📚 小猫都能懂的大模型原理
- 📍 小猫都能懂的大模型原理 5 - 后训练

本文旨在用简单易懂的语言解释大语言模型的基本原理,不会详细描述和解释其中的复杂数学和算法细节,希望各位小猫能有所收获 🐱
GPT 训练完后并不能直接与用户流畅地聊天,就像是一个只会背书、不擅长与人交往的 Nerd 🤓。你说啥呢,他就接着从他大脑里想到的都一股脑说出来,接在你后面,情商约等于 0。
chatGPT 之所以叫 chatGPT,是因为它在 GPT 的基础上做了 chat 的后训练。
SFT
对话的训练素材大概长下面这样:
通过特定的 Token 标记对话的格式,然后把这些经过审阅的对话喂给模型即可。
在喂对话前,还需要注意整理数据和调整超参数:
- 数据清洗、过滤(去除垃圾、泄密、违法内容)
- 样本平衡(不同任务/风格的比例)
- 学习率、训练步数等超参的控制,避免遗忘原有能力或过拟合
这个步骤也叫 SFT,全称 Supervised Fine-Tuning(监督式微调)。
Hugging Face 是一个找 AI 开源资源的好地方,这里也有对话训练集:https://huggingface.co/datasets/openchat/ultrachat-sharegpt
除了对话的 SFT,厂商可能还会进行工具调用(function calling / MCP)、多轮任务规划、搜索结果整合等子技能,这些微调对 AI Agent 的实现极为重要。
除了大模型出厂前的 SFT,厂商也提供出厂后微调的服务,当然你也可以自己微调开源模型。
举个例子:如果你原创了一门计算机语言,想训练一个专门帮你的新语言的助手,你可以在通用大模型的基础上,用大量的编程相关数据进行微调,这样模型就会更擅长写对应语言的代码、调试、解释代码等任务。
微调的好处是成本相对较低,不需要从头训练模型,就能在特定领域获得很好的效果。
RLHF
RL(强化学习):智能体通过与环境“互动试错”,利用“奖励反馈”来学习如何做出能实现“长期利益最大化”的决策。
再下一步,来到 RLHF(Reinforcement Learning from Human Feedback),解决“模型会说话,但不一定合人类偏好”的问题,用人类偏好信号做强化学习,把模型往“更符合人类期望”的方向推,从而实现 Alignment(例如禁止黄赌毒啦,不要鼓励自杀啦,还有一系列 ZZZQ)。
