注意:对于希望深入了解浏览器工作原理的读者,Pavel Panchekha 和 Chris Harrelson 编写的《浏览器工程》(可在 browser.engineering 获取)是一本极佳的参考书籍,强烈推荐阅读。本文是对浏览器工作原理的概述。
Web 开发者通常将浏览器视为一个黑盒子,它神奇地将 HTML、CSS 和 JavaScript 转换为交互式的 Web 应用程序。实际上,像 Chrome(基于 Chromium)、Firefox(基于 Gecko)或 Safari(基于 WebKit)这样的现代浏览器都是极其复杂的软件系统。它们需要协调网络通信、解析和执行代码、通过 GPU 加速渲染图形,并在沙盒进程中隔离内容以确保安全。
本文将深入探讨现代浏览器的工作原理,重点关注 Chromium 的架构和内部机制,同时指出其他引擎的不同之处。我们将探索从网络栈和解析管道,到通过 Blink 进行渲染、通过 V8 执行 JavaScript、模块加载、多进程架构、安全沙盒和开发者工具等各个方面。目标是提供一个对开发者友好的解释,揭开浏览器幕后的运作机制。
让我们开始探索浏览器的内部世界。
网络通信和资源加载
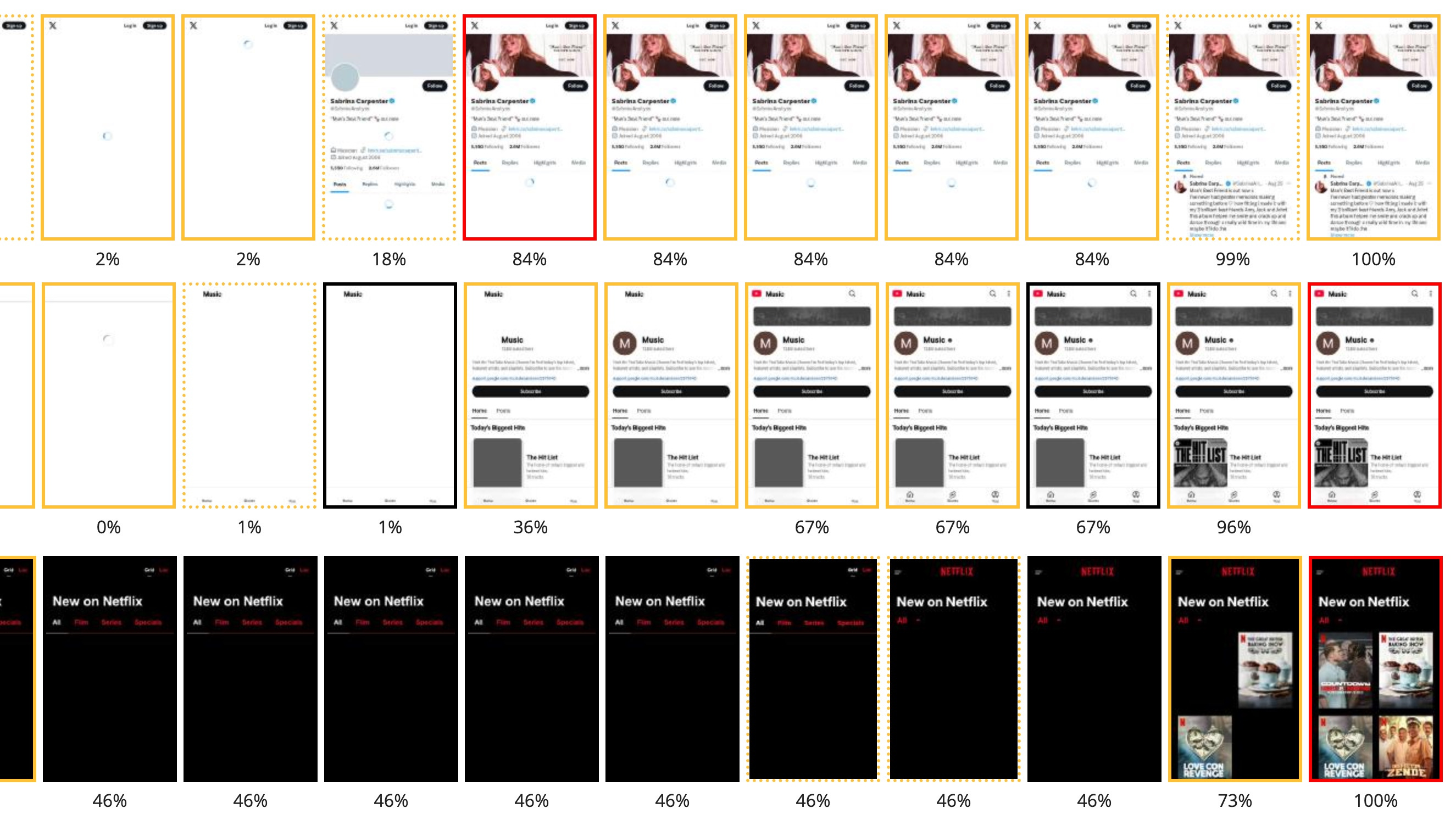
每次页面加载都始于浏览器的网络栈从 Web 获取资源。当你输入 URL 或点击链接时,浏览器的 UI 线程(运行在”浏览器进程”中)会启动导航请求。
浏览器进程是主要的控制进程,负责管理所有其他进程和浏览器的用户界面。除了特定网页标签页之外的所有操作都由浏览器进程控制。
具体步骤包括:
URL 解析和安全检查:浏览器解析 URL 以确定协议(http、https 等)和目标域名。它还会判断输入的是搜索查询还是 URL(例如在 Chrome 的地址栏中)。这里可能会检查安全功能如黑名单,以避免钓鱼网站。
DNS 查询:网络栈将域名解析为 IP 地址(除非已缓存)。这个过程可能需要联系 DNS 服务器。现代浏览器可能使用操作系统的 DNS 服务,甚至在配置的情况下使用 DNS over HTTPS (DoH),但最终它们都会获得主机的 IP 地址。
建立连接:如果不存在到服务器的开放连接,浏览器会建立一个新连接。对于 HTTPS URL,这包括 TLS 握手以安全地交换密钥和验证证书。浏览器的网络线程会自动处理 TCP/TLS 设置等协议细节。
发送 HTTP 请求:连接建立后,发送 HTTP GET 请求(或其他方法)来获取资源。现代浏览器如果服务器支持,会默认使用 HTTP/2 或 HTTP/3,这允许在一个连接上复用多个资源请求。这种方式通过避免 HTTP/1.1 每个主机约 6 个并行连接的限制来提高性能。例如,使用 HTTP/2,HTML、CSS、JS、图片都可以在一个 TCP/TLS 连接上并发获取,而 HTTP/3(基于 QUIC UDP)进一步减少了建立连接的延迟。
接收响应:服务器响应 HTTP 状态码和头部,然后是响应体(HTML 内容、JSON 数据等)。浏览器读取响应流。如果 Content-Type 头部缺失或不正确,浏览器可能需要嗅探 MIME 类型来决定如何处理内容。例如,如果响应看起来像 HTML 但没有相应标记,浏览器仍会尝试将其视为 HTML(根据宽松的 Web 标准)。这里也有安全措施:网络层检查 Content-Type,可能阻止可疑的 MIME 不匹配或不允许的跨源数据(Chrome 的 CORB——跨源读取阻止——就是这样一种机制)。浏览器还会查询安全浏览或类似服务来阻止已知的恶意内容。
重定向和后续步骤:如果响应是 HTTP 重定向(例如带有 Location 头的 301 或 302),网络代码将跟随重定向(在通知 UI 线程后)并对新 URL 重复请求。只有获得包含实际内容的最终响应后,浏览器才会继续处理该内容。
所有这些步骤都在网络栈中进行,在 Chromium 中,网络栈运行在专用的网络服务中(现在通常是一个单独的进程,作为 Chrome “服务化”工作的一部分)。浏览器进程的网络线程协调套接字通信的底层工作,使用操作系统网络 API。重要的是,这种设计意味着渲染器(负责执行页面代码)不能直接访问网络——它必须请求浏览器进程获取所需内容,这是一个重要的安全优势。
预测性加载和资源优化
现代浏览器在网络阶段实现了复杂的性能优化。当你悬停在链接上或开始输入 URL 时,Chrome 会主动执行 DNS 预取或打开 TCP 连接(使用预测器或预连接机制),这样如果你点击链接,部分延迟就已经被消除了。还有 HTTP 缓存:如果资源已缓存且仍然有效,网络栈可以直接从浏览器缓存提供请求,避免网络往返。
预加载扫描器操作:Chromium 实现了复杂的预加载扫描器,它会在主解析器之前对 HTML 标记进行标记化。当主 HTML 解析器被 CSS 或同步 JavaScript 阻塞时,预加载扫描器会继续检查原始标记,识别可以并行获取的资源,如图片、脚本和样式表。这种机制是现代浏览器性能的基础,无需开发者干预即可自动运行。预加载扫描器无法发现通过 JavaScript 动态注入的资源,导致这些资源可能串行而非并行加载。
Early Hints (HTTP 103):Early Hints 允许服务器在生成主响应时发送资源提示,使用 HTTP 103 状态码。这使得预连接和预加载提示可以在服务器处理时间内发送,可能将最大内容绘制时间改善几百毫秒。Early Hints 仅适用于导航请求,支持预连接和预加载指令,但不支持预取。
预测规则 API:预测规则 API 是一个最新的 Web 标准,允许定义规则来根据用户交互模式动态预取和预渲染 URL。与传统的链接预取不同,此 API 可以预渲染整个页面,包括 JavaScript 执行,实现近乎即时的加载时间。该 API 在脚本元素或 HTTP 头中使用 JSON 语法来指定应进行预测性加载的 URL。Chrome 设有限制以防止过度使用,根据优先级别有不同的容量设置。
HTTP/2 和 HTTP/3:大多数基于 Chromium 的浏览器和 Firefox 完全支持 HTTP/2,HTTP/3(基于 QUIC)也得到广泛支持(Chrome 默认为支持的站点启用)。这些协议通过允许并发传输和减少握手开销来改善页面加载性能。从开发者角度来看,这意味着你可能不再需要雪碧图或域名分片技巧——浏览器可以在一个连接上高效地并行获取许多小文件。
资源优先级:浏览器还会对某些资源进行优先级排序。通常,HTML 和 CSS 是高优先级(因为它们会阻塞渲染),脚本可能是中等优先级(如果适当标记为 defer/async 则为高优先级),图片优先级可能较低。Chromium 的网络栈会分配权重,甚至可以取消或延迟请求以优先处理初始渲染所需的内容。开发者可以使用 link rel=preload 和 Fetch Priority 来影响资源优先级。
在网络阶段结束时,浏览器获得了页面的初始 HTML(假设这是一个 HTML 导航)。此时,Chrome 的浏览器进程会选择一个渲染器进程来处理内容。Chrome 通常会与网络请求并行启动一个新的渲染器进程(提前准备),这样当数据到达时就已经准备就绪。这个渲染器进程是隔离的(稍后详述多进程架构),将接管解析和渲染页面的工作。
一旦响应完全接收(或在流式传输时),浏览器进程会提交导航:它向渲染器进程发出信号,接收字节流并开始处理页面。此时,地址栏会更新,新站点的安全指示器(HTTPS 锁等)会显示。现在控制权转移到渲染器进程:解析 HTML、加载子资源、执行脚本和绘制页面。
解析 HTML、CSS 和 JavaScript
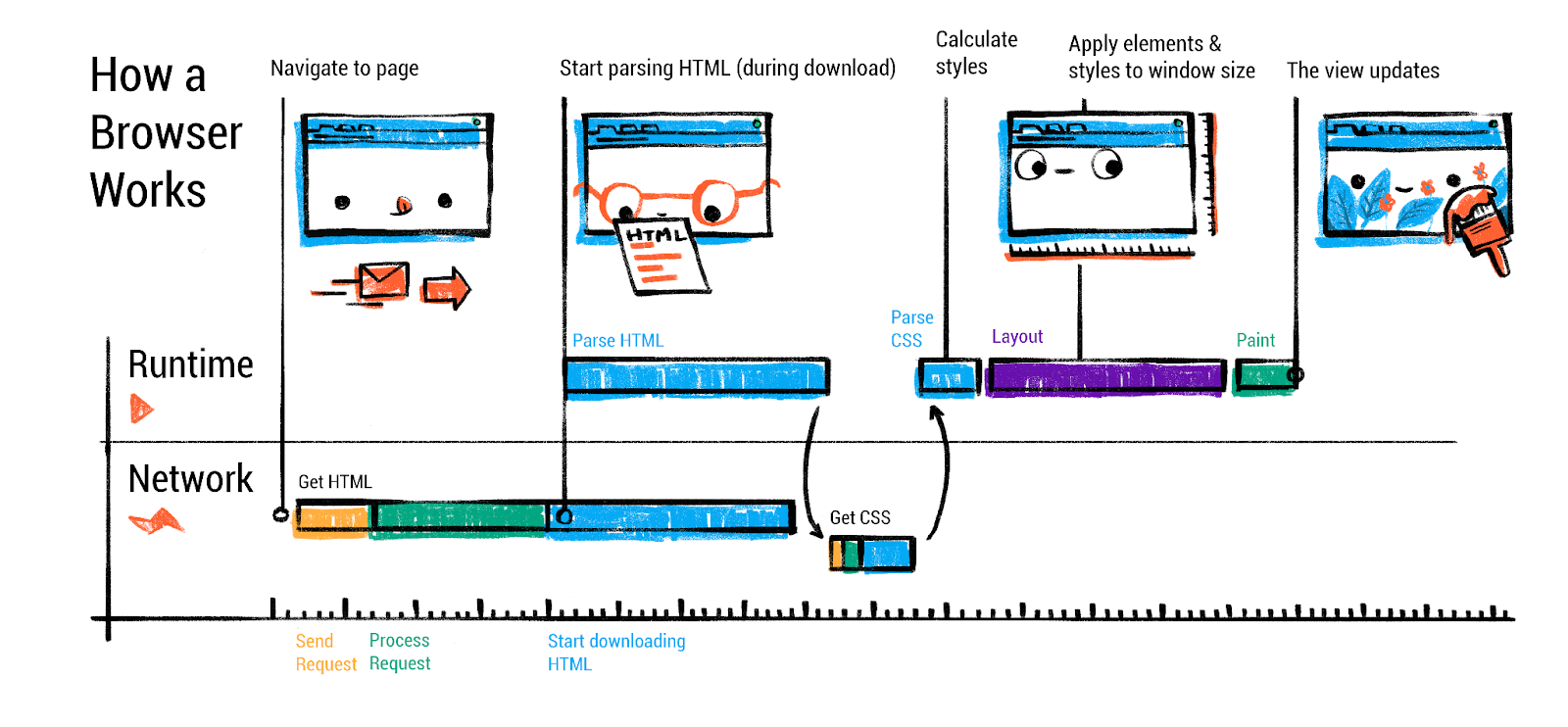
