概述
HTTP 缓存的核心是 header 的 Cache-Control 属性。浏览器与服务器会通过这个 header 交涉,决定缓存的使用情况。
这个属性请求和响应都可用,请求头的 Cache-Control 多用于阻止代理(proxy)缓存(相关问题),因此我们可以重点关注响应头。
代理(proxy)是指客户端到服务器中间的可能经过的地方,有可能用于数据转发和缓存。

HTTP 缓存有两个关键字:新鲜度(Freshness),校验(Validation)
新鲜度是指缓存是否依然生效,在过期前,他就是新鲜的,过期后,则被称为 stale。
而校验是指客户端向服务器校验缓存是否依然有效。一个挺迷惑的设定,因为校验不一定是过期后的行为,根据特定的设定,校验可以发生在每次请求。
换两个更熟悉的词,那便是:
- 强缓存 ≈ freshness
- 协商缓存 ≈ validation
根据 Cache-Control 选项的不同,浏览器会使用不同的缓存策略。
Cache-Control 的可选项
完整的选项可以看这里,本文只讲一些常用选项:
Cache-Control: no-cacheCache-Control: no-storeCache-Control: publicCache-Control: privateCache-Control: must-revalidateCache-Control: max-age=<seconds>- 当你不需要缓存时,使用
no-store(而不是no-cache,不要问为什么,起名字的人就是鬼才) - 在使用
no-cache时,则会表现为:缓存该请求,每次使用缓存前都先校验,如果资源没有变化,返回 304(虽然也向服务器请求,但占用流量更少),如果资源变化,则重新下载 public缓存请求(包括代理和浏览器)private仅在浏览器缓存请求must-revalidate这个设置的出现率似乎比上面的低,在设置must-revalidate后,在缓存过期后,必须校验(而no-cache是不论是否过期)。但是疑问在于,难道不设置must-revalidate浏览器会在缓存过期的时候依然用旧的缓存?答案是,部分浏览器在请求失败时会使用旧资源,但存在must-revalidate时就不能这么做了,直接返回 504max-age=<seconds>max-age 是保持缓存新鲜的秒数,当你设置了 max-age,一般情况下浏览器就不会跟服务器校验啦,你能在开发者工具里面看到数据会直接从 disk cache 或者 memory cache 返回