先让人类对多条模型回答做偏好排序,训练一个奖励模型(Reward Model) 去拟合这种偏好;再用强化学习(常见是 PPO)让生成模型最大化奖励,这是很常见的一种通过模型强化另一个模型的方法。后面章节会讲到 路人皆知的 Deepseek R1,他的训练方式更是左脚踩右脚。
简单来说就是循环下面三个步骤:
- 自我生成: 原始模型生成一个回答。
- 裁判打分: 刚才训练好的“奖励模型”给这个回答打一个分数(Scalar Reward)。
- 参数更新: 如果分数高,算法(PPO)就会调整模型的参数,鼓励它以后多生成类似的回答;如果分数低,就抑制这种生成方式。
可能这时候就有小猫要问了,咋一句话的评分能影响到逐个 Token 生成的权重呢?Emmm,这个问题还是挺复杂的,但是知道像 PPO 这样的算法,会用这个总分来估算每一步动作的“好坏”(优势),从而对每个 token 的概率做梯度更新了。
来一个 RLHF 流程图方便各位小猫理解:
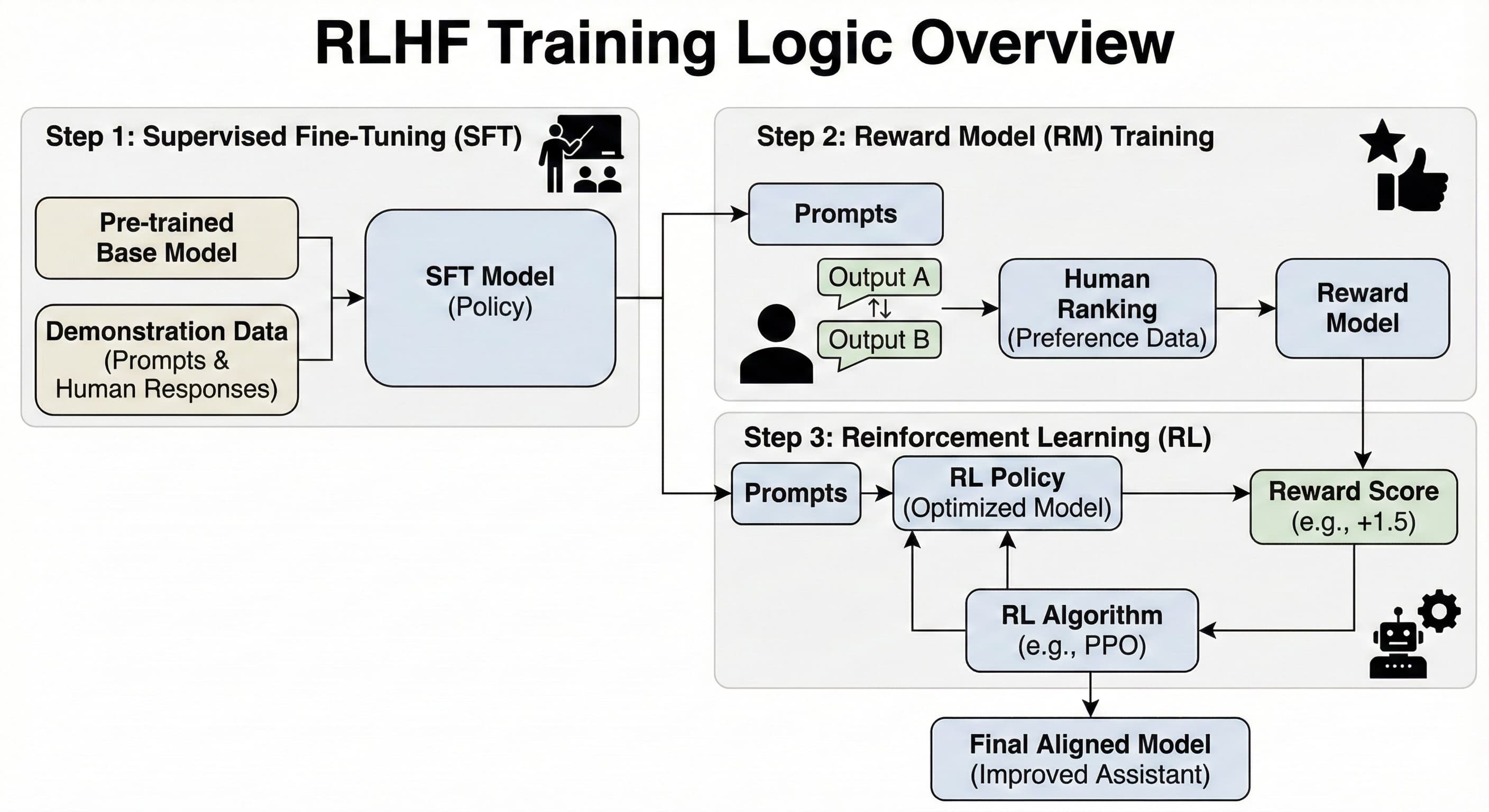
另外,现在也有一批“不要 RL 的 RLHF 替代品”,比如 DPO、IPO、ORPO 等,它们直接用人类偏好数据来训练,不再显式训练奖励模型和跑 PPO,但目标还是一样:让模型更符合人类喜欢的回答方式。
Reasoning
实现 Reasoning 的方式应该很多,例如与 RLHF 类似,你可以鼓励模型尽量使用逐步解题的方式回答问题,并把解题步骤放在 <think> 标签里,答案放在 <answer> 标签里,那它就可以学会逐步解题。
Deepseek 论文提到,通过一个叫 GRPO 的训练策略,通过一些固定的判断逻辑对输出结果进行评分。结果对就加分,格式对也加分,然后同一个 prompt 生成多个回答,奖励平均分以上的回答,这样就不需要额外训练一个奖励模型,只要设计好规则化奖励函数即可,节省掉传统 RLHF 里的花费高昂的奖励模型。

通过不断循环上述过程进行训练,模型会自发地让思考过程变长,为什么呢,因为经过长思考得到正确答案的概率更大,毕竟思考越长,它自己得到的信息就越多。最后,模型会自动产生“等等,我似乎错了”之类的惊喜时刻,这是属于 Reasoning 的“涌现”。
下一章将会介绍更多大模型优化策略,敬请期待 🐱