当渲染器进程接收到 HTML 内容时,其主线程开始根据 HTML 规范解析内容。HTML 解析的结果是 DOM(文档对象模型)——表示页面结构的对象树。解析是增量进行的,可以与网络读取交错进行(浏览器以流式方式解析 HTML,因此即使在整个 HTML 文件下载完成之前,DOM 就可以开始构建)。
HTML 解析和 DOM 构建:HTML 解析由 HTML 标准定义为容错过程,无论标记多么格式错误,都会产生 DOM。这意味着即使你忘记了结束 </p> 标签或标签嵌套不正确,解析器也会隐式修复或调整 DOM 树使其有效。例如,<p>Hello <div>World</div> 会在 DOM 结构中自动在 <div> 之前结束 <p>。解析器会为 HTML 中的每个标签或文本创建 DOM 元素和文本节点。每个元素都会放置在反映源代码嵌套结构的树中。
HTML 解析器在解析过程中可能遇到需要获取的资源,这是一个重要方面:例如,遇到 <link rel="stylesheet" href="..."> 会提示浏览器请求 CSS 文件(在网络线程上),遇到 <img src="..."> 会触发图片请求。这些请求与解析并行发生。解析器可以在这些加载进行时继续工作,但有一个重大例外:脚本。
处理 <script> 标签:如果 HTML 解析器遇到 <script> 标签,它会暂停解析,必须在继续之前执行脚本(默认情况下)。这是因为脚本可以使用 document.write() 或其他 DOM 操作来改变仍在传入的页面结构或内容。通过在该点立即执行,浏览器能够保持相对于 HTML 的正确操作顺序。因此解析器会将脚本交给 JavaScript 引擎执行,只有当脚本完成(以及它所做的任何 DOM 更改都应用)时,HTML 解析才能恢复。这种脚本执行阻塞行为是为什么在头部包含大型 <script> 文件会减慢页面渲染的原因——HTML 解析无法继续,直到脚本下载并运行完毕。
但是,开发者可以通过属性修改这种行为:向 <script> 标签添加 defer 或 async(或使用现代 ES 模块脚本)会改变浏览器处理脚本的方式。使用 async,脚本文件会并行获取,一旦准备就绪就执行,不会暂停 HTML 解析(解析不会等待,脚本不保证相对于其他异步脚本的原始顺序执行)。使用 defer,脚本会并行获取,但执行会延迟到 HTML 解析完成(并将在那个时候按原始顺序执行)。在这两种情况下,解析器都不会被阻塞等待脚本,这通常对性能更有利。ES6 模块(使用 <script type="module">)也会自动延迟(它们也可以使用 import 语句——我们将单独介绍模块加载)。通过使用这些技术,浏览器可以继续构建 DOM 而不会长时间暂停,使页面加载更快。
CSS 解析和 CSSOM:除了 HTML,CSS 文本也必须解析成浏览器可以使用的结构——通常称为 CSSOM(CSS 对象模型)。CSSOM 本质上是应用于文档的所有样式(规则、选择器、属性)的表示。浏览器的 CSS 解析器会读取 CSS 文件(或 <style> 块)并将它们转换为 CSS 规则列表(以及许多布隆过滤器等以加速样式解析)。然后,当 DOM 正在构建时(或一旦 DOM 和 CSSOM 都准备好),浏览器会计算每个 DOM 节点的样式。这一步通常称为样式解析或样式计算。浏览器会结合 DOM 和 CSSOM 来确定每个元素应用哪些 CSS 规则以及最终计算的样式是什么(在应用级联、继承和默认样式后)。输出通常被概念化为每个 DOM 节点与计算样式的关联(该元素的已解析、最终 CSS 属性,例如元素的颜色、字体、大小等)。
值得注意的是,即使没有任何作者 CSS,每个元素都有默认的浏览器样式(用户代理样式表)。例如,<h1> 在几乎所有浏览器中都有默认的字体大小和边距。浏览器的内置样式规则以最低优先级应用,确保有合理的默认呈现效果。开发者可以在 DevTools 中查看计算样式,以确切了解元素最终具有哪些 CSS 属性。样式计算步骤会使用所有适用的样式(用户代理、用户样式、作者样式)来最终确定每个元素的样式。
渲染阻塞行为:虽然 HTML 解析可以在 CSS 完全加载之前进行,但存在渲染阻塞关系:浏览器通常会等待 CSS 加载后才执行首次渲染(对于 <head> 中的 CSS)。这是因为应用不完整的样式表可能会导致无样式内容闪烁。实际上,如果在 HTML 中 CSS <link> 之前出现未标记为 async/defer 的 <script>,脚本还会等待 CSS 加载后再执行(因为脚本可能通过 DOM API 查询样式信息)。作为经验法则,应将样式表链接放在头部(它们会阻塞渲染但需要早期加载),将非关键或大型脚本使用 defer/async 或放在底部,这样它们不会延迟 DOM 解析。
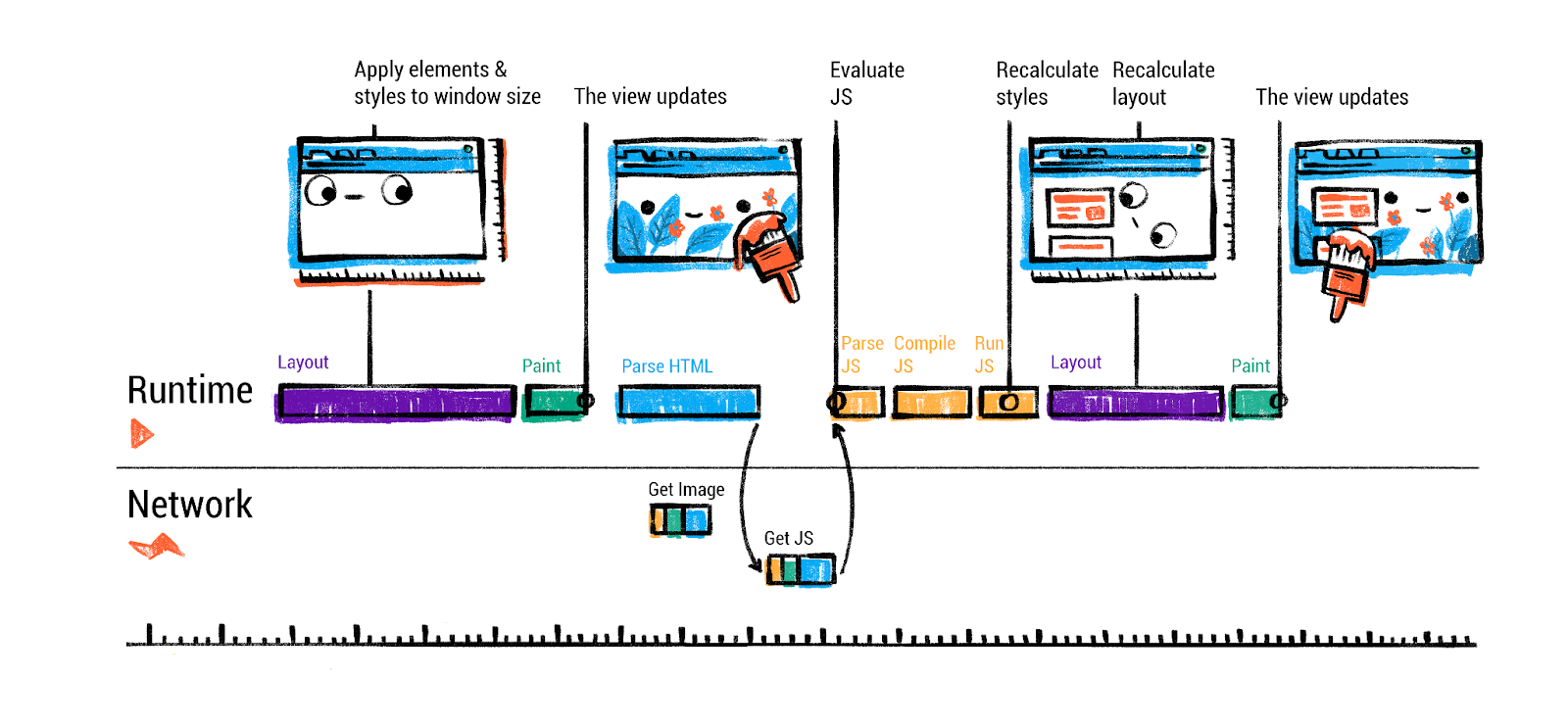
现在浏览器有了(1)从 HTML 构建的 DOM,(2)解析的 CSS 规则(CSSOM),以及(3)每个 DOM 节点的计算样式。这些一起构成了下一阶段的基础:布局。但在继续之前,我们应该更详细地考虑 JavaScript 方面——具体是 JS 引擎(Chrome 中的 V8)如何执行代码。我们涉及了脚本阻塞,但当 JS 运行时会发生什么?我们将在后面的部分专门讨论 V8 的内部机制和 JS 执行。现在,假设脚本运行时,它们可能会修改 DOM 或 CSSOM(例如,调用 document.createElement 或设置元素样式)。浏览器可能必须通过根据需要重新计算样式或布局来响应这些更改(如果重复进行,可能会产生性能成本)。解析期间脚本的初始运行通常包括设置事件处理程序,或者可能操作 DOM(例如模板化)。之后,页面通常完全解析,我们进入布局和渲染阶段。
样式和布局
在这个阶段,浏览器的渲染器进程知道 DOM 的结构和每个元素的计算样式。下一个问题是:所有这些元素在屏幕上的位置在哪里?它们有多大?这是布局(也称为”回流”或”布局计算”)的工作。在这个阶段,浏览器根据 CSS 规则(流、盒模型、flexbox 或 grid 等)和 DOM 层次结构计算每个元素的几何形状 - 它们的大小和位置。
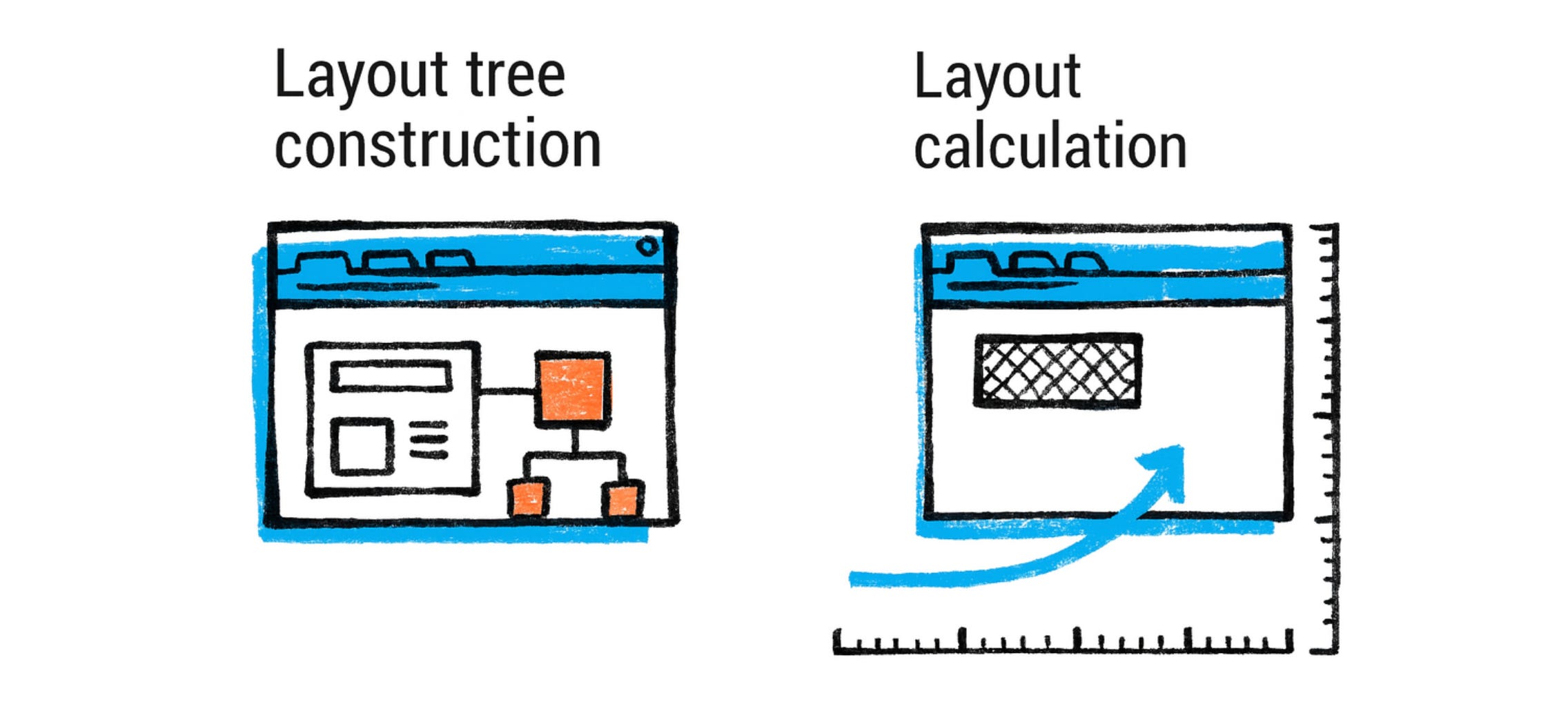
布局树构建:浏览器遍历 DOM 树并生成布局树(有时称为渲染树或框架树)。布局树在结构上类似于 DOM 树,但它会省略非可视元素(例如 script 或 meta 标签不产生框),如果需要,可能将某些元素拆分为多个框(例如,跨多行流动的单个 HTML 元素可能对应多个布局框)。布局树中的每个节点都保存该元素的计算样式,并具有节点内容(文本或图片)和影响布局的计算属性(如宽度、高度、内边距等)的信息。
在布局期间,浏览器计算每个元素框的确切位置(x、y 坐标)和大小(宽度、高度)。这涉及 CSS 规范定义的算法:例如,在正常文档流中,块级元素从上到下堆叠,默认情况下每个都占据全宽,而内联元素在行内流动,根据需要换行。像 flexbox 或 grid 这样的现代布局模式有自己的算法。引擎必须考虑字体度量来断行(因此文本布局涉及测量文本运行),并且必须处理边距、内边距、边框等。有许多边缘情况(例如边距折叠规则、浮动、从流中移除的绝对定位元素等),使布局成为一个令人惊讶的复杂过程。即使是”简单”的从上到下布局也必须弄清楚文本中的换行,这取决于可用宽度和字体大小。浏览器引擎有专门的团队和多年的开发来准确高效地处理布局。
关于布局树的一些细节:
-
display:none的元素完全从布局树中省略(它们不产生任何框)。相比之下,只是不可见的元素(例如visibility:hidden)确实会得到布局框(占用空间),只是稍后不绘制。 -
