📚 小猫都能懂的大模型原理
- 📍 小猫都能懂的大模型原理 3 - 自注意力机制

本文旨在用简单易懂的语言解释大语言模型的基本原理,不会详细描述和解释其中的复杂数学和算法细节……但是本章还是一点点线性代数基础……希望各位小猫能有所收获 🐱
Transformer 的核心创新就是自注意力机制,如果忽略数学层面的问题,其实不难理解。
过去的深度学习框架对文字的处理,没有考虑到(大范围的)上下文,例如 RNN 就会一直循环计算前面的文字的影响力,但是距离一长,前面内容的记忆会丢失得比较多,而且 RNN 这个串行逻辑也跑不快。
自注意力
自注意力的突破点就在这里,它让整个上下文里的 Token 互相理解,计算过程是可以并行进行的。
之前说 GPT2 一个词维度有七百多,在下面这个例子里面,我们假设一个词维度只有 3。首先在词向量的基础上加上同样维度的位置向量,然后我们就要开始子注意力里面最精彩的 QKV 计算了。

我们从 Token 的向量开始:
- “Your” →
- “journey” →
- “step” →
然后,每个 都会通过三个矩阵(每个注意力头都有自己的三个矩阵,这三个矩阵是可训练的):
分别点积得到:
- Query 向量
- Key 向量
- Value 向量
Query 其他 Token
以当前词 “journey” 为例,就是用它的 query 向量 ,去点乘整个上下文其他词的 key 向量:
- “Your” →
- “journey” →
- “step” →
这就等于计算每个词与当前 query 的相似度:
例如:
- …
这些结果代表了当前词(“journey”)与其他词的“相关程度”。
点积: 点积不仅被视为一种将两个向量转化为标量值的数学工具,而且也是度量相似度的一种方 式,因为它可以量化两个向量之间的对齐程度:点积越大,向量之间的对齐程度或相似度就 越高。在自注意机制中,点积决定了序列中每个元素对其他元素的关注程度:点积越大,两 个元素之间的相似度和注意力分数就越高。