说到一般情况,就肯定有特殊情况,例如:
- 如果用户按了 F5,浏览器会无视新鲜度发起校验,但是!如果 Cache-Control 又同时设置了
immutable,浏览器又会用回缓存,是的,浏览器缓存这玩意就是这么相互缠绕、错综复杂…… - 如果用户按的是 Ctrl + F5,那就真的啥都没用了,浏览器会自动在请求头添加
no-cache,天王老子来了都要到服务器拿最新数据
说了这么多的选项,但是如果服务器设了 public 但是没设 max-age,甚至根本没有设置任何 Cache-Control 怎么办呢?
答案是浏览器会根据 last-modified 推测请求的新鲜度,自动缓存(相关问题),这被称为 Heuristic Caching(启发式缓存)。
上面说的只是特例的其中之一,Cache-Control 的多种属性组合使用会产生很多意外的效果,不同浏览器存在不同的实现,但是应该大同小异。本文不会详细讲组合效果和在各个浏览器的表现。
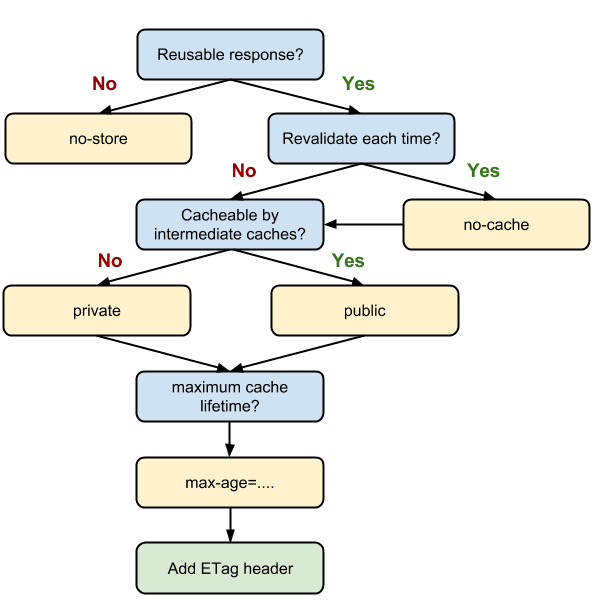
借助上图,可以根据你的需求简单判断 Cache-Control 的设置,来源于:https://web.dev/http-cache/
新鲜度
除了 max-age,我们也能使用 Expires 判断资源新鲜度。
一个 Expires 属性可能长这样:Expires: Wed, 21 Oct 2015 07:28:00 GMT,如果当前时间超过 Expires 提供的日期,缓存被视为不新鲜。另外,在提供了 max-age 的情况下,Expires 无效。
校验
数据 stale 之后,浏览器发起校验。而 ETag 是校验资源是否需要重新获取的关键属性。
ETag: "33a64df551425fcc55e4d42a148795d9f25f89d4"ETag: W/"0815"ETag 属性是请求指向的资源的指纹,如果资源被修改,那么 ETag 就一定会变化,所以在校验时可以通过 ETag 判断资源是否过期。
要问校验是如何操作的,就要说到以下两个属性:
响应头存在 ETag 时,在下次校验该资源时,请求头就会自动带上 If-None-Match 属性,值为该资源的 Etag。
当不存在 ETag 时,请求头可能带上 If-Modified-Since,值为响应头的 Last-Modified 属性的值。这样可以通过最后修改时间校验资源是否更新过。
再顺便重复一遍,校验是要请求服务器的,校验后如果得知资源与上次请求相同,会返回 304 Not Modified,不返回资源内容本身,节省了流量;校验后发现资源已经被修改过时,就是正常的 200,资源重新下载。