生成内容的伪元素如
::before或::after包含在布局树中(因为它们确实有可视框)。 -
布局树节点知道它们的几何形状。例如,
<p>元素的布局节点将知道其相对于视口的位置和尺寸,并为其内部的每行或内联框提供子节点。
布局计算:布局通常是一个递归过程。从根(<html> 元素)开始,浏览器计算视口的大小(对于 <html>/<body>),然后在其中布局子元素,依此类推。许多元素的大小取决于它们的子元素或父元素(例如,容器可能扩展以适应子元素,或子元素可能是其父元素宽度的 50%)。布局算法通常必须对浮动或某些复杂交互等事物进行多次传递,但通常它以一个方向(自上而下)进行,如果需要可能回溯。
在这个阶段结束时,每个元素在页面上的位置和大小都是已知的。我们现在可以概念性地将页面视为一堆框(内部有文本或图片)。但我们还没有在屏幕上实际绘制任何东西——这是下一步,绘制。
但是,一个关键概念:布局可能是一个昂贵的操作,特别是如果重复进行。如果 JavaScript 稍后更改元素的大小或添加内容,它可能会强制重新布局页面的某些或全部。开发者经常听到避免布局抖动的建议(如在修改 DOM 后立即在 JS 中读取布局信息,这可能强制同步重新计算)。浏览器尝试通过注意布局树的哪些部分是”脏的”并仅重新计算那些部分来优化。但最坏情况下,DOM 高层的更改可能需要为大页面重新计算整个布局。这就是为什么应该最小化昂贵的样式/布局操作以获得更好的性能。
样式和布局回顾:总结一下,从 HTML 和 CSS 浏览器构建:
- DOM 树 - 结构和内容
- CSSOM - 解析的 CSS 规则
- 计算样式 - 将 CSS 规则匹配到每个 DOM 节点的结果
- 布局树 - 过滤到可视元素的 DOM 树,每个节点都有几何形状
每个阶段都建立在上一个阶段的基础上。如果任何阶段发生变化(例如,如果脚本更改 DOM 或修改 CSS 属性),后续阶段可能需要更新。例如,如果你更改元素上的 CSS 类,浏览器可能会重新计算该元素(如果继承发生变化,还有子元素)的样式,然后如果样式更改影响几何形状(比如 display 或 size),可能必须重做布局,然后必须重新绘制。这个链条意味着布局和绘制依赖于最新的样式,依此类推。我们将在 DevTools 部分讨论这种性能影响(因为浏览器提供工具来查看这些步骤何时发生以及需要多长时间)。
布局完成后,我们进入下一个主要阶段:绘制。
绘制、合成和 GPU 渲染
绘制是获取结构化布局信息并实际在屏幕上产生像素的过程。在传统术语中,浏览器会遍历布局树并为每个节点发出绘制命令(“在这些坐标绘制背景、绘制文本、绘制图片”)。现代浏览器在概念上仍然这样做,但它们通常将工作分为多个阶段,并利用 GPU 提高效率。
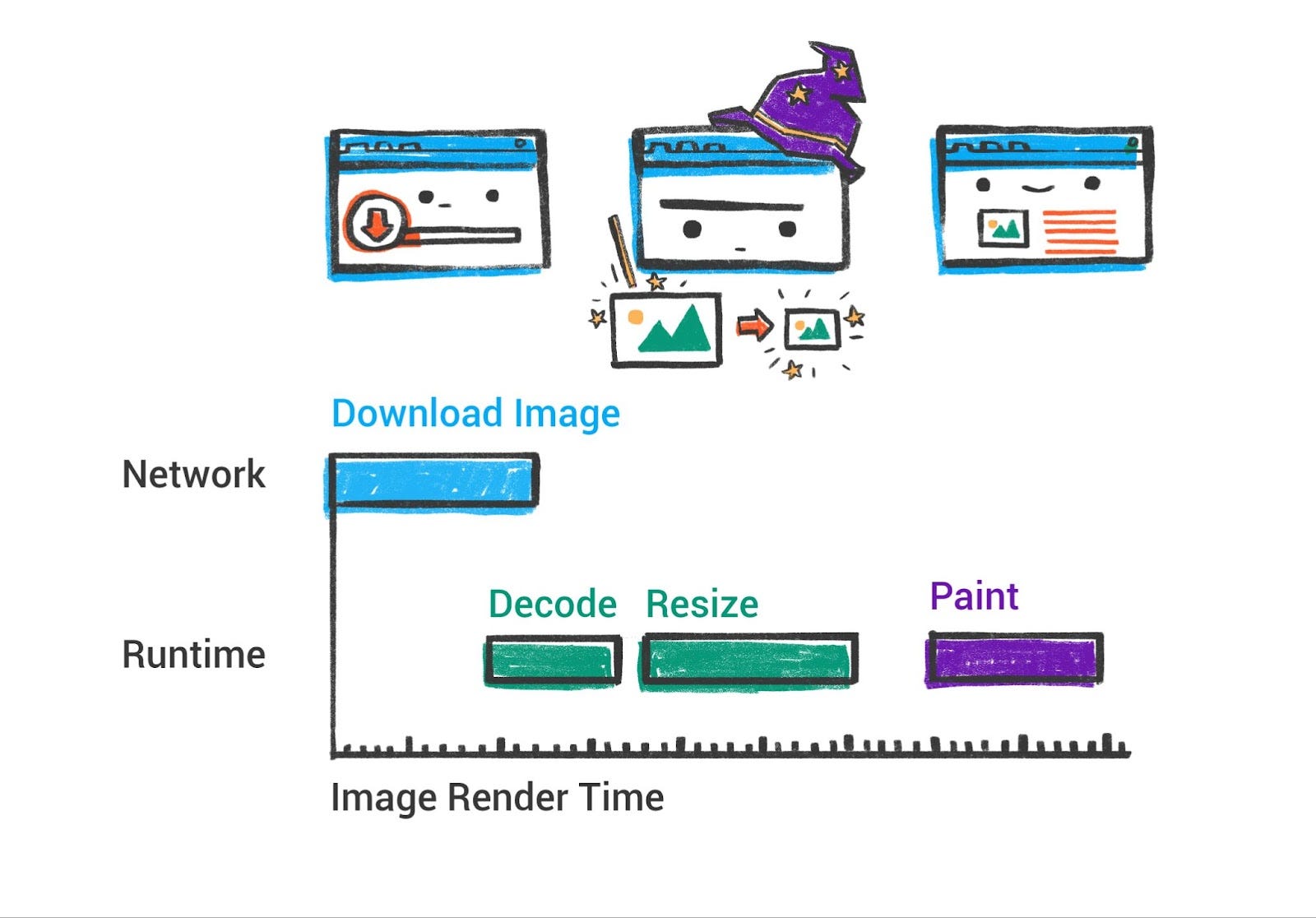
绘制/光栅化:在渲染器的主线程上,布局之后,Chrome 通过遍历布局树生成绘制记录(或显示列表)。这基本上是一个带有坐标的绘制操作列表,很像艺术家规划如何绘制场景:例如”在 (x,y) 绘制宽度为 W 高度为 H 填充颜色为蓝色的矩形,然后在 (x2,y2) 用字体 XYZ 绘制文本 ‘Hello’,然后在…绘制图片”等等。这个列表按正确的 z-index 顺序排列(以便重叠元素正确绘制)。例如,如果一个元素有更高的 z-index,它的绘制命令将在较低 z-index 内容之后(在其上方)。浏览器必须考虑堆叠上下文、透明度等以获得正确的顺序。
过去,浏览器可能只是按顺序直接将每个元素绘制到屏幕上。但如果页面的部分发生变化(你必须重新绘制所有内容),这种方法可能效率低下。现代浏览器通常记录这些绘制命令,然后使用合成步骤来组装最终图像,特别是在使用 GPU 加速时。
分层和合成:合成是一种优化,将页面分割为几个可以独立处理的层。例如,具有 CSS 变换或动画的定位元素可能获得自己的层。层就像单独的”草稿画布”——浏览器可以单独光栅化(绘制)每个层,然后合成器可以在屏幕上混合它们,通常使用 GPU。
在 Chromium 的管道中,生成绘制记录后,有一个步骤来构建层树(这对应于哪些元素在哪个层上)。一些层是自动创建的(例如视频元素、画布或具有某些 CSS 的元素将被提升到层),开发者可以通过使用 will-change 或 transform 等 CSS 属性来提示获得层。层有用的原因是层上的移动或不透明度变化可以合成(即只重新渲染或移动该层)而无需重新绘制整个页面。但是,太多层可能会占用大量内存并增加开销,因此浏览器会谨慎选择。
确定层后,Chrome 的主线程交给合成器线程。合成器线程在渲染器进程中运行,但与主线程分离(因此即使主 JS 线程繁忙,它也可以继续工作,这对于平滑滚动和动画很好)。合成器线程的工作是获取层,光栅化它们(将绘制转换为实际像素位图),并将它们合成为帧。
GPU 辅助光栅化:光栅工作也可以分布。在 Chrome 中,合成器线程将层分解为更小的瓦片(想象 256x256 或 512x512 像素块,当 GPU 光栅开启时通常更大,几乎总是如此)。然后它将这些分派给几个光栅工作线程(可能甚至跨多个 CPU 核心运行)进行并发光栅化。每个光栅工作者获取一个瓦片 - 本质上是该层区域的绘制命令列表 - 并产生位图(像素数据)。重要的是,Skia(Chrome 的图形库)可以使用 CPU 或 GPU 进行光栅化;在 Chrome 的情况下,这些光栅线程通常使用 CPU 渲染像素,然后将它们上传到 GPU 内存。Firefox 的较新 WebRender 采用了我们稍后会提到的不同方法。光栅化的瓦片作为纹理存储在 GPU 内存中。一旦所有需要的瓦片都绘制完成,合成器线程基本上就有了一组准备好的纹理层。
然后合成器组装一个合成器帧 - 基本上是向浏览器进程发送的消息,包括构成屏幕的所有四边形(层的瓦片)、它们的位置等。这个合成器帧通过 IPC 提交回浏览器进程,最终浏览器的 GPU 进程(Chrome 中用于访问 GPU 的单独进程)将获取这些并显示它们。浏览器进程自己的 UI(如标签栏)也通过合成器帧绘制,它们都在最后一步混合。GPU 进程接收帧,并使用 GPU(通过 OpenGL/DirectX/Metal 等)合成它们 - 基本上在屏幕上的正确位置绘制每个纹理,应用变换等,非常快。结果是你看到的最终图像。
这个管道的优势在滚动或动画时很明显。例如,滚动页面主要只是改变更大页面纹理上的视口。合成器可以只是移动层位置并要求 GPU 重绘进入视图的新部分,而无需主线程重新绘制所有内容。如果动画只是变换(比如移动一个自己层的元素),合成器线程可以更新该元素每帧的位置并产生新帧,而不涉及主线程或重新运行样式和布局。这就是为什么推荐”仅合成”的动画(更改 transform 或 opacity,不触发布局)以获得更好的性能 - 即使主线程繁忙,它们也可以以 60 FPS 平滑运行。相比之下,动画高度或背景颜色等可能强制每帧重新布局或重新绘制,如果主线程跟不上就会卡顿。
简而言之,Chrome 的渲染管道是:DOM → 样式 → 布局 → 绘制(记录显示项)→ 分层 → 光栅(瓦片)→ 合成(GPU)。Firefox 的管道在显示列表阶段之前概念上类似,但使用 WebRender 它跳过显式层构建,而是将显示列表发送到 GPU 进程,然后使用 GPU 着色器处理几乎所有绘制(稍后在比较部分详述)。WebKit(Safari)也使用多线程合成器和通过 macOS 上的”CALayers”进行 GPU 渲染。因此,所有现代引擎都利用 GPU 进行渲染,特别是用于合成和光栅化图形密集型部分,以实现高帧率并从 CPU 卸载工作。