归一化注意力权重
接着对所有相似度 进行 Softmax 归一化(公式不用细看,归一化就是让所有值加起来等于 1):
得到:
- …
这些值称为 注意力权重(attention weights),表示模型在处理当前词“journey”时,对其他词的关注程度。
上下文向量
最后一步: 每个词都有自己的 value 向量 ,将它与对应的注意力权重相乘并求和:
如图中:
- …
计算后得到:
这个向量 就是 “journey” 的上下文向量(context vector),它综合了句子中各个词的语义信息,并且根据注意力权重动态决定了“关注谁”。
在点积之后,为了防止数值过大导致 Softmax 算出来的梯度太小(难以训练),我们通常会把结果除以一个缩放系数(通常是维度的根号,即 ),然后再做归一化。
经过上面一同操作,就得出了著名得注意力公式:
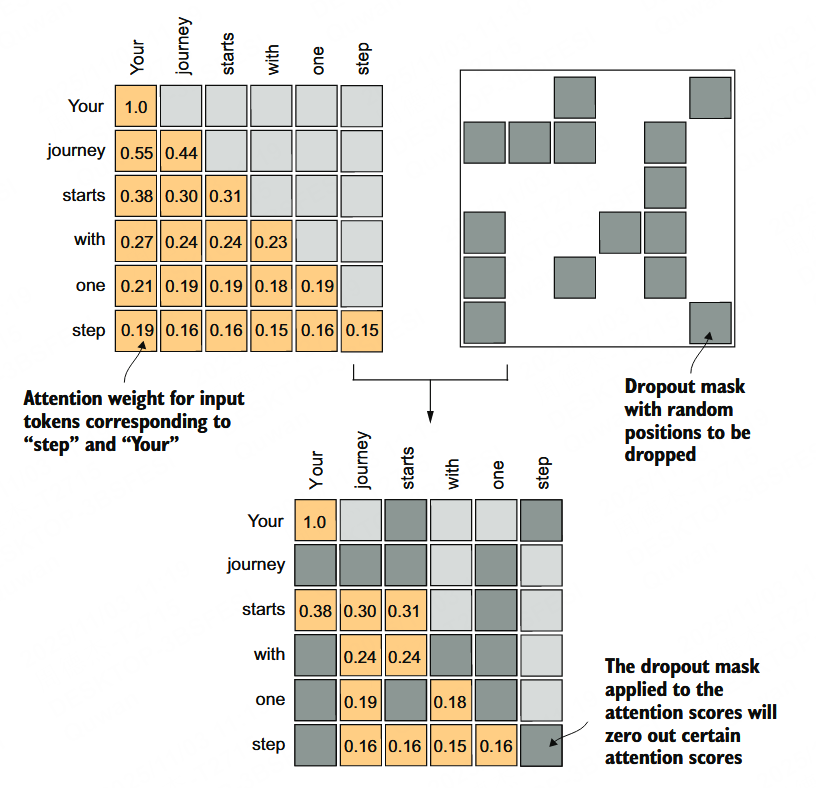
掩码
因果注意力就是把每个字后面的字都盖住,防偷看。
因果掩码让大模型只考虑前面的内容,不是因为后面的内容没有用,而是因为训练的目标就是从前面的内容生成后面的内容,所以即使有用,在这个运行机理上后面的内容就是不可访问的,大模型必须在后面不可知的情况下进行学习。
另一种掩码是 dropout,指每个头都随机选一些词盖住,让模型的注意力能集中到某些词上。
多头
前面也说每个头的 QKV 矩阵都是不一样,因为在初始化 QKV 矩阵时数值就是随机的,那么通过反向传播得到的值就不一样,所以各个头注意到的东西自然也不一样。
虽说人类不好理解注意力,但还是可以通过注意力可视化找到一些提示,例如某些头会学习到被动语态,又有某些头会学习到词性分析。
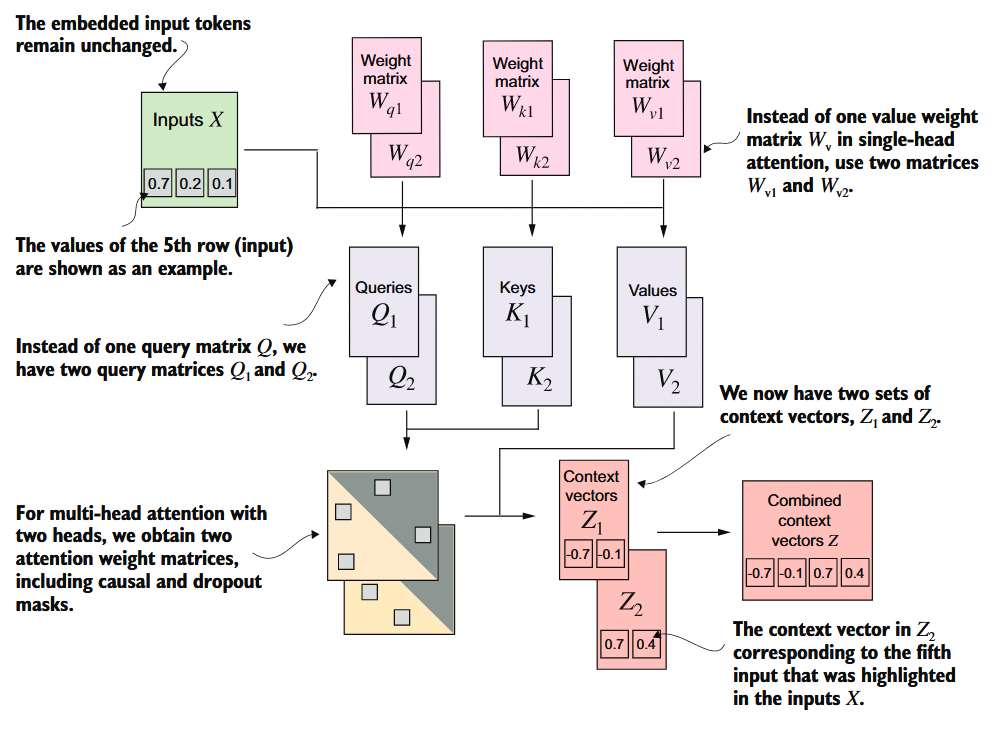
最后系统会把多个头的信息汇总,最后输出到下一步。