源会高得十分离谱。
但是我们现在可以看到有的离谱模型上下文能到 1M,很明显,大佬们会想出各种优化方法解决超长上下文的问题,例如不要全量计算上下文矩阵:局部窗口注意力
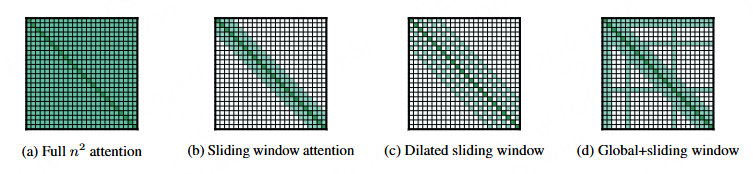
遇到内存不够的情况,也有环形注意力可以结合多张显卡共同计算一段上下文。这个环形注意力听起来很酷炫,简单来说就是一个上下文矩阵分多台机计算,设计一个算法只要按顺序环形交换计算结果就能并行运行超大上下文。
环形注意力虽然没有降低算力要求,但是解除了单卡显存限制,也就是只要你付得起钱,上下文很长也照样给你算(但是,真的十分贵呀)。
MoE
Mixture of Experts(混合专家)是一种减少计算量的优化方法。具体来说,MoE 通过门控网络选择性地激活部分专家,从而减少计算量。
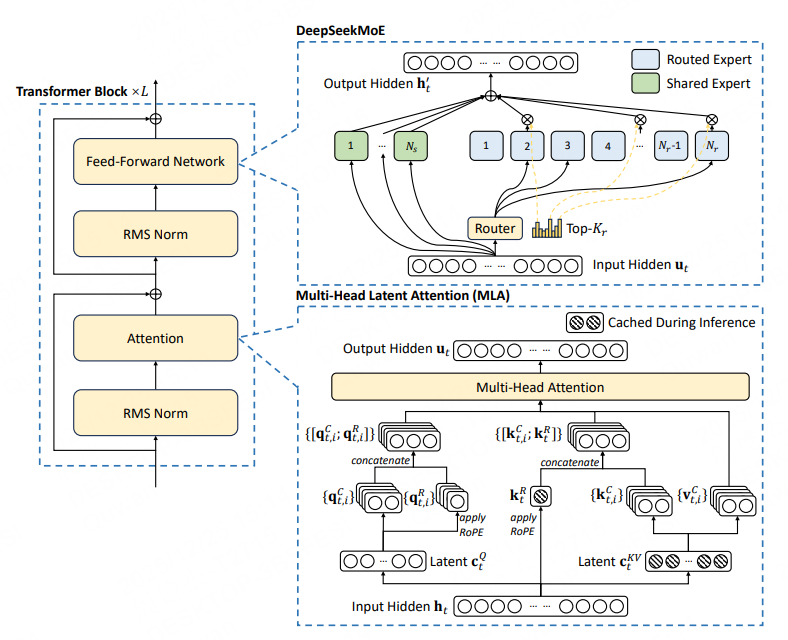
以上的 Deepseek V2 的 MoE 架构,注意 MoE 是在 FFN 层里。
假设我们输入 Token 的向量表示 (维度为 ),以及 个专家(Experts)。门控网络内部有一个可学习的权重矩阵 (维度为 )。它将输入 与权重矩阵相乘,计算出该 Token 与每个专家的“匹配度”。
然后重点来了,MoE 会根据匹配度只激活 Top-k 个专家,计算专家矩阵之后再对 Top-k 个专家的输出加权求和,得到最终的输出。例如 Deepseek V3 总参数 671B,激活的专家参数仅 37B,计算量大幅降低。
你或许会好奇 MoE 怎么知道分给哪个专家,其实这同样是通过计算损失反向传播,让门控网络自己学习分配目标。这里还有一点需要注意,如果完全放任不管,门控可能会把所有 Token 都分给少数的专家,那其他专家就等于废掉了,所以实现 MoE 还要注意负载均衡。
以上就是优化大模型的几种常见方法,或许后面会再开一期优化总结,但是下个话题先定为多模态,敬请期待 🐱