在继续之前,让我们更详细地讨论 GPU 的作用。在 Chromium 中,GPU 进程是一个单独的进程,其工作是与图形硬件接口。它从所有渲染器合成器以及浏览器 UI 接收绘制命令(主要是高级的,如”在这些坐标绘制这些纹理”)。然后它将其转换为实际的 GPU API 调用。通过将其隔离在进程中,有问题的 GPU 驱动程序崩溃不会拖垮整个浏览器 - 只有 GPU 进程,可以重新启动。此外,它提供了沙盒边界(因为 GPU 处理潜在不受信任的内容,如画布绘制、WebGL 等,驱动程序中存在安全漏洞 - 在进程外运行可以减轻风险)。
合成的结果最终发送到显示器(浏览器运行的操作系统窗口或上下文)。对于每个动画帧(目标 60fps 或每帧 16.7ms 以获得平滑结果),合成器旨在产生一帧。如果主线程繁忙(比如 JavaScript 花费了很长时间),合成器可能跳过帧或无法更新,导致可见的卡顿。开发者工具可以在性能时间线中显示丢帧。像 requestAnimationFrame 这样的技术将 JS 更新与帧边界对齐,以帮助平滑渲染。
总之,浏览器的渲染引擎仔细地将页面内容和样式分解为一组几何形状(布局)和绘制指令,然后使用层和 GPU 合成有效地将其转换为你看到的像素。这个复杂的管道使 Web 上丰富的图形和动画能够以交互式帧率运行。接下来,我们将窥视 JavaScript 引擎,了解浏览器如何执行脚本(到目前为止我们将其视为黑盒子)。
JavaScript 引擎内部(V8)
JavaScript 驱动网页的交互行为。在 Chromium 浏览器中,V8 引擎执行 JavaScript(和 WebAssembly)。了解 V8 的工作原理可以帮助开发者编写高性能的 JS。虽然详尽的深入探讨需要一本书的篇幅,但我们将重点关注 JS 执行管道的关键阶段:解析/编译代码、执行代码和管理内存(垃圾收集)。我们还将注意 V8 如何处理现代功能,如即时(JIT)编译层和 ES 模块。
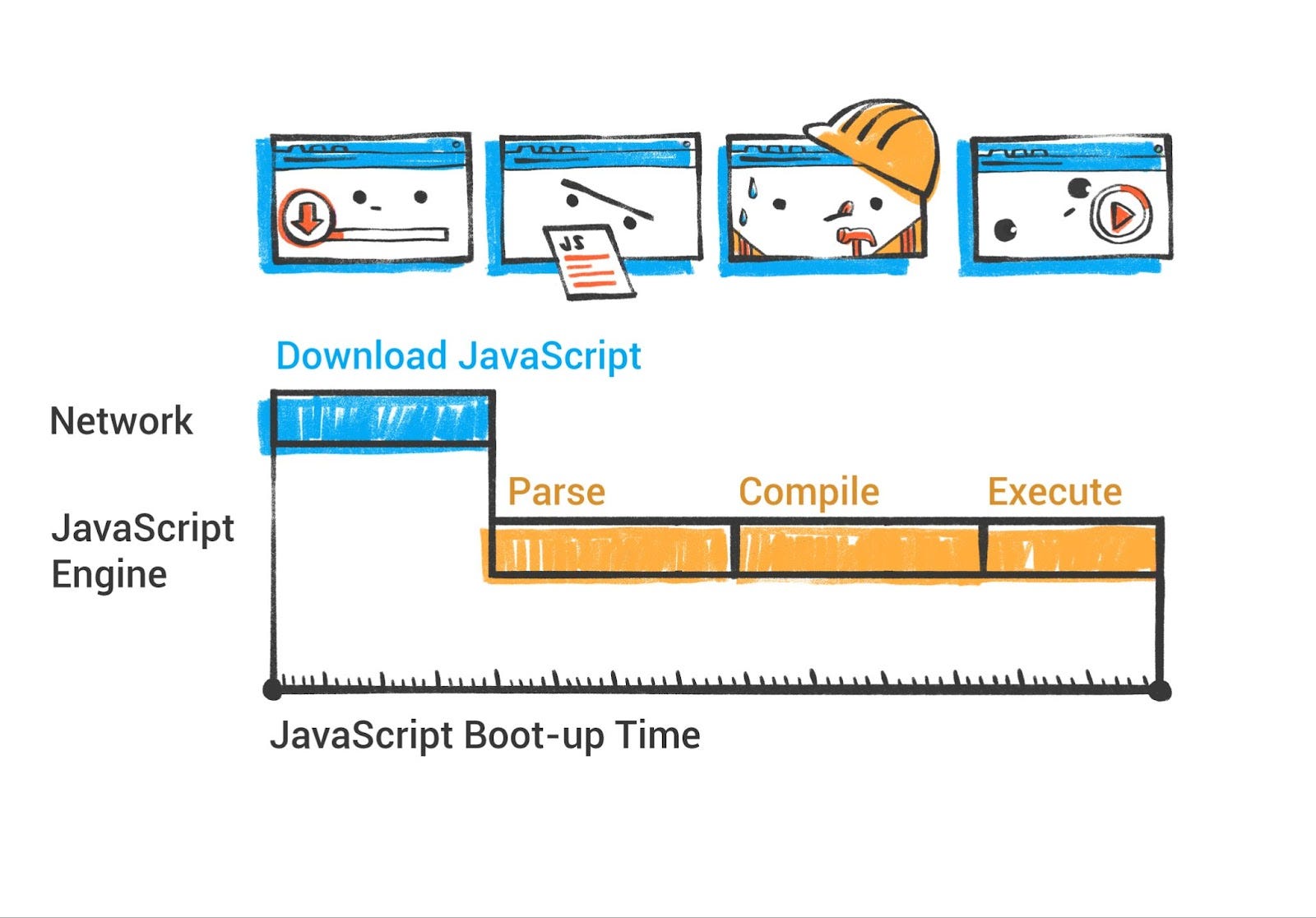
现代 V8 解析和编译管道
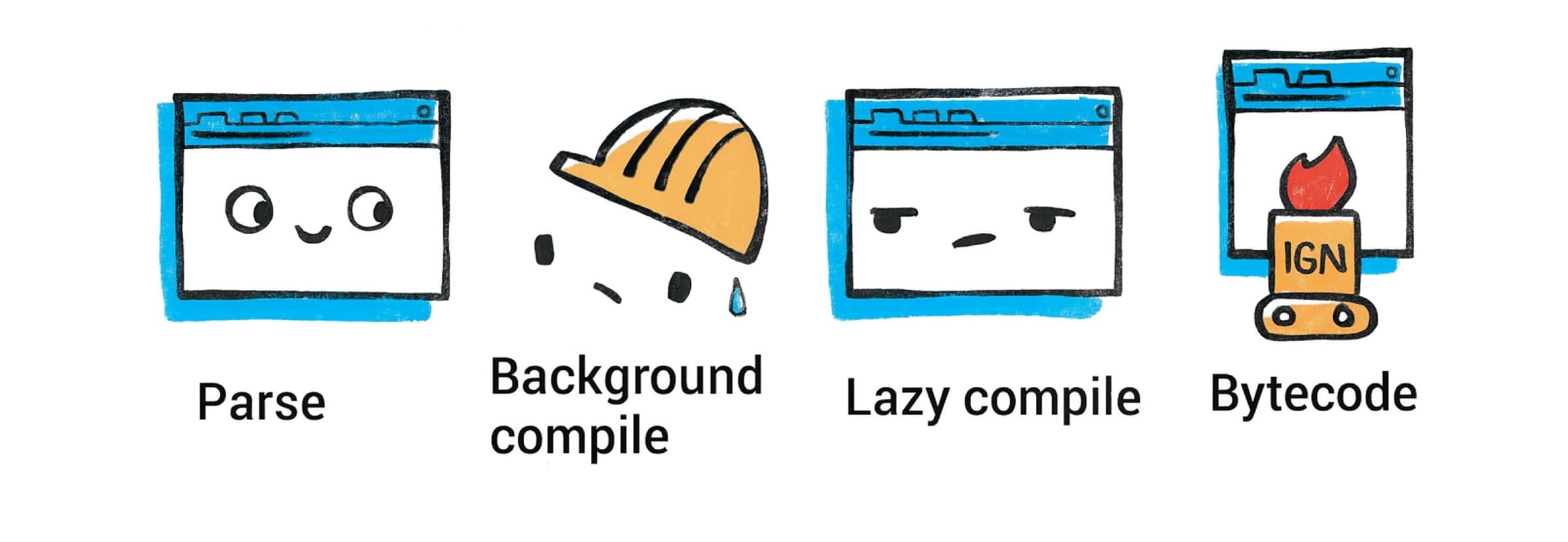
后台编译:从 Chrome 66 开始,V8 在后台线程上编译 JavaScript 源代码,在典型网站上将主线程上的编译时间减少了 5% 到 20%。自版本 41 以来,Chrome 通过 V8 的 StreamedSource API 支持在后台线程上解析 JavaScript 源文件。V8 可以在从网络下载第一个块时开始解析 JavaScript 源代码,并在流式传输文件时继续并行解析。几乎所有脚本编译都发生在后台线程上,只有短暂的 AST 内化和字节码最终化步骤在脚本执行前在主线程上发生。目前,顶级脚本代码和立即调用的函数表达式在后台线程上编译,而内部函数在首次执行时仍在主线程上延迟编译。
解析和字节码:当遇到 <script>(在 HTML 解析期间或稍后加载)时,V8 首先解析 JavaScript 源代码。这产生代码的抽象语法树(AST)表示。预解析器是解析器的副本,它执行跳过函数所需的最少工作。它验证函数在语法上有效,并产生外部函数正确编译所需的所有信息。当稍后调用预解析的函数时,它会按需完全解析和编译。
V8 不是直接从 AST 解释,而是使用名为 Ignition 的字节码解释器(2016 年引入)。Ignition 将 JavaScript 编译为紧凑的字节码格式,这本质上是虚拟机的指令序列。这种初始编译相当快,字节码相当低级(Ignition 是基于寄存器的虚拟机)。目标是快速开始执行代码,前期成本最小(对页面加载时间很重要)。
AST 内化过程:AST 内化涉及在 V8 堆上分配字面对象(字符串、数字、对象字面量样板)供生成的字节码使用。为了启用后台编译,这个过程在编译管道中被移到了后面,在字节码编译之后,需要修改以访问嵌入在 AST 中的原始字面值,而不是内化的堆上值。
显式编译提示:V8 引入了一个名为”显式编译提示”的新功能,允许开发者指示 V8 在加载时通过急切编译立即解析和编译代码。带有此提示的文件在后台线程上编译,而延迟编译在主线程上发生。对流行网页的实验显示,20 个案例中有 17 个性能改善,前台解析和编译时间平均减少 630ms。开发者可以使用特殊注释向 JavaScript 文件添加显式编译提示,为关键代码路径启用后台线程上的急切编译。
扫描器和解析器优化:V8 的扫描器已经显著优化,在各方面都有改进:单令牌扫描改进了大约 1.4×,字符串扫描改进了 1.3×,多行注释扫描改进了 2.1×,标识符扫描根据标识符长度改进了 1.2-1.5×。
当脚本运行时,Ignition 解释字节码,执行程序。解释通常比优化的机器代码慢,但它允许引擎开始运行,也收集关于代码行为的分析信息。当代码运行时,V8 收集关于如何使用它的数据:变量类型、经常调用哪些函数等。这些信息将用于在后续步骤中使代码运行更快。
JIT 编译层
V8 不止于解释。它采用多层即时编译器来加速热代码。想法是在运行很多的代码上花费更多编译努力,使其更快,同时不浪费时间优化只运行一次的代码。
-
Ignition(解释字节码)。
-
Sparkplug:V8 的基线 JIT 称为 Sparkplug(2021 年左右推出)。Sparkplug 获取字节码并快速编译为机器代码,没有重度优化。这产生比解释更快的本机代码,但 Sparkplug 不做深度分析 - 它意味着几乎和解释器一样快开始,但产生运行稍快的代码。
-
Maglev:2023 年,V8 引入了 Maglev,一个中层优化编译器,现在正在积极部署。Maglev 生成代码的速度比 Sparkplug 慢近 20 倍,但比 TurboFan 快 10 到 100 倍,有效地为中等热度但不足以进行 TurboFan 优化的函数填补了空白。Maglev 适用于有些热但不足以进行 TurboFan 的函数,或者当 TurboFan 的编译成本太高时。截至 Chrome M117,Maglev 可以处理许多情况,通过为在”温暖”代码(不冷,不超热)中花费时间的 Web 应用程序填补基线和最高层 JIT 之间的空白,从而实现更快的启动。
-
TurboFan:当函数或循环被执行很多次时,V8 将启用其最强大的优化编译器。TurboFan 获取代码并使用收集的类型反馈生成高度优化的机器代码,应用高级优化(内联函数、消除边界检查等)。如果假设成立,这种优化代码可以运行得更快。
因此,V8 现在有效地有四个执行层:Ignition 解释器、Sparkplug 基线 JIT、Maglev 优化 JIT 和 TurboFan 优化 JIT。这类似于 Java 的 HotSpot VM 有多个 JIT 级别(C1 和 C2)。引擎可以根据执行配置文件动态决定优化哪些函数以及何时优化。如果一个函数突然被调用一百万次,它很可能最终被 TurboFan 优化以获得最大速度。
Intel 还开发了配置文件引导分层,增强了 V8 的效率,在 Speedometer 3 基准测试中带来了大约 5% 的改进。最近的 V8 更新包括静态根优化,允许在编译时准确预测常用对象的内存地址,显著提高访问速度。
JIT 优化的一个挑战是 JavaScript 是动态类型的。V8 可能在某些假设下优化代码(例如这个变量总是整数)。如果稍后的调用违反了这些假设(比如变量变成字符串),优化代码就无效了。V8 然后执行去优化:它回退到不太优化的版本(或用新假设重新生成代码)。这种机制依赖于”内联缓存”和类型反馈来快速适应。去优化的存在意味着如果你的代码有不可预测的类型,有时峰值性能不会持续,但通常 V8 试图处理典型模式(如一个函数一致地传递相同类型的对象)。