实际情况
下面随便打开一个网页看看 HTTP 缓存的实际效果。
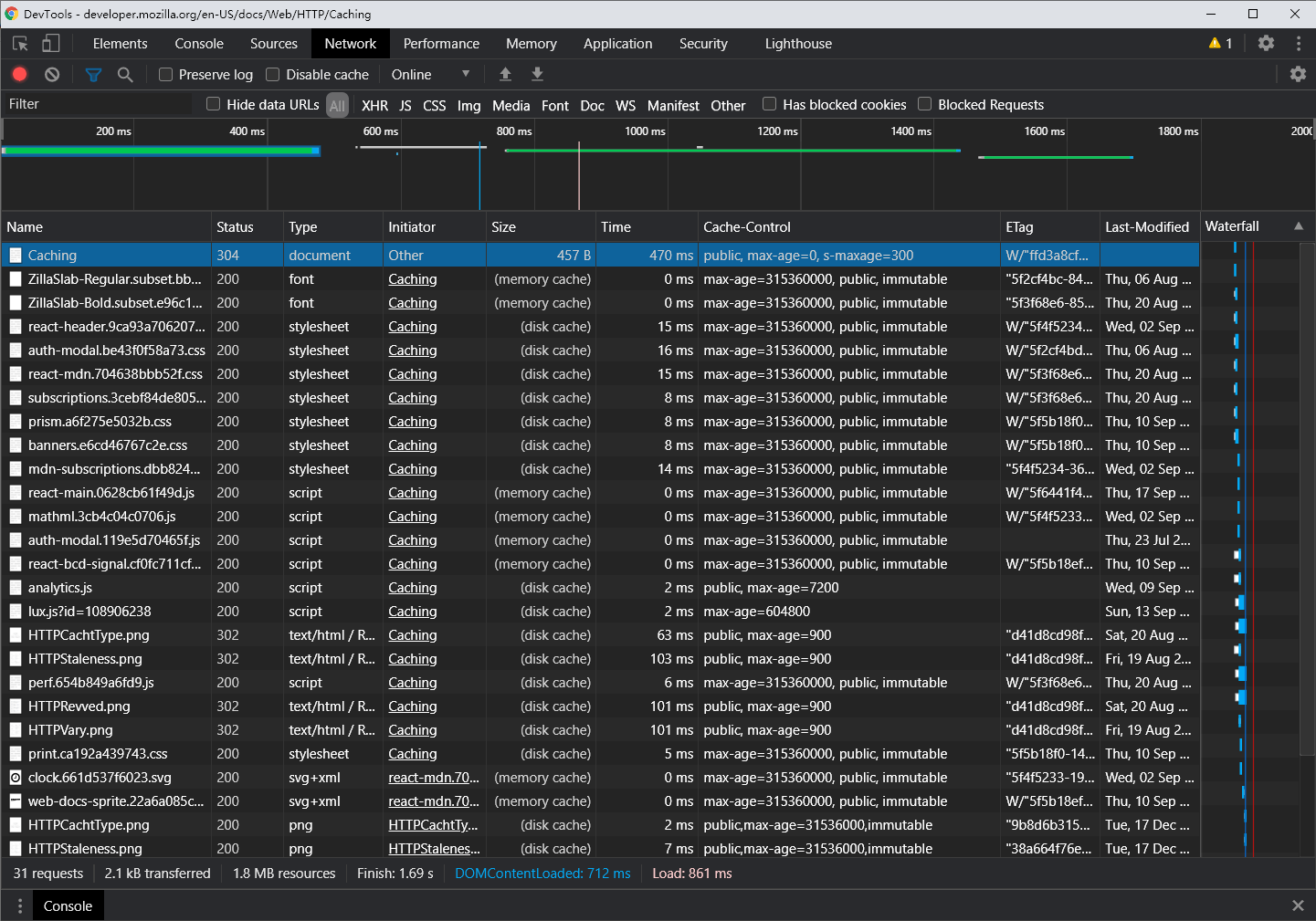
第一条是网页文件请求,cache-control 设置为 public, max-age=0, s-maxage=300,说明了:
- public:文件可以被代理和浏览器缓存,
- max-age=0:浏览器在 0 秒后把资源判断为过期,其实就等于
no-cache,每次使用缓存前都先校验 - s-maxage=300:代理在 300 秒后把资源判断为过期
同时看到请求状态是 304,说明校验结果是资源新鲜,可使用缓存的内容。
接着看后面一大堆请求的 Size 列都标明 disk cache 或者 memory cache,这种就是完全没有检验直接使用缓存的情况。
它们的 max-age 都是一个较大的数字甚至是 immutable(意味着永远不会过期),并且没有 no-cache。
总结
总结起来不复杂:
- 当数据新鲜时,浏览器直接使用缓存
- 当数据 stale 时,浏览器向服务器发起校验,如果资源没有变化,返回 304,如果资源变化,则下载新资源
- F5 刷新时,会无视新鲜度发起校验,但是如果 Cache-Control 又同时设置了
immutable,浏览器又会用回缓存 - Ctrl + F5 刷新时,浏览器会自动在请求头添加
no-cache,总能拿到服务器最新数据
实践
对于前端开发人员,可能会遇到的问题是版本发布后刷新但依然是旧数据的问题,重点有两个:
第一,进入页面的请求本身不缓存或每次都校验,这样入口文件的依赖就是最新的。
第二,依赖的 JavaScript 和 css 文件设置长时间的 max-age,且不校验。但是不校验怎么更新版本呢?我们可以在文件名上带上哈希值(一般依赖内容由构建工具生成,不用手动地加哈希值),这样每次版本更新后,请求的都不是同一个文件,自然会重新获取。
通过上面两个设置的配合,就能同时实现长时间缓存和版本更新。
附录
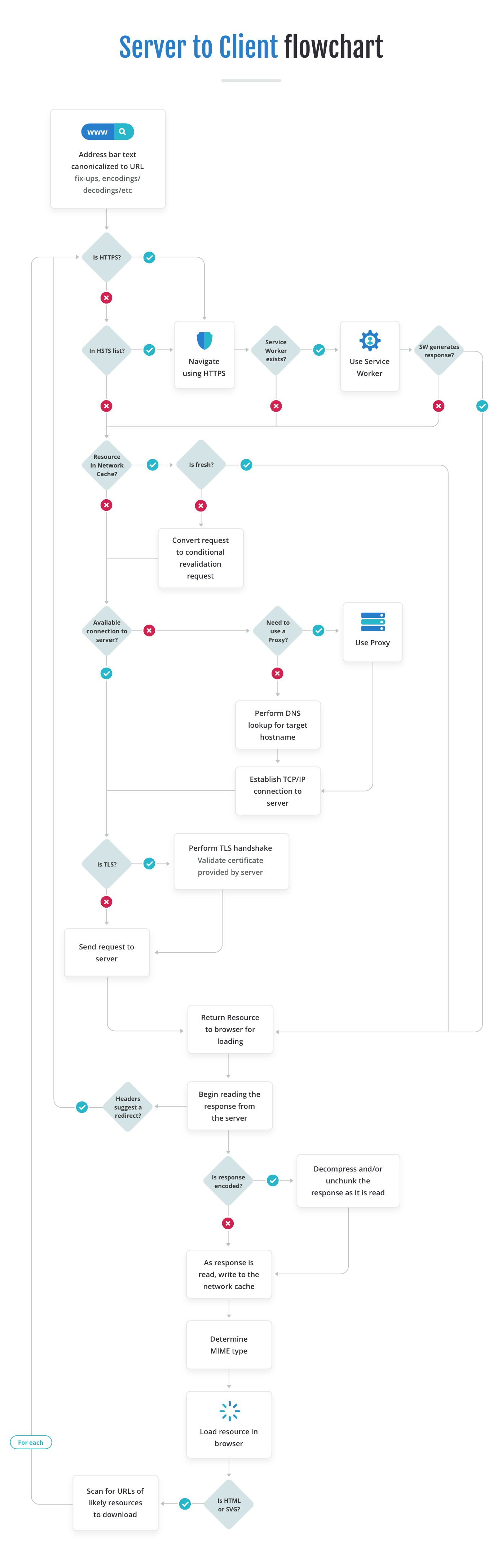
上图来源于 Server to Client 这篇文章,看不清请右键新建页面浏览图片。
此图清晰说明了客户端输入地址后,整个获取资源的流程。值得注意的是,Service Worker 在此占有一席之地,说明我们可以借助他的力量代替传统的缓存操作,不过相关问题,就留到下次再做研究了。