字节码刷新和内存管理
V8 实现字节码刷新,如果函数在多次垃圾收集后仍未使用,其字节码将被回收。再次执行时,解析器使用先前存储的结果更快地重新生成字节码。这种机制对内存管理至关重要,但在边缘情况下可能导致解析不一致。
内存管理(垃圾收集):V8 使用垃圾收集器自动管理 JS 对象的内存。多年来,V8 的 GC 已经发展成所谓的 Orinoco GC,这是一个分代、增量和并发垃圾收集器。要点:
-
分代:V8 按年龄分离对象。新对象分配在年轻代(或”托儿所”)。这些经常用非常快的清理算法(将活对象复制到新空间并回收其余部分)收集。存活足够周期的对象被提升到老年代。
-
标记-清扫/压缩:对于老年代,V8 使用带压缩的标记-清扫收集器。这意味着它偶尔会停止世界(短暂停止 JS 执行),标记所有可达对象(从全局对象等根追踪),然后清扫回收未引用对象的内存。它也可能压缩内存(移动对象以减少碎片)。但是,Orinoco 使大部分标记并发 - 它可以在 JS 仍在运行时在后台线程上进行大量标记工作,以最小化暂停时间。
-
增量 GC:V8 在可能的情况下以小片段而不是一个大暂停执行垃圾收集。这种增量方法将工作分散以避免卡顿。例如,它可以在脚本执行之间穿插一点标记工作,使用空闲时间。
-
并行 GC:在多核机器上,V8 也可以在并行线程中执行 GC 的部分(如标记或清扫)。
净效果是 V8 团队多年来已经大幅减少了 GC 暂停时间,使垃圾收集在大型应用程序中几乎不被注意到。小 GC(新对象清理)通常发生得非常快。大 GC(老年代)更罕见,现在大多是并发的。如果你打开 Chrome 的任务管理器或 DevTools 内存面板,你可能会看到 V8 的堆分为”年轻空间”和”老空间”,反映这种分代设计。
对于开发者,这意味着不需要手动内存管理,但你仍应该注意:例如避免在紧密循环中创建大量短期对象(尽管 V8 在处理短期对象方面相当好),并意识到持有大型数据结构会使它们保留在内存中。像 DevTools 这样的工具可以强制垃圾收集或记录内存配置文件以查看什么在使用内存。
V8 和 Web API:值得一提的是,V8 涵盖核心 JavaScript 语言和运行时(执行、标准 JS 对象等),但许多”浏览器 API”(如 DOM 方法、alert()、网络 XHR/fetch 等)不是 V8 本身的一部分。这些由浏览器提供,通过绑定暴露给 JS。例如,当你调用 document.querySelector 时,在底层它进入引擎对 C++ DOM 实现的绑定。V8 处理调用 C++ 并获取结果,有很多机制使这个边界快速(Chrome 使用 IDL 生成高效绑定)。
在介绍了浏览器如何获取资源、解析 HTML/CSS、计算布局、用 GPU 绘制和运行 JS 之后,我们现在对加载和渲染页面的整个过程有了一个图景。但还有更多要探索的:ES 模块如何处理(因为模块涉及它们自己的加载机制)、浏览器的多进程架构如何组织,以及沙盒和站点隔离等安全功能如何工作。
模块加载和导入映射
JavaScript 模块(ES6 模块)引入了与经典 <script> 标签不同的加载和执行模型。模块不是可能创建全局变量的大脚本文件,而是显式导入/导出值的文件。让我们看看浏览器(特别是 Chrome 中的 V8)如何加载模块,以及动态 import() 和导入映射等功能如何发挥作用。
静态模块导入:当浏览器遇到 <script type="module" src="main.js"> 时,它将 main.js 视为模块入口点。加载过程如下:浏览器将获取 main.js,然后将其解析为 ES 模块。在解析期间,它将找到任何导入语句(例如 import { foo } from './utils.js';)。浏览器不是立即执行代码,而是构建模块依赖图。它将启动获取任何导入的模块(在这种情况下是 utils.js),递归地,每个模块都被解析为它们的导入,获取,依此类推。这异步发生。只有一旦整个模块图被获取和解析,浏览器才能评估模块。模块脚本本质上是延迟的——浏览器不执行模块代码,直到所有依赖项都准备好。然后它按依赖顺序执行它们(确保如果模块 A 导入 B,B 先运行)。
这种静态导入过程是为什么 ES 模块在某些情况下无法从 file:// 加载,除非允许,以及为什么它们默认需要 CORS 用于跨源脚本——浏览器正在积极链接和加载多个文件,而不仅仅是将 <script> 放入页面。
动态 import():除了静态导入语句,ES2020 引入了 import(moduleSpecifier) 作为表达式。这允许代码动态加载模块(返回解析为模块导出的 promise)。例如,你可能在响应用户操作时执行 const module = await import('./analytics.js'),从而对应用程序进行代码分割。在底层,import() 触发浏览器获取请求的模块(及其依赖项,如果尚未加载),然后实例化和执行它,并用模块命名空间对象解析 promise。V8 和浏览器在这里协调:浏览器的模块加载器处理获取和解析,V8 在准备好后处理编译和执行。动态导入很强大,因为它也可以在非模块脚本中使用(例如内联脚本可以动态导入模块)。它本质上给开发者控制按需加载 JS。与静态导入的区别是静态导入提前解析(在任何模块代码运行之前,整个图被加载),而动态导入更像在运行时加载新脚本(除了具有模块语义和 promise)。
导入映射:ES 模块在浏览器中的一个挑战是模块说明符。在 Node 或打包器中,你经常按包名导入(例如 import { compile } from 'react')。在没有打包器的 Web 上,‘react’ 不是有效的 URL——浏览器会将其视为相对路径(这会失败)。这就是导入映射的用武之地。导入映射是一个 JSON 配置,告诉浏览器如何将模块说明符解析为真实 URL。它通过 HTML 中的 <script type="importmap"> 标签提供。例如,导入映射可能说说明符”react”映射到”https://cdn.example.com/react@19.0.0/index.js”(某个脚本的完整 URL)。然后,当任何模块执行 import 'react' 时,浏览器使用映射找到 URL 并加载它。本质上,导入映射允许”裸”说明符(如包名)通过将它们映射到 CDN URL 或本地路径在 Web 上工作。
导入映射对无打包开发来说是一个游戏改变者。自 2023 年以来,导入映射在所有主要浏览器中都得到支持(Chrome 89+、Firefox 108+、Safari 16.4+ - 所有三个引擎)。它们对于本地开发或你想在没有构建步骤的情况下使用模块的简单应用程序特别有用。对于生产,大型应用程序通常仍然打包以提高性能(减少请求数量),但随着浏览器和 HTTP/2/3 的改进,提供许多小模块变得更可行。
因此,浏览器中的模块加载器包括:模块映射(跟踪已加载的内容),可能的导入映射(用于自定义解析)和获取/解析逻辑。一旦获取和编译,模块代码在严格模式下执行,并具有自己的顶级作用域(除非显式附加,否则不会泄漏到 window)。导出被缓存,因此如果另一个模块稍后导入相同的模块,它不会重新运行(它重用已评估的模块记录)。
还要提到的一个方面是 ES 模块与脚本不同,延迟执行,也按给定图的顺序执行。如果 main.js 导入 util.js,util.js 导入 dep.js,评估顺序将是:首先 dep.js,然后 util.js,然后 main.js(深度优先,后序)。这种确定性顺序可以避免在某些情况下需要 DOMContentLoaded 等,因为当你的主模块运行时,所有导入都已加载和执行。
从 V8 的角度来看,模块由相同的编译管道处理,但它们创建单独的 ModuleRecords。引擎确保模块的顶级代码只有在所有依赖项准备好后才运行。V8 还必须处理循环模块导入(这是允许的,可能导致部分初始化的导出)。细节按规范 - 但本质上,引擎将创建所有模块实例,然后通过给它们占位符来解析循环,然后以尊重依赖关系的顺序执行(规范算法是模块图的”DAG”拓扑排序)。
总之,浏览器中的模块加载是网络(获取模块文件)、模块解析器(使用导入映射或标准 URL 解析)和 JS 引擎(以正确顺序编译和评估模块)之间的协调舞蹈。它比旧的 <script> 加载更复杂,但产生更模块化和可维护的代码结构。对于开发者,关键要点是:使用模块来组织代码,如果你想要裸导入就使用导入映射,并知道你可以在需要时通过 import() 动态加载模块。浏览器将处理确保一切以正确顺序执行的繁重工作。
现在我们已经介绍了单个页面的内部工作原理,让我们放大并检查允许多个页面、标签和 Web 应用程序同时运行而不相互干扰的浏览器架构。这将我们带到多进程模型。
浏览器多进程架构
现代浏览器(Chrome、Firefox、Safari、Edge 等)都使用多进程架构来实现稳定性、安全性和性能隔离。不是将整个浏览器作为一个巨大的进程运行(这是早期浏览器的工作方式),浏览器的不同方面在不同的进程中运行。Chrome 在 2008 年是这种方法的先驱,其他浏览器以各种形式跟进。让我们重点关注 Chromium 的架构,并注意 Firefox 和 Safari 的差异。
在 Chromium(Chrome、Edge、Brave 等)中,有一个中心的浏览器进程。这个浏览器进程负责 UI(地址栏、书签、菜单 - 所有浏览器 chrome)和协调高级任务,如资源加载和导航。当你打开 Chrome 并在操作系统任务管理器中看到一个条目时,那就是浏览器进程。它也是生成其他进程的父进程。
然后,对于每个标签(有时对于标签中的每个站点),Chrome 创建一个渲染器进程。渲染器进程为该标签的内容运行 Blink 渲染引擎和 V8 JS 引擎。一般来说,每个标签至少获得一个渲染器进程。
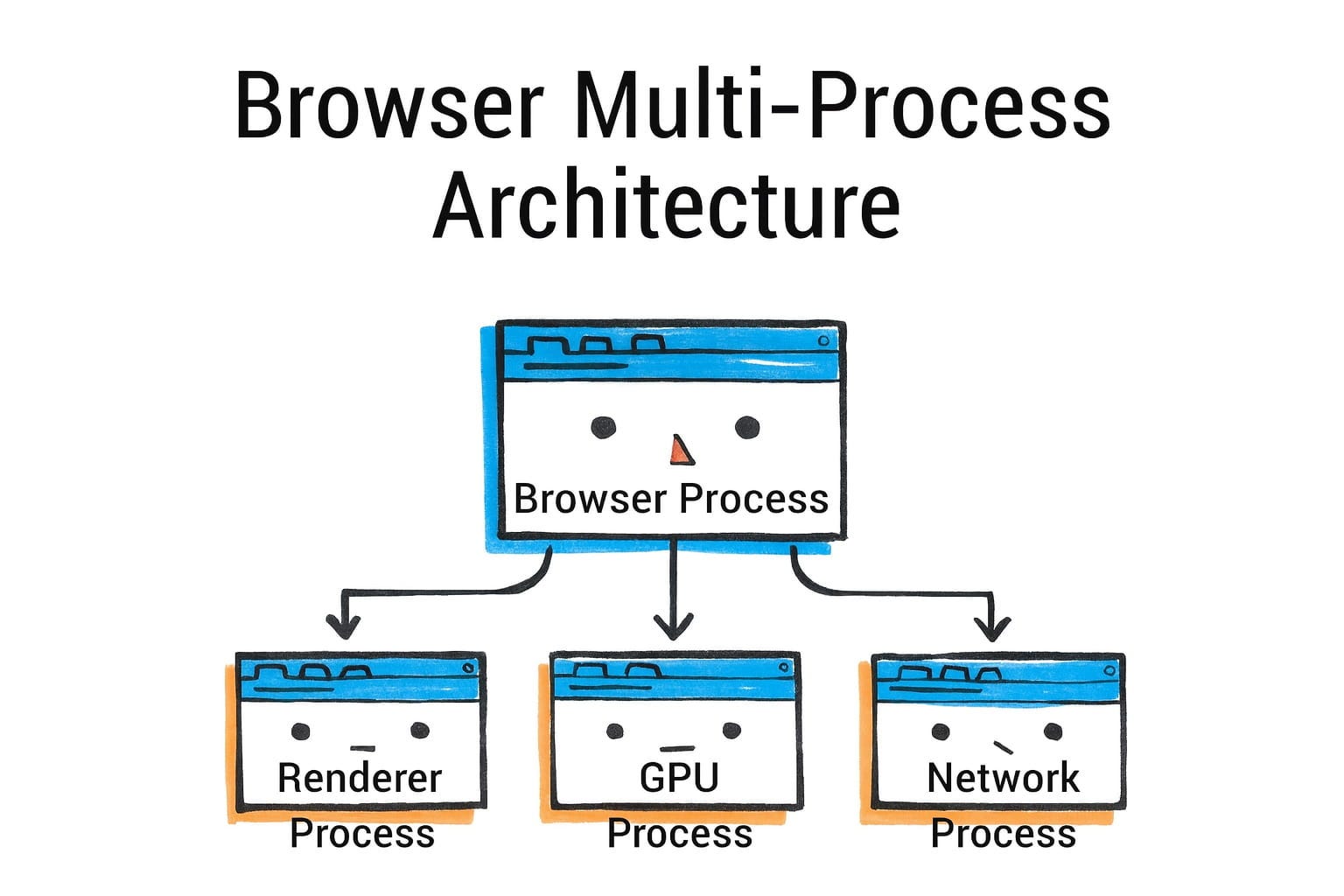
如果你打开多个不相关的站点,它们将在单独的进程中(站点 A 在一个,站点 B 在另一个,等等)。Chrome 甚至将跨源 iframe 隔离到单独的进程中(稍后在站点隔离中详述)。渲染器进程是沙盒化的,不能直接访问你的文件系统或网络 - 它必须通过浏览器进程进行这些特权操作。
Chrome 中的其他关键进程包括:
-
GPU 进程:专门用于与 GPU 通信的进程(如前所述)。来自渲染器的所有渲染和合成请求都发送到 GPU 进程,该进程实际发出图形 API 调用。这个进程是沙盒化和分离的,因此 GPU 崩溃不会拖垮渲染器。
-
网络进程:(在较旧的 Chrome 版本中,网络是浏览器进程中的线程,但现在通过”服务化”通常是单独的进程)。这个进程处理网络请求、DNS 等,可以单独沙盒化。
-
实用程序进程:这些用于各种服务(如音频播放、图像解码等),Chrome 可能会卸载。
-
插件进程:在 Flash 和 NPAPI 插件时代,插件在自己的进程中运行。Flash 现在已弃用,所以这不太相关,但架构仍然准备好让插件不在主浏览器进程中运行。
-
扩展进程:Chrome 扩展(本质上是可以作用于网页或浏览器的脚本)也在单独的进程中运行,与网站隔离以确保安全。
简化的视图是:一个浏览器进程协调多个渲染器进程(每个标签或每个站点实例一个),加上一个 GPU 进程和一些其他服务。Chrome 的任务管理器(Windows 上的 Shift+Esc 或通过更多工具 > 任务管理器)实际上会列出每种进程类型及其内存使用情况。
多进程的好处:主要好处是:
-
稳定性:如果网页(渲染器进程)崩溃或泄漏内存,它不会崩溃整个浏览器 - 你可以关闭该标签,其余部分保持活动。在单进程浏览器中,单个坏脚本可能拖垮一切。Chrome 可以在其进程死亡时为单个标签显示”啊,崩溃”错误,你可以独立重新加载它。
-
安全(沙盒化):通过在受限进程中运行 Web 内容,浏览器可以限制该代码在你的系统上可以做什么。即使攻击者在渲染引擎中发现漏洞,他们也被困在沙盒中 - 渲染器进程通常无法读取你的文件或任意打开网络连接或启动程序。它必须向浏览器进程请求文件访问等,这可以验证或拒绝。这个沙盒在操作系统级别强制执行(根据平台使用作业对象、seccomp 过滤器等)。
-
性能隔离:一个标签中的密集工作(重型 webapp 或无限循环)主要限制在该标签的渲染器进程中。其他标签(不同进程)可以保持响应,因为它们的进程没有被阻塞。此外,操作系统可以在不同的 CPU 核心上调度进程 - 因此两个重型页面可以在多核系统上比它们是一个进程的线程更好地并行运行。
-
内存分段:每个进程都有自己的地址空间,因此内存不共享。这防止一个站点窥探另一个站点的数据,也意味着当标签关闭时,操作系统可以有效地回收该进程的所有内存。缺点是由于重复资源和进程的一些开销(每个渲染器加载自己的 JS 引擎副本等)。
站点隔离:最初,Chrome 的模型是每个标签一个进程。随着时间的推移,他们将其发展为每个站点一个进程(特别是在 Spectre 之后 - 见下一节关于安全)。截至 2024 年,站点隔离默认为桌面平台上 99% 的 Chrome 用户启用,Android 支持继续完善。这意味着如果你有两个标签都打开到 example.com,Chrome 可能决定为两者使用一个进程(为了节省内存,因为它们是同一站点,因此放在一起风险较小)。但是一个带有 example.com 和 evil.com iframe 的标签默认会将 evil.com 的 iframe 放在与父页面分离的单独进程中(以保护 example.com 数据)。这种强制执行是 Chrome 称为”严格站点隔离”的(大约在 Chrome 67 作为默认启动)。站点隔离导致 Chrome 由于增加的进程创建而使用 10-13% 更多的系统资源,但提供了关键的安全好处。
Firefox 的架构,称为 Electrolysis(e10s),历史上是所有标签一个内容进程(多年来 Firefox 是单进程的,直到 2017 年左右才启用几个内容进程)。截至 2021 年,Firefox 使用多个内容进程(默认为 Web 内容 8 个)。通过 Project Fission(站点隔离),Firefox 正在向类似地隔离站点发展 - 它可以为跨站点 iframe 启动新进程,在 Firefox 108+ 中他们默认启用站点隔离,潜在地将进程数量增加到像 Chrome 一样每个站点一个。Firefox 也有 GPU 进程(用于 WebRender 和合成)和单独的网络进程,类似于 Chrome 的分割。因此实际上,Firefox 现在有一个非常像 Chrome 的模型:父进程、GPU 进程、网络进程、几个内容(渲染器)进程,以及一些实用程序进程(用于扩展、媒体解码等 - 例如媒体插件可以隔离运行)。
Safari(WebKit)同样转向多进程模型(WebKit2),其中每个标签的内容在单独的 WebContent 进程中,中央 UI 进程控制它们。Safari 的 WebContent 进程也是沙盒化的,不能直接访问设备或文件而不通过 UI 进程。Safari 也有一个共享的网络进程(可能还有其他助手)。因此虽然实现不同,概念是一致的:将每个网页的代码隔离在自己的沙盒环境中。
一个重要点是进程间通信(IPC):这些进程如何相互交谈?浏览器使用 IPC 机制(在 Windows 上,通常是命名管道或其他操作系统 IPC;在 Linux 上,可能是 Unix 域套接字或共享内存;Chrome 有自己的 IPC 库 Mojo)。例如,当网络响应到达网络进程时,它需要传递给正确的渲染器进程(通过浏览器进程协调)。类似地,当你执行 DOM fetch() 时,JS 引擎将调用网络 API,该 API 向网络进程发送请求,依此类推。IPC 增加了复杂性,但浏览器大量优化(例如使用共享内存有效传输大数据如图像,并发布异步消息以避免阻塞)。
进程分配策略:Chrome 并不总是为每个单独的标签创建全新的进程 - 有限制(特别是在内存不足的设备上,它可能为同站点标签重用进程)。如果你打开同一站点的另一个标签,Chrome 将重用现有渲染器以节省内存(这就是为什么有时同一站点的两个标签共享进程)。它也有总进程限制(可以根据 RAM 扩展)。当达到限制时,它可能开始将多个不相关的站点放在一个进程中,尽管如果启用站点隔离,它会努力避免混合站点。在 Android 上,Chrome 由于内存限制使用更少的进程(通常最多 5-6 个内容进程)。
Chromium 中的另一个概念是服务化:将浏览器组件拆分为可以在单独进程中运行的服务。例如,网络服务被制作为可以进程外运行的单独模块。想法是模块化 - 强大的系统可以在自己的进程中运行每个服务,而受限设备可能将一些服务合并回一个进程以节省开销。Chrome 可以在运行时或构建时决定如何部署这些服务。如片段中所述,在高端它可能分割一切(UI、网络、GPU 等都分离),在低端(Android)它可能将浏览器和网络合并在一个进程中以减少开销。
要点:Chromium 的架构旨在在不同的沙盒中运行浏览器 UI 和每个站点,使用进程作为隔离边界。Firefox 和 Safari 已经收敛到类似的设计。这种架构以更多内存使用为代价大大提高了安全性和可靠性。Web 内容进程被视为不受信任的,这就是站点隔离(下一节)发挥作用的地方,甚至在单独的进程中将不同的源彼此隔离。
站点隔离和沙盒化
站点隔离和沙盒化是建立在多进程基础上的安全功能。它们旨在确保即使恶意代码在浏览器中运行,它也不能轻易从其他站点窃取数据或访问你的系统。
站点隔离:我们已经涉及了这一点——它意味着不同的网站(更严格地说,不同的站点)在不同的渲染器进程中运行。Chrome 的站点隔离在 2018 年 Spectre 漏洞曝光后得到了推动。Spectre 显示恶意 JavaScript 可能通过利用 CPU 推测执行读取它不应该读取的内存。如果两个站点在同一进程中,恶意站点可能使用 Spectre 窥探敏感站点(如你的银行站点)的内存。唯一强大的解决方案是根本不让它们共享进程。因此 Chrome 使站点隔离成为默认:每个站点获得自己的进程,包括跨源 iframe。Firefox 通过 Project Fission(在最近版本中默认启用)跟进,旨在相同——他们引用在自己的进程中隔离每个站点以确保安全。这是与过去的重大变化,过去如果你有一个父页面和来自各个域的多个 iframe,它们可能都生活在一个进程中(特别是如果它们在一个标签中)。现在,这些 iframe 将被分割,以便例如好站点页面上的 <iframe src="https://evil.com"> 被强制进入不同的进程,防止甚至低级攻击在它们之间泄漏信息。
从开发者的角度来看,站点隔离大多是透明的。一个含义是嵌入式 iframe 和其父级之间的通信现在可能跨越进程边界,因此它们之间的 postMessage 等在底层通过 IPC 实现。但浏览器使这无缝;你作为开发者只是正常使用 API。
沙盒化:每个渲染器进程(和其他辅助进程)在具有受限权限的沙盒中运行。例如,在 Windows 上,Chrome 使用作业对象并删除权限,因此渲染器无法调用访问系统的大多数 Win32 API。在 Linux 上,它使用命名空间和 seccomp 过滤器来限制系统调用。渲染器基本上可以计算和渲染内容,但如果它尝试打开文件或摄像头或麦克风,它将被阻塞(除非通过适当的渠道请求通过浏览器进程的用户权限)。WebKit 的文档明确指出 WebContent 进程没有直接访问文件系统、剪贴板、设备等的权限——它们必须通过调解的 UI 进程请求。这就是为什么,例如,当站点尝试使用你的麦克风时,权限提示由浏览器 UI(浏览器进程)显示,如果允许,实际录制在受控进程中完成。沙盒是关键的防线。即使攻击者发现在渲染器中运行本机代码的错误,他们然后面临沙盒屏障——他们需要单独的漏洞(“逃逸”)来突破到系统。这种分层方法(称为站点隔离 + 沙盒)是浏览器安全的最先进技术。
Firefox 的沙盒化现在也相当严格(在早期 e10s 时代较弱,但他们加强了)。Firefox 内容进程也不能直接访问太多;Firefox 也沙盒化 GPU 进程以处理图形驱动程序问题。
进程外 iframe(OOPIF):在 Chrome 的站点隔离实现中,他们发明了术语 OOPIF 用于进程外 iframe。从用户的角度来看,什么都没有改变,但在 Chrome 的内部架构中,页面的每个框架都可能由不同的渲染器进程支持。顶级框架和同站点框架共享一个进程;跨站点框架使用不同的进程。所有这些进程”合作”渲染单个标签的内容,由浏览器进程协调。这相当复杂,但 Chrome 有一个可以跨进程的框架树。这意味着你的一个标签可能运行 N 个进程(一个用于主文档,其他用于每个跨站点子文档)。它们通过 IPC 通信,用于跨边界的 DOM 事件或涉及跨上下文的某些 JavaScript 调用等。Web 平台(通过 COOP/COEP、SharedArrayBuffer 等规范)在 Spectre 之后正在考虑这些约束而发展。
内存和性能成本:站点隔离确实增加了内存使用,因为使用了更多进程。Chrome 开发者注意到在某些情况下可能有 10-20% 的内存开销。他们通过对同站点的”尽力而为进程合并”和限制可以生成多少进程(我们之前提到过)来缓解一些。Firefox 最初由于内存担忧没有隔离每个站点,但在 Spectre 之后他们找到了更有效的方法,通过 8 特权进程限制和按需进程创建。Safari 历史上有强大的进程模型,但我不确定它是否隔离跨站点 iframe;WebKit2 肯定隔离顶级页面。苹果的重点通常也在隐私上(智能跟踪预防将分区 cookie 等),但这是不同的层。
出于隐私原因,跨站点预取受到限制,目前只有在用户没有为目标站点设置 cookie 时才会工作,防止站点通过可能永远不会访问的预取页面跟踪用户活动。
总而言之,站点隔离确保应用最小权限原则:来自源 A 的代码不能访问来自源 B 的数据,除非通过具有明确同意的 Web API(如 postMessage 或分区的存储)。沙盒确保即使代码是恶意的,它也不能直接触及你的系统。这些措施使浏览器漏洞变得更加困难 - 攻击者现在通常需要多个链式漏洞(一个破坏渲染器,一个逃脱沙盒)才能造成严重损害,这大大提高了门槛。
作为 Web 开发者,你可能不会直接感受到站点隔离,但你通过更安全的 Web 从中受益。需要注意的一点是跨源交互可能有稍微更多的开销(由于 IPC),并且一些优化如进程内脚本共享在跨源之间是不可能的。但浏览器正在不断优化进程之间的消息传递,以最小化任何性能影响。
Now, after covering security, let’s turn to tools and performance instrumentation - essentially, how we developers can peek into this pipeline and measure or debug it.
比较 Chromium、Gecko 和 WebKit
我们主要描述了 Chrome/Chromium 的行为(用于 HTML/CSS 的 Blink 引擎,用于 JS 的 V8,通过 Aura/Chromium 基础设施的多进程)。其他主要引擎 - Mozilla 的 Gecko(用于 Firefox)和 Apple 的 WebKit(用于 Safari)- 共享相同的基本目标和大致相似的管道,但有值得注意的差异和历史分歧。
共同概念:所有引擎都将 HTML 解析为 DOM,将 CSS 解析为样式数据,计算布局,并绘制/合成。所有都有带 JIT 和垃圾收集的 JS 引擎。所有现代的都是多进程(或至少多线程)以实现并行性和安全性。
CSS/样式系统的差异
一个有趣的差异是渲染引擎如何实现 CSS 样式计算:
-
Blink(Chromium):使用 C++ 中的单线程样式引擎(历史上基于 WebKit 的)。它为 DOM 树顺序计算样式。它有增量样式失效优化,但总的来说它是一个线程做工作(除了动画中的一些小并行化)。
-
Gecko(Firefox):在 Quantum 项目(2017)中,Firefox 集成了 Stylo,一个用 Rust 编写的新 CSS 引擎,它是多线程的。Firefox 可以使用所有 CPU 核心并行计算不同 DOM 子树的样式。这是 Gecko 中 CSS 的重大性能改进。因此,Firefox 中的样式重新计算可能使用 4 个核心来完成 Blink 在 1 个核心上做的事情。这是 Gecko 方法的一个优势(以复杂性为代价)。
-
WebKit(Safari):WebKit 的样式引擎像 Blink 一样是单线程的(因为 Blink 在 2013 年从 WebKit 分叉,它们在那之前共享架构)。WebKit 做了一些有趣的事情,比如 CSS 选择器匹配的字节码 JIT。它可能将 CSS 选择器转换为字节码并 JIT 编译匹配器以提高速度。Blink 没有采用这种方法(它使用迭代匹配)。
因此,在 CSS 方面,Gecko 通过 Rust 的并行样式计算脱颖而出。Blink 和 WebKit 依赖优化的 C++ 和可能一些 JIT 技巧(在 WebKit 的情况下)。
布局和图形
所有三个引擎都实现 CSS 盒模型和布局算法。特定功能可能在一个引擎中比其他引擎更早实现(例如,一度 WebKit 在 CSS Grid 支持方面领先,然后 Blink 赶上 - 它们经常通过标准机构共享代码)。
Firefox(Gecko)通过引入 WebRender 作为其合成器/光栅化器做出了巨大改变。WebRender 现在是 Firefox 中的默认渲染引擎,并为图形密集型 Web 内容的性能改进做出了重大贡献。WebRender(也是 Rust)基本上获取显示列表并直接在 GPU 上渲染它,使用 GPU 处理形状镶嵌、文本等。这就像将更多绘制工作移到 GPU。在 Chrome 的管道中,光栅化仍然在 CPU 上完成(对于大多数内容),然后作为位图发送到 GPU。WebRender 尝试避免为整个层制作位图,而是在 GPU 上绘制矢量(除了它缓存为图集纹理的文本字形)。这意味着 Firefox 可能以高性能动画更多内容,因为如果只有小部分发生变化,它不需要重新光栅化所有内容 - 它可以通过 GPU 非常快速地重绘。这类似于游戏引擎如何使用 GPU 调用每帧重绘场景。缺点是实现和调优复杂,可能更多地压力 GPU。但随着 GPU 功率的增长,这种方法是前瞻性的。Chrome 的团队考虑了类似的方法(“SKIA GPU”路径),但没有进行完整的 WebRender 风格的大修。
Safari(WebKit)使用更类似于较旧 Chrome 的方法:它有一个带层的合成器(称为 CALayer,因为在 Mac 和 iOS 上它使用 Core Animation 层)。Safari 很早就转向 GPU 合成(iPhone OS 和 Safari 4 在 2009 年对某些 CSS 如变换有硬件加速合成)。Safari 和 Chrome 分歧,但在概念上都进行平铺和合成。Safari 也大量卸载到 GPU(并使用平铺,特别是在 iOS 上,平铺绘制对平滑滚动是基础的)。
移动优化:每个引擎都有移动的特殊情况。例如,WebKit 有滚动的平铺覆盖概念(历史上在 iOS 的 UIWebView 中使用)。Android 上的 Chrome 使用”平铺”并尝试保持光栅任务最小以达到帧率。Firefox 的 WebRender 来自移动优先的 Servo 项目。
JavaScript 引擎
-
**V8(Chromium)**我们描述过:Ignition、Sparkplug、TurboFan、Maglev 截至 2023 年。
-
SpiderMonkey(Firefox):它历史上有解释器,然后是基线 JIT 和优化 JIT(IonMonkey)。最近的工作(Warp)改变了 JIT 层的工作方式,可能简化 Ion 并使其更像 TurboFan 使用缓存字节码和类型信息的方法。SpiderMonkey 也有不同的 GC(也是分代的,自 2012 年以来称为增量 GC,现在大多是增量/并发的)。
-
JavaScriptCore(Safari):如前所述,它有 4 层(LLInt、Baseline、DFG、FTL)。它使用不同的 GC(WebKit 的 GC 是分代标记-清扫,历史上称为 Butterfly 或 Boehm 变体,现在是 bmalloc 等)。JSC 的 FTL 使用 LLVM 进行优化,这是独特的(V8 和 SM 有自己的编译器,JSC 为一层利用 LLVM)。这可以产生非常快的代码,但编译很重。JSC 倾向于优先考虑某些基准测试的峰值性能(它经常在某些方面表现出色,但 V8 倾向于赶上;它们互相超越)。
在 ES 功能方面,由于 test262 和彼此的竞争,所有三个引擎都与最新标准保持同步。
多进程模型差异
-
Chrome:每个标签通常分离,源级别的站点隔离,大量进程(可能是几十个)。
-
Firefox:默认情况下进程较少(8 个内容进程处理所有标签,如果需要跨站点 iframe 与 Fission 则更多)。因此,它不一定是每个标签一个进程;标签在池中共享内容进程。这意味着 Firefox 在多标签场景下可能有更低的内存使用,但也意味着一个内容进程崩溃可能拖垮多个标签(尽管它尝试按站点分组,所以也许所有 Facebook 标签在一个进程中等)。
-
Safari:可能每个标签一个进程(或每几个标签) - 在 iOS 上,WKWebView 肯定隔离每个 webview。Safari 桌面版历史上也是每个标签分离的。不确定它们是否还隔离跨源 iframe - Apple 没有太多谈论 Spectre 缓解措施,但 Safari 至少对顶级有每个域一个进程。
进程间协调:所有引擎都必须解决类似的问题,比如如何在多进程环境中实现 alert()(它阻塞 JS) - 通常浏览器进程显示警报 UI 并暂停该脚本上下文。或如何处理 prompt/confirm,如何做模态对话框等。有细微差异(例如 Chrome 不真正阻塞 alert 的线程 - 它在渲染器中旋转嵌套运行循环等,而 Firefox 可能仍然冻结该标签的进程)。
崩溃处理:Chrome 和 Firefox 都有崩溃报告器,可以重新启动崩溃的内容进程并在标签中显示错误。Safari 的 Web Content 进程崩溃通常会在内容区域显示更简单的错误消息。
功能实现分歧
一些 Web 平台功能是引擎特定的:例如 Chrome 有实验性的 document.transition API 用于无缝 DOM 转换,它依赖于 Blink 的架构。Firefox 可能以不同方式或稍后实现某些东西。但最终,标准会收敛功能。
开发者工具:Chrome 的 DevTools 非常先进。Firefox 的 DevTools 也很好(有一些独特功能,如早期的 CSS Grid 高亮器、形状编辑器)。Safari 的 Web Inspector 很好,但在某些领域功能不够全面。这些差异对调试每个浏览器的开发者来说可能很重要。
性能权衡
历史上,Chrome 因多进程和 V8 而被称赞为更快的 JS 和整体性能。Firefox 与 Quantum 缩小了很多差距,有时在图形方面超越 Chrome(WebRender 对复杂页面可能非常快)。Safari 经常在图形和 Apple 硬件上的低功耗使用方面表现出色(他们大量优化功耗)。
内存:Chrome 以高内存使用而闻名(所有这些进程)。Firefox 尝试更保守一些。Safari 在 iOS 上出于必要(有限的 RAM)非常节省内存,他们在 WebKit 中做了很多内存优化。
外部贡献者:有趣的注意 - 这些引擎中的许多改进来自外部团队,如 Igalia(例如在 WebKit 和 Blink 中实现 CSS Grid)。因此有时功能大致同时在各处实现。
从 Web 开发者的角度来看,差异通常表现为:
-
需要在所有引擎上测试,因为一个引擎的 CSS 功能或 API 实现可能有轻微差异或错误。
-
性能可能不同(例如,特定的 JS 工作负载由于 JIT 启发式可能在一个引擎中比另一个更快)。
-
某些 API 可能在一个中不可用(Safari 通常最后实现一些新 API,如 WebRTC 或 IndexedDB 版本等,尽管它们最终会实现)。
但我们讨论的核心概念(网络 -> 解析 -> 布局 -> 绘制 -> 合成 -> JS 执行)适用于所有,只是内部方法或名称不同:
-
在 Gecko 中:解析 -> 框架树 -> 显示列表 -> WebRender 场景或层树(如果 WebRender 禁用)-> 合成。
-
在 WebKit 中:解析 -> 渲染树 -> 图形层 -> 合成(通过 CoreAnimation)。
所有都有类似的子系统(DOM、样式、布局、图形、JS 引擎、网络、进程/线程)。
了解这些有助于调试:例如,如果某些东西在 Safari 中卡顿但在 Chrome 中不卡顿,可能是 WebKit 的绘制不同。或者如果 CSS 在 Firefox 中慢,也许它触及了 Stylo 没有并行化的路径(尽管这很少见)。
总结,虽然 Chromium、Gecko 和 WebKit 有不同的实现,甚至一些不同的创新(Gecko 中的并行 CSS、WebRender GPU 等),但它们越来越多地实现相同的 Web 标准,甚至在许多方面合作。引擎的选择对平台供应商和开放 Web 多样性更重要,但作为开发者,你主要关心你的站点在任何地方都能运行。在底层,每个引擎的独特架构可能导致不同的性能配置文件或错误,这就是为什么在每个引擎中测试和使用性能诊断(如 Firefox 的性能工具与 Chrome 的)可能有洞察力。列出所有差异超出了我们的范围,但希望这给出了景观的想法:它们在高级设计上收敛(多进程、类似管道),但在特定技术解决方案上分歧。
结论和进一步阅读
我们已经走过了现代浏览器中网页的生命历程 - 从输入 URL 的那一刻,通过网络和导航、HTML 解析、样式、布局、绘制和 JavaScript 执行,一直到 GPU 在屏幕上放置像素。我们看到浏览器本质上是迷你操作系统:管理进程、线程、内存和大量复杂子系统,以确保 Web 内容快速加载并安全运行。对于 Web 开发者来说,了解这些内部机制可以揭开为什么某些最佳实践(如最小化回流或使用异步脚本)对性能很重要,或者为什么某些安全策略(如不在 iframe 中混合源)存在。
开发者的几个关键要点:
优化网络使用:更少的往返和更小的文件 = 更快的开始渲染。浏览器可以做很多(HTTP/2、缓存、预测性加载),但你仍应该利用资源提示和高效缓存等技术。网络栈是高性能的,但延迟总是性能杀手。
为效率构建你的 HTML/CSS:结构良好的 DOM 和精简的 CSS(避免非常深的树或过于复杂的选择器)可以帮助解析和样式系统。理解 CSS 和 DOM 构建计算样式,然后布局计算几何形状——重度 DOM 操作或样式更改可能触发这些重新计算。
批量 DOM 更新:避免重复的样式/布局抖动。使用 DevTools 性能面板捕获脚本何时导致许多布局或绘制。
为动画使用合成友好的 CSS:transform 或 opacity 的动画保持在主线程之外并在合成器上,产生平滑的动画。如果可能,避免动画布局绑定属性。
注意 JS 执行:虽然 JS 引擎超快,但长任务会阻塞主线程。分解长操作(这样页面保持响应),在某些情况下考虑 Web Workers 用于后台任务。另外,记住重度 JS 可能导致 GC 暂停(现在很少长,但如果内存膨胀可能发生)。
安全功能:拥抱它们——例如在适当时使用 iframe sandbox 或 rel=noopener,因为你现在知道浏览器无论如何都会隔离那些;与它合作是好的。
DevTools 是你的朋友:特别是性能和网络面板是查看浏览器确切在做什么的金矿。如果某些东西慢或卡顿,工具经常指向原因(长布局、慢绘制等)。
对于那些希望更深入探讨的人,Pavel Panchekha 和 Chris Harrelson 的《浏览器工程》(可在 browser.engineering 获取)是一个极佳的资源。
它本质上是一本免费的在线书籍,指导你构建一个简单的 Web 浏览器,以易于理解的方式涵盖网络、HTML/CSS 解析、布局等。它可以作为我们讨论的一切的更深入伴侣,通过示例巩固知识。此外,Chrome 团队的多部分系列”现代网络浏览器内部观察”提供了带图表的可读概述。V8 博客(v8.dev)和 Mozilla 的 Hacks 博客是了解引擎进展的好地方(例如新的 JIT 编译器层或 WebRender 内部)。
总之,现代浏览器是软件工程的奇迹。它们成功地抽象了所有这些复杂性,因此作为开发者,我们主要只是编写 HTML/CSS/JS 并信任浏览器处理它。然而,通过窥视底层,我们获得了帮助我们编写更高性能、更强大应用程序的洞察。我们理解为什么某些技术改善用户体验(例如避免阻塞主线程,或减少不必要的 DOM 复杂性),因为我们看到浏览器必须在底层如何工作。下次你调试网页或想知道为什么 Chrome 或 Firefox 以某种方式行为时,你将有一个浏览器内部的心理模型来指导你。
愉快构建,记住 Web 平台的深度奖励那些探索它的人 - 总有更多要学习的,以及帮助你学习的工具。
进一步阅读
-
Web 浏览器工程 - 浏览器工作原理深入探讨书籍
-
**Chromium 大学 - **免费的 Chromium 工作原理深入视频系列,包括优秀的像素的生命演讲
-
浏览器内部(Chrome 开发者博客系列) - 第 1-4 部分涵盖架构、导航流程、渲染管道和输入/控制器线程。
本文中的插图由 Susie Lu 委托制